Deep Mutual Learning
论文地址: https://arxiv.org/abs/1706.00384
论文简介
该论文探讨了一种与模型蒸馏(model distillation)相关却不同的模型---即相互学习(mutual learning)。 蒸馏从一个强大的大型预训练教师网络开始,并向未经训练的小型学生网络进行单向知识转移。 相反,在相互学习中,我们从一群未经训练的学生网络开始,他们同时学习一起解决任务。 具体来说,每个学生网络都有两个的损失函数:一种传统的监督性损失函数,以及一种模仿性的损失函数(mimicry loss),使每个学生的后验概率分布与其他学生的类别概率保持一致。
通过这种方式进行训练,结果表明,在这种基于同伴教学(peer-teaching)的情景中,每个学生的学习都比在传统的监督学习方案中单独学习要好得多。 此外,以这种方式训练的学生网络比来自更大的预训练教师的传统蒸馏训练的学生网络获得更好的结果。论文实验表明,各种网络架构可以从相互学习中受益,并在CIFAR-100识别和Market-1501 ReID 数据集上获得令人信服的结果。
模型设计
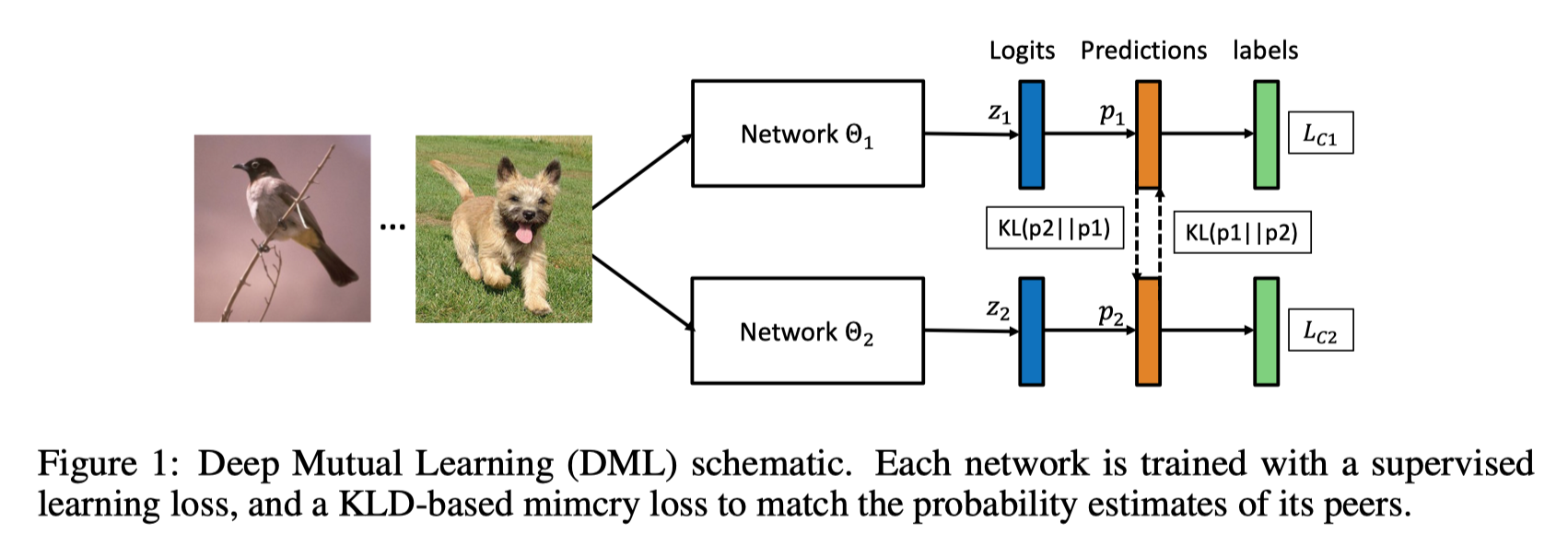 

损失函数
| 损失函数 | 函数设计 |
|---|---|
| 传统监督损失函数 | softmax + 交叉熵损失函数 |
| 模仿性的损失函数 | softmax + KL散度函数 |
[两个网络]
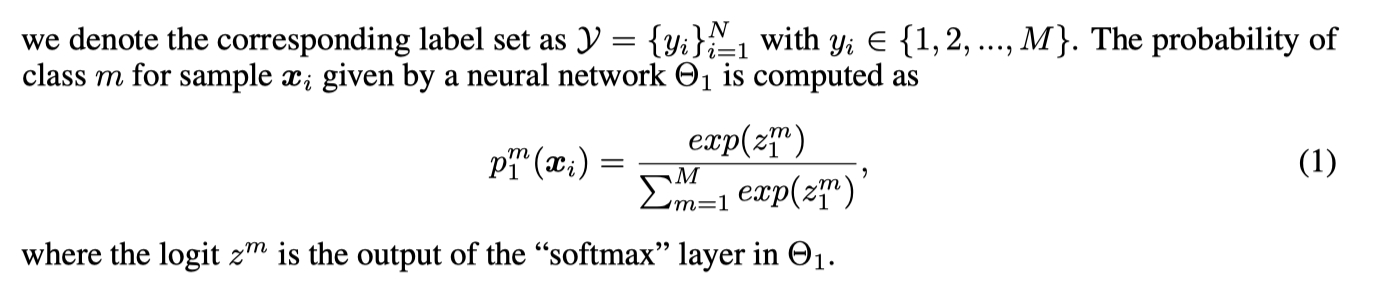 

 

[多个网络]

实验结果
实验网络
 

Cifar-100 实验
[实验设置]
| paras | values |
|---|---|
| optimizer | SGD with Nesterov |
| base lr | 0.1 |
| momentum | 0.9 |
| batch size | 64 |
| epoch | 200 |
| note | The learning rate dropped by 0.1 every 60 epochs |
[实验结果]
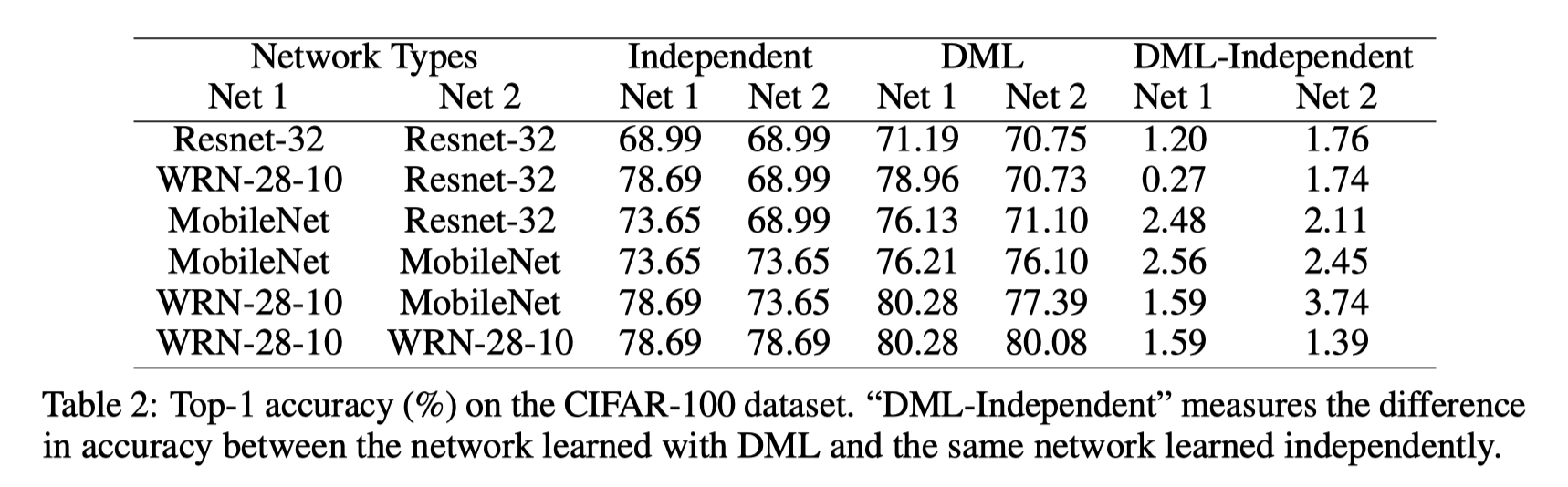 

[实验结论]
- 与独立学习相比, ResNet-32,MobileNet 和 WRN-28-10各种不同网络都在DML提高了性能。
- 容量较小的网络(ResNet-32和MobileNet)通常可以从DML获取更大的提升。
- 虽然WRN-28-10是一个比MobileNet或ResNet-32大得多的网络,但它仍然受益于与较小的网络一起训练。
- 与独立学习相比,使用DML训练一组大型网络(WRN-28-10)仍然是有益的。 因此,与模式蒸馏的传统智慧相反,我们看到一个大型的预训练的教师网络不是必不可少的.
Market-1501 实验结果
[实验设置]
每个MobileNet相互学习DML都以双网络方式中进行训练,并报告两个网络的平均性能
| paras | values |
|---|---|
| optimizer | Adam |
| β1/β2 | 0.5/0.999 |
| base lr | 0.0002 |
| momentum | 0.9 |
| batch size | 16 |
| iterations | 100,000 |
[实验结果]
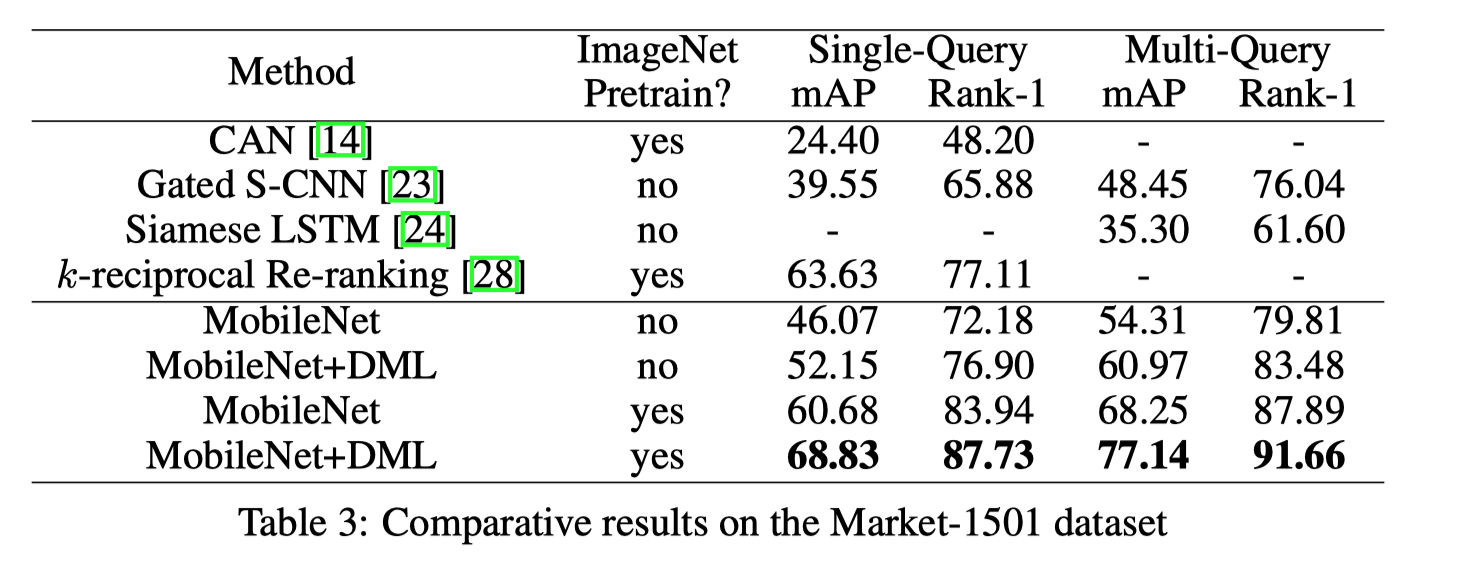 

[实验结论]
可以看到,与独立学习相比, 无论是否在ImageNet上进行预训练,DML极大地提高了MobileNet的性能。还可以看出,用两个MobileNets训练的所提出的DML方法的性能显着优于先前的最先进的深度学习方法。
与模型蒸馏比较
[实验结果]
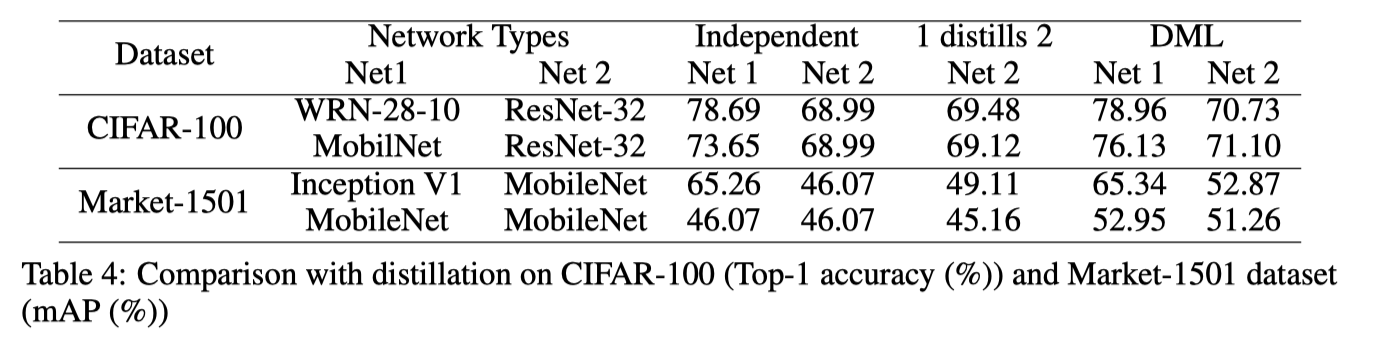 

[实验结论]
Table4 将DML与模型蒸馏进行了比较,其中教师网络(Net1)经过预先训练,并为学生网络(Net2)提供固定的后验概率目标。
- 正如预期的那样,与独立学习相比,来自强大的预训练教师网络的常规蒸馏方法确实提高了学生网络的表现(Net1蒸馏Net2)
- 与蒸馏相比,DML将两个网络一起训练, 两个网络都得到了改进。这意味着在相互学习的过程中,通过与先验未经训练的学生的互动,教师角色的网络实际上变得比预先训练的教师更好。
相互学习的网络与性能联系
[实验设置]
之前实验研究以2名学生队列为例。在这个实验中,论文研究了DML如何与队列中的更多学生进行互动。图2(a)显示了Market-1501上的结果,其中DML训练增加了MobileNets的群组大小。图中显示了平均mAP以及标准偏差。
[实验结果]
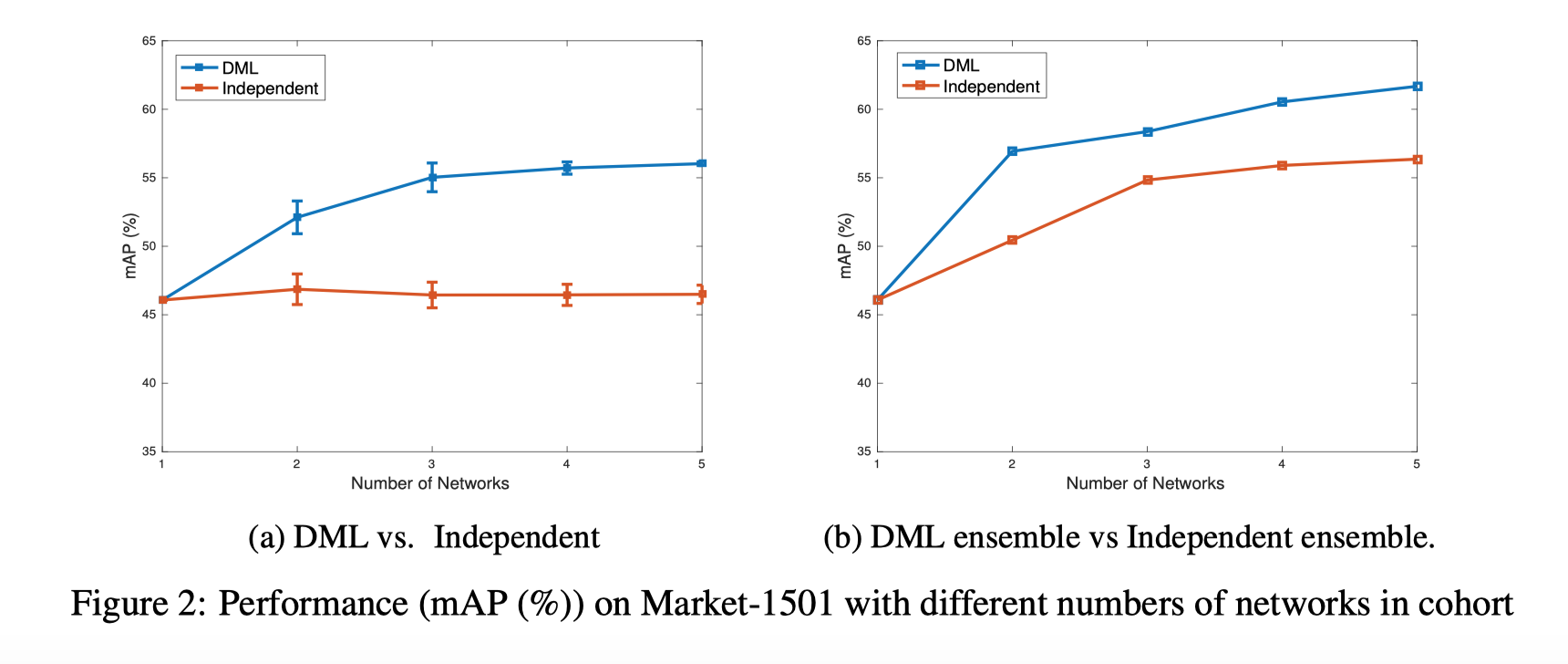 

[实验结论]
从图2(a)可以看出,平均单一网络的mAP性能随着DML队列中的网络数量的增加而增加。这表明,与越来越多的同龄人一起学习时,学生的泛化能力得到提高。从标准偏差中我们也可以看到,随着DML网络数量的增加,结果越来越稳定。
训练多个网络时的一种常用技术是将它们组合为一个整体并进行组合预测。在图2(b)中,我们使用与图2(a)相同的模型,但基于整体进行预测, 在整体上(基于所有成员的连锁特征进行匹配)而不是报告每个人的平均预测。从结果我们可以看出,集合预测优于预期的各个网络预测(图2 (b)vs(a).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号