
kafka 扫盲
做过消息通知或者微服务事件的同学,或多或少对 kafka 都有一定的了解,不过有时业务繁重,难保同学们能认真的去了解 kafka 的使用,很多都是业务需要接入某个事件,就导入 sdk 包,配置一些东西,注册一个 handler 去写业务代码。
看似写代码的同学入手更快,但往往不利于同学们的成长,小公司的同学应该还能接触到 topic / group / partition 的概念,但大公司一般是使用公司二次封装的 mq-sdk,那才是完全感受不到 kafka 有趣的灵魂。这里做一个简单的扫盲,意在加深印象。

kafka 主体结构
简单介绍 kafka 相关概念:
1,producer:生产者,作为消息发送的生产端,负责消息体发送的客户端
2,broker:kafka 服务节点,负责消息体的中转、持久性,组成 kafka 的主要部分
3,consumer:消费者,作为消息接收的消费端,祖泽消息处理的业务端
4,zookeeper:分布式处理框架,kafka 多节点通过 zookeeper 提供分布式服务,保证服务集群的高可用
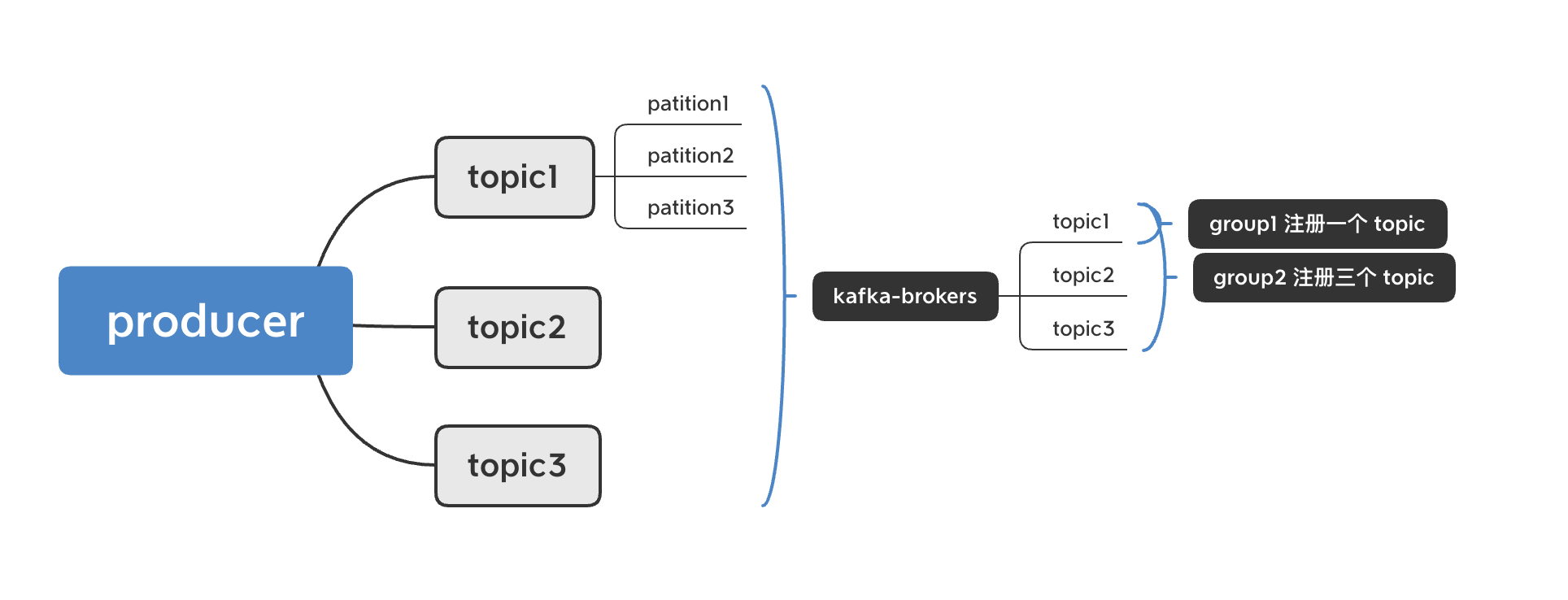
kafka 生产-消费结构
5,topic:消息分类,每条消息必须指定一个 topic,不同 topic 之间不会相互影响
6,patition:同一分类消息分区,不同分区之间不会相互影响
7,group - consumer_group:多个 consumer 为一组,相互之前不会重复消费
上面简单进行一些名词解释,下面我们简单了解一下 kafka 与业务强相关的属性
1,topic - partition:
kafka 中的任何一条消息,都有其所属的 topic 和 partition,topic 代表消息的类别,我们开发过程中,对于不同事件的消息,几乎都会指定不同的 topic,确保不同 topic 之间不会相互影响,而作为消费端,可以注册某个或多个 topic 进行消息处理,同样是不会消费到其他分类的消息。
同一 topic 不能确保其有序,但同一个 partition 下为有序队列,生产时我们可以指定一个 key 作为有序 key,对 partition 的数量进行 hash,放到队列中就可以保证在消费端是相对有序;举个列子,用户 id 1234,partition 数量 10,我们取 hash 后可以将这个用户的所有消息防到 patition4 里,这样 kafka 就可以保证这个用户的所有消息有序。保证其有序的必要条件就是同一个 partition 同时只能被同一个 consumer 消费。
2,消费模型:
传统消费队列分为两种消费模型,分别是 push(推送模型)和 pull(拉取模型)。
Push 模型由 mq 层主动推送消息到端上,这样可以消费端可以处于低消耗的被动监听状态,消息达到后唤醒线程去执行,但无法控制其消费速率,并且无法感知消费的结果,以确保消费成功;当然两者是各有利弊,没有强弱之分。kafka 使用 Pull 模型,由消费端控制消费速度,并在消费端成功消费后,反馈给 broker 并拉取新一波数据,但一定程度上会造成 kafka 的消息堆积,
3,高可用存储模型:
kafka 不同 broker 提供备份存储,确保数据一旦到达 kafka-serve 端,哪怕宕机也可使用备份继续提供服务。具体的备份模型之前看过一张图,

这里简单给出一张备份图,但实际 kafka 的备份是通过 zookeeper 可配。
内部的存储结构为单独 partition 存储在数据节点上,以日志的形态去落盘,由于其有序性,大大提升了 kafka 的生产速度,当然仅仅有序落盘是远远不够支持百万级并发的程度,下个环节我们继续说,回到这个话题
如果某个节点发生宕机后,zookerper 就会控制集群触发 kafka 集群的重新选举,这整个过程称为 rebalance,在这个过程中,可以理解为 Kafka 的消费对外是停止提供服务的
4,生产模型:
同步生产:生产端每次调用,都需要确保消息同步到 broker 并返回,这种模式下确保了消息的强同步,但相对性能是远远不足的,一般一次调用的耗时在 50-100 ms(低压),如果在高峰期,延迟会达到 100-300 ms 之间
异步生产:生产端调用接口无感知,不确保生产落到 broker 上,可以通过注册失败回调函数来重试,确保消息的不丢失,一定程度上降低了生产端的延迟,但不能避免服务端的压力;所以在生产端有一组 batch 的概念,可以有效提高生产的吞吐量,真正达到百万级并发的级别。这里也需要注意一个点,在服务退出的时候,由于 kafka 的 batch 没有填充满,且没有到达发送的时间,会导致 batch 的消息没有真正到达 broker,所以需要去手动去进行一次 flush / close,防止生产数据的丢失
5,rebalance:
kafka 在选举、consumer 加入都会直接触发 rebalance 状态,而 kafka 为了保证消费的可靠性、一致性,这个阶段是无法进行进行消费的,而且在服务集群重启过程中,由于单节点、分批重启,会导致整个 kafka 集群的 rebalance 会发生很多次,并一定概率会发生抖动直到所有节点重启成功后慢慢趋于平稳,这个点就是 kafka 的一个比较严重的问题,短时间的停止消费可以认为 kafka 的不可用性。
6,offset 和重复消费:
消费端通过 pul 的方式去拉取消息时,是通过 consumer-group 对于 topic-partition 记录在 zookeeper 的 offset 标记来确保不会重复消费,但另一问题,假设在消费过程中,我们服务发生了重启,而 offset 是没有通过接口调用去反馈,会导致当前消费不符合原子性,即一定程度存在重复消费的问题。这里我们可以通过消费端的 close 并等待本地消费完成作为安全重启的标准,一定程度上可以确保不会出现重复消费的情况。
以上作为 kafka 扫盲知识点,不涉及 kafka-server 的实现(选举步骤、一致性算法,网络io),仅限于 kafka-producer 和 kafka-consumer 端的安全使用。

