
mysql 松散索引与紧凑索引扫描(引入数据结构)
这一篇文章本来应该是放在 mysql 高性能日记中的,并且其优化程度并不高,但考虑到其特殊性和原理(索引结构也在这里稍微讲一下)
一,mysql 索引结构 (B、B+树)
要问到 mysql 的索引用到什么数据结构,我相信大部分都能回答出来,没错,就是 B+ 树。那再问为什么要用 B+ 树呢,与红黑树,hash 表又分别有什么区别呢,问到这里可能就难住了一些没思考过的轻度玩家了。这里简单描述一下
B 树与红黑树的区别,有数据结构基础的同学应该可以讲出来,红黑树是*衡二叉树的一个变种,利用红黑树的 5 个特征保证其*乎*衡,记住,红黑树降低的左转右转的递归向上,但其并不是绝对*衡,但非极端情况下,我们也可以说红黑树的查询和插入都是 log2n 的时间复杂度;而 B 树可以理解为*衡 n 插树,每个数的节点并不是一个值,而是一个数组,每两个数值之间指向一个在两者之间范围的新节点,这里可以看到对于相同的数据量,B 树的高度远远小于,根据官方给出一般索引的高度不会超过 5 的高度计算,3亿的数据量仅需要每个节点 50 个数据,mysql 在每个节点的遍历也是用最快的二分查找,所以查询一个 3亿 数据量的时间复杂度仅为 5log250,算下来几乎为常数级
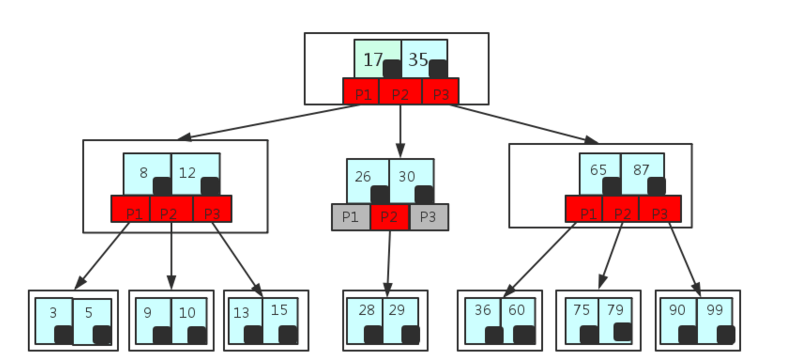
B 树与 hash 表的区别,hash 的查询会比 B 树更快一些,好的 hash 表甚至可以达到 1-5 次查询得到结果,但与已经是常数级的 B 树相比,并没有太大的一个优化,但 hash 的插入却很容易产生 hash 冲突,现有解决 hash 冲突的方法无不是需要耗费大量时间进行重新 hash,相较微量的查询优化,写的效率过低导致 mysql 不可能使用 hash 表作为索引结构。
mysql 的索引结构其实本质是 B 树的一个变种结构 -- B+ 树,相较 B 树,B+ 树更适用于文件型索引,其每个非叶子节点存储的只是用于索引排序的辅助数值,而真正的数据都放在叶子节点,对于 mysql 这种不仅仅存单纯的排序值,而是关系型数据的 db,当然是 B+ 树更适合作为索引结构,当然还有一个小的优化点是子节点之间是有指针连接的,加快了范围查找的速度。

二,复合索引结构
对于主键索引,肯定索引结构是按一个主键的顺序组合的 B 树,但对于一个含有两个列的复合索引,它的树状结构是什么样呢?
对于复合索引 Index(A,B),B 树的排序是按 A 列的数值为第一要素,B 列的数值为第二要素进行排序,这也就是为什么我们查询语句时,条件语句必须保证最左原则才可以利用到索引
这里引入一些题外话,聚簇索引(Innodb)和非聚簇索引(myisam),因为讲到索引结构,这里引入这个话题,也是 mysql 中比较常用的两大引擎的一个区别,聚簇索引的索引的叶节点存放的直接是数据的叶节点,当使用辅助(符合)索引查询时,其叶子节点存放的是主键的值,所以通过符合索引查找非覆盖索引数据时,都会进行两次查询,并且查询主键的速度没有 myisam 的速度快;非聚簇索引指索引的叶节点存放的是数据的页数据指针,辅助索引存的同样是指针。两者各有千秋,不能说哪个好哪个坏,按业务自身选择即可
回到正题,那对于复合索引的查询是如何的过程,那如果真的想要只查 B 又想用到索引,该如何使用呢?引入我们的第三个话题
三,紧凑索引与松散索引
如果不遵守最左原则,where b = xxx,就会使用紧凑索引遍历的方式,进行全表扫表。而我们如果真的有些情况,需要查出符合 B 条件但对 A 不进行限制的情况,应该如何处理,可能有些同学会新开一个独立索引仅包含 B 列,这样虽然能达到我们的目的,但难免有些多余。mysql 也是也能很好的进行跳跃松散索引扫描,只是 mysql 优化器无法自动进行,必须在查询语句中进行必要的声明。 select * from xxx where B = xxx group by A; 添加 group by 字段后,会先根据 A 索引分组后,会在每个 A 的范围内使用索引进行快速查询定位所需要的 B 列,这就叫做松散索引扫描,比新建一个索引的效率会慢 A 的 distinct 倍,但省去了新索引的消耗。

--业务程序员

