深度学习模型建立的整体流程和框架
深度学习模型建立的整体流程和框架
框架图如下,纵向是建立模型的主要流程,是一个简化且宏观的概念,横向是针对具体模块的延展。
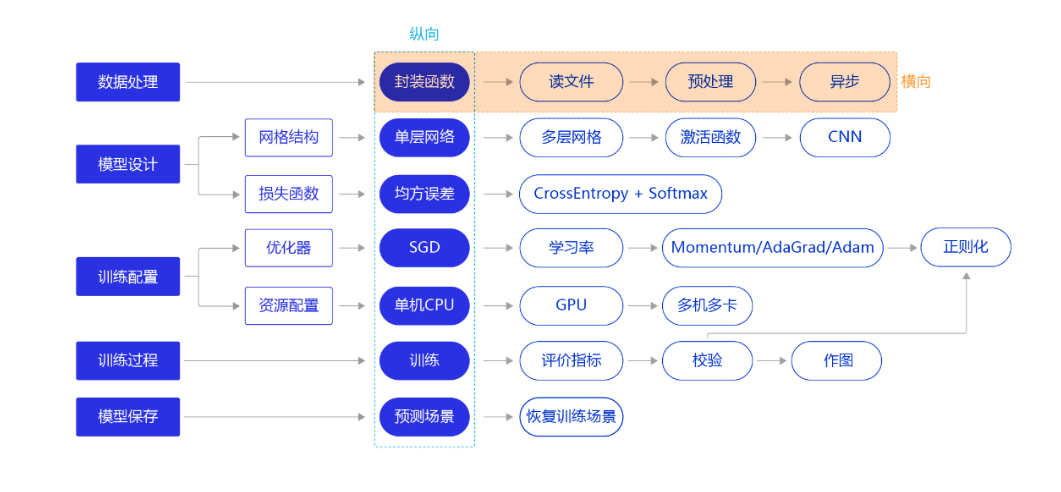
数据处理
数据处理一般涉及到一下五个环节:
- 读入数据
- 划分数据集
- 生成批次数据
- 训练样本集乱序
- 校验数据有效性
模型设计
网络结构
网络结构指的就是通常所说的神经网络算法中的网络框架,如全连接神经网络,卷积神经网络以及循环神经网络等,不同的网络结构通常有各自最优的处理场景,所以在处理具体问题时选择合适的网络结构是十分重要的。
损失函数
损失函数是模型优化的目标,用于在众多的参数取值中,识别出最优的参数。损失函数的计算在训练过程的代码中,每一轮模型训练的过程都相同,分如下三步:
- 先根据输入特征数据正向计算预测输出
- 再根据预测值和真实值计算损失(误差)
- 最后根据损失反向传播梯度并更新参数
损失函数也有很多种,如均方差,交叉熵等,不同的深度学习任务需要有各自适宜的损失函数,具体可以参考该博客机器学习-损失函数
训练配置
优化算法
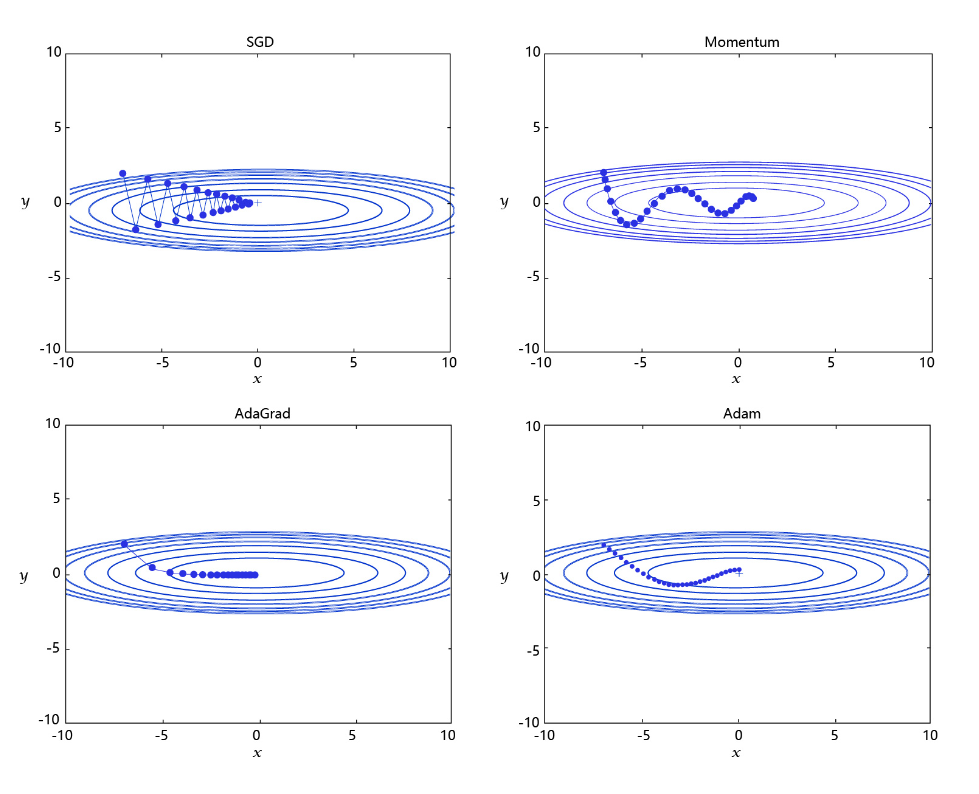
优化算法用来确定参数更新的方式以及快慢,常用的优化算法有如下四个:
- 随机梯度下降(SGD):随机梯度下降算法,每次训练少量数据,抽样偏差导致参数收敛过程中震荡。
- 动量(Momentum):引入物理“动量”的概念,累积速度,减少震荡,使参数更新的方向更稳定。
- AdaGrad: 根据不同参数距离最优解的远近,动态调整学习率。学习率逐渐下降,依据各参数变化大小调整学习率。
- Adam: 由于动量和自适应学习率两个优化思路是正交的,因此可以将两个思路结合起来,这就是当前广泛应用的算法。
下面是不同学习率优化算法的示意图:
设置学习率
学习率代表参数更新幅度的大小,即步长。当学习率最优时,模型的有效容量最大,最终能达到的效果最好。学习率和深度学习任务类型有关,合适的学习率往往需要大量的实验和调参经验。探索学习率最优值时需要注意如下两点:
- 学习率不是越小越好。学习率越小,损失函数的变化速度越慢,意味着我们需要花费更长的时间进行收敛,如 图2 左图所示。
- 学习率不是越大越好。只根据总样本集中的一个批次计算梯度,抽样误差会导致计算出的梯度不是全局最优的方向,且存在波动。在接近最优解时,过大的学习率会导致参数在最优解附近震荡,损失难以收敛,
深度学习其他知识点
模型优化
从上述流程图可以看出,深度学习模型的可以从数据处理、网络结构、损失函数、优化器和资源配置等五个方面进行模型的整体优化,选择最合适的就是最好的。
卷积神经网络尺寸的计算
卷积神经网络(CNN)张量(图像)的尺寸和参数计算(深度学习)
参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号