【Luogu P3375】字符串匹配KMP算法模板
- 模式串:即题目中的S2所代表的意义
- 文本串:即题目中的S1所代表的意义
对于字符串匹配,有一种很显然的朴素算法:在S1中枚举起点一位一位匹配,失配之后起点往后移动一位,从头开始进行匹配。
这种算法的时间复杂度几乎达到了\(O(nm)\),显然是不能接受的。
这种做法的缺点在于做了很多无用的匹配,并且每一次都从头开始匹配,完全忽略上一次匹配的信息。
而KMP算法就利用了上一次匹配的信息,减少匹配次数,时间复杂度仅有\(O(n)\)
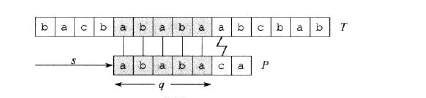
(图片来自算法导论)
观察这样一张图。在第六位失配之后,按照朴素算法,我们把模式串后移一位,从头开始匹配。事实上后移一位的匹配根本不可能成功,根据上一次匹配得到的信息,因为文本串(灰色部分)中的第二位能够与模式串的第二位匹配,所以不可能与第一位匹配。而文本串(灰色部分)第三四五位恰好与模式串的第一二三位匹配,所以我们可以直接把模式串后移两位,重新开始匹配。
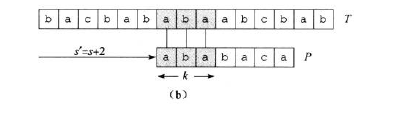
(图片来自算法导论)
如上图所示,这样可以减少很多不必要的匹配。
那么我们怎么才能知道让模式串偏移多少才合适呢?
下文的j是在模式串中的指针,j及其以前的字符是已经匹配的。
假设字符串在第j位失配,我们要找到一个尽可能长的长度\(L\),使\(S2[1..L]\)与\(S2[j-L,j]\)完全匹配(L<j),这样我们就可以在可以直接令\(j=L\),跳过前面L个的字符,因为他们绝对是匹配的。
结合代码及注释进行透彻的理解:(从KMP函数开始看更便于理解)
#include<cstdio>
#include<iostream>
using namespace std;
string s1,s2;
int nxt[1000005];
void Pre_do()
{
int len=s2.size();
nxt[0]=-1;//-1意味着从头开始匹配
for (int i=1,j=-1;i<len;i++)//注意i从1开始
{
while (j>=0&&s2[j+1]!=s2[i]) j=nxt[j];//假设不能匹配就跳过去。
//j一定小于i,所以此时的nxt[j]一定已经被记录了
if (s2[j+1]==s2[i]) j++;//匹配了就增加匹配长度
nxt[i]=j;//记录
}
}
int KMP()
{
int ret=0,len1=s1.size(),len2=s2.size();
for (int i=0,j=-1;i<len1;i++)
{
while (j>=0&&s2[j+1]!=s1[i]) j=nxt[j];//假设不能匹配就跳过去。
if (s2[j+1]==s1[i]) j++;//匹配了就增加匹配长度
if (j==len2-1) //匹配成功
{
ret++;
j=nxt[j];
printf("%d\n",i-len2+2);
}
}
return ret;
}
int main()
{
cin>>s1>>s2;
Pre_do();//预处理,求出每个位置失配后应该跳到哪个位置
KMP();
int len2=s2.size();
for (int i=0;i<len2;i++) printf("%d ",nxt[i]+1);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号