OpenCV基础知识介绍
1、图像与矩阵
一般来说,图像是一个标准的矩形,有着宽度(width)和高度(height)。而矩阵有着行(row)和列(column),矩阵的操作在数学和计算机中的处理都很常见且成熟,于是很自然的就把图像作为一个矩阵,把对图像的操作转换成对矩阵的操作,实际上所有的图像处理工具都是这么做的。计算机视觉中的图像是数字设备捕获到物理世界的表象。图像只是存储在矩阵格式中的数字序列。每个数字是一个考虑的波长(例如RGB图像中的红、绿、蓝)或波长范围(对全色设备而言,如红外光谱仪)的光强衡量。图像中的每个点称为像素,每个像素可以存储一个或多个值。这取决与它的灰度。这些值存储只有一个值,例如0或者1.灰度级尺寸可以存储一个值,彩色图像可以存储3个值。

例如,在上图中,您可以看到汽车的镜子只不过是一个包含像素点的所有强度值的矩阵。我们如何获得和存储像素值可能根据我们的需要而变化,但最终计算机世界中的所有图像可以简化为数值矩阵和描述矩阵本身的其他信息。OpenCV是一个计算机视觉库,其主要重点是处理和操作这些信息。因此,您需要熟悉的第一件事是OpenCV如何存储和处理图像。
2、opencv的mat类
opencv最初是Intel在俄罗斯的团队实现的,而在后期Intel对opencv的支持力度慢慢变小。在08年,美国一家机器人公司Willow Garage开始大力支持opencv,在得到支持后opencv更新速度明显加快,加入了很多新特性。在opencv1.x时代,数据类型为IplImage,在使用这种数据类型时,考虑内存管理称为众多开发者的噩梦。在进入到opencv2.x时代,一种新的数据类型Mat被定义,将开发者极大的解脱出来。所以在接下来的教程中,都会使用Mat类,而在看到IplImage类数据时也不要感到奇怪。
Mat类有两种基本的数据结构组成,一种是矩阵头(包括矩阵尺寸、存储方法、存储路径等信息),另一个是指向包含像素值的矩阵的指针(矩阵维度取决于其存储方法)。矩阵头的尺寸是个常数,但是矩阵自身的尺寸根据图像不同而不同。Mat类的定义有很多行,下面列出来一些关键属性如下所示:
class CV_EXPORTS Mat
{
public:
//......很多函数定义,在此省略
...
/*flag参数包含许多关于矩阵的信息,如:
Mat的标识
数据是否连续
深度
通道数目
*/
int flags;
int dims; //矩阵的维数,取值应该大于或等于2
int rows,cols; //矩阵的行列数
uchar* data; //指向数据的指针
int* refcount; //指向引用计数的指针,如果数据由用户分配则为NULL
//......其他的一些函数
};
可以把Mat看作是一个通用的矩阵类,可以通过Mat中诸多的函数来创建和操作多维矩阵。有很多种方法可以创建一个Mat对象。
Mat类提供了一系列的构造函数,可以根据需求很方便的创建Mat对象,其部分构造方法如下:
Mat::Mat() //无参数构造方法 /*创建行数为rows,列数为cols,类型为type的图像*/ Mat::Mat(int rows, int cols, int type) /*创建大小为size,类型为type的图像*/ Mat::Mat(Size size, int type) /*创建行数为rows,列数为cols,类型为type的图像 并将所有元素初始化为s*/ Mat::Mat(int rows, int cols, int type, const Scalar& s) ex:Mat(3,2,CV_8UC1, Scalar(0)) //三行两列所有元素为0的一个矩阵 /*创建大小为size,类型为type,初始元素为s*/ Mat::Mat(Size size, int type, const Scalar& s) /*将m赋值给新创建的对象*/ Mat::Mat(const Mat& m) //此处不会发生数据赋值,而是两个对象共用数据 /*创建行数为rows,列数为cols,类型为type的图像 此构造函数不创建图像数据所需内存而是直接使用data所指内存 图像的步长由step指定*/ Mat::Mat(int rows, int cols, int type, void* data, size_t step = AUTO_STEP) Mat::Mat(Size size, int type, void* data, size_t step = AUTO_STEP) //同上 /*创建新的图像为m数据的一部分,其具体的范围由rowRange和colRange指定 此构造函数也不进行图像数据的复制操作,与m共用数据*/ Mat::Mat(const Mat& m, const Range& rowRange, const Range& colRange) /*创建新的矩阵为m的一部分,具体的范围由roi指定 此构造函数同样不进行数据的复制操作与m共用数据*/ Mat::Mat(const Mat& m, const Rect& roi)
在构造函数中很多都涉及到type,type可以是CV_8UC1, CV_8UC3, …,CV_64FC4等。这些type中的8U表示8位无符号整数(unsigned int), 16S表示16位有符号整数,64F表示64位浮点数即double类型,C表示channel表示图像通道,C后面的数字表示通道数。如C1表示单通道图像,C4表示4通道图像,以此类推。如果需要更多的通道数,需要使用宏CV_8UC(n)重定义,其中n是需要的通道数。如
Mat M(3, 2, CV_8UC(5)); //创建3行2列通道为5的图像
下面通过一个实例进行理解:
#include "stdafx.h"
#include <iostream>
#include <opencv2/core.hpp>
#include <opencv2/highgui.hpp>
using namespace std;
using namespace cv;
int main()
{
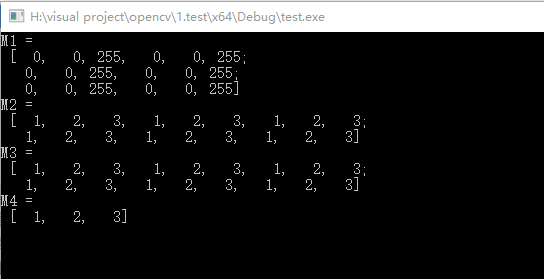
Mat M1(3, 2, CV_8UC3, Scalar(0, 0, 255));
cout << "M1 = " << endl << " " << M1 << endl;
Mat M2(Size(3, 2), CV_8UC3, Scalar(1, 2, 3));
cout << "M2 = " << endl << " " << M2 << endl;
Mat M3(M2);
cout << "M3 = " << endl << " " << M3 << endl;
Mat M4(M2, Range(1, 2), Range(1, 2));
cout << "M4 = " << endl << " " << M4 << endl;
waitKey(0);
return 0;
}
运行结果如下:
也可以使用create()函数创建对象。如果create()函数指定的参数与图像之前的参数相同,则不进行实质的内存申请操作,如果参数不同,则减少原始数据内存的索引并重新申请内存。使用方法如下所示:
#include "stdafx.h"
#include <iostream>
#include <opencv2/core.hpp>
#include <opencv2/highgui.hpp>
using namespace std;
using namespace cv;
int main()
{
Mat M1;
M1.create(4, 4, CV_8UC(2));
cout << "M1 = " << endl << " " << M1 << endl << endl;
waitKey(0);
return 0;
}
运行结果如下:
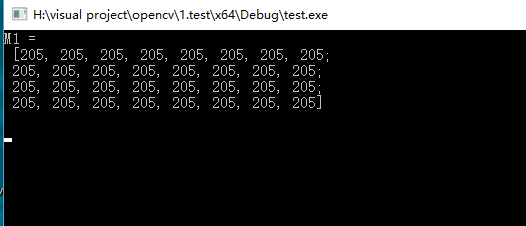
**值得注意的是使用create()函数无法初始化Mat类。
opencv也可以使用Matlab的风格创建函数如:zeros(),ones()和eyes()。这些方法使得代码非常简洁,使用也非常方便。在使用这些函数时需要指定图像的大小和类型。
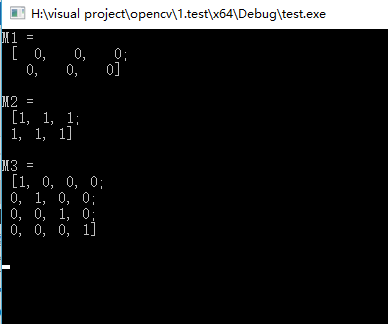
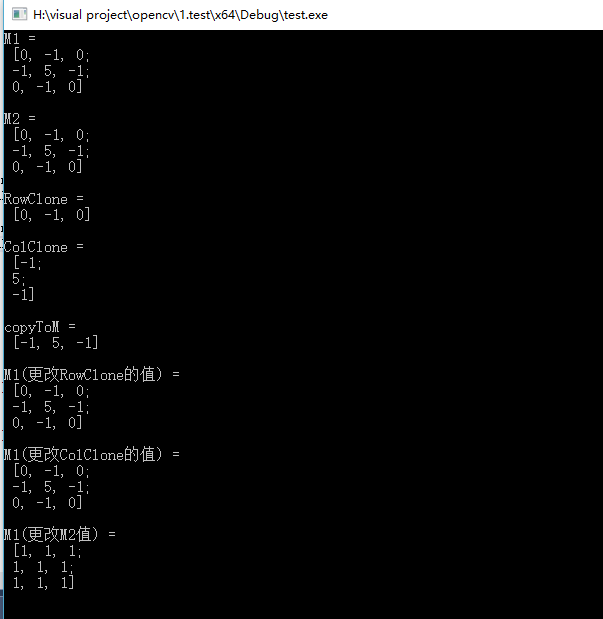
在已有Mat类的基础上创建一个Mat类,即新创建的类是已有Mat类的某一行或某一列,可以使用clone()或copyTo(),这样的构造方式不是以数据共享方式存在。可以利用setTo()函数更改矩阵的值进行验证,方法如下:
程序中M4.row(0)就是指的M4的第一行,其它类似。必须值得注意的是:在本篇介绍中工较少了clone()、copyTo()、和”=”三种实现矩阵赋值的方式。其中”=”是使用重载的方式将矩阵值赋值给新的矩阵,而这种方式下,被赋值的矩阵和赋值矩阵之间共享空间,改变任何一个矩阵的值会影响到另外一个矩阵。而clone()和copyTo()两种方法在赋值后,两个矩阵的存储空间是独立的,不存在共享空间的情况。
运行结果如下
opencv中还支持其他的格式化输入与输出
#include "stdafx.h"
#include <iostream>
#include <opencv2/core.hpp>
#include <opencv2/highgui.hpp>
using namespace std;
using namespace cv;
int main()
{
//使用函数randu()生成随机数,随机数范围为0-255
Mat R = Mat(3, 2, CV_8UC3);
randu(R, Scalar::all(0), Scalar::all(255));
//以默认格式输出
cout << "R (default) = " << endl << R << endl << endl;
//以Python格式输出
cout << "R (python) = " << endl << format(R, Formatter::FMT_PYTHON) << endl << endl;
//以CSV格式输出
cout << "R (csv) = " << endl << format(R, Formatter::FMT_CSV) << endl << endl;
//以Numpy格式输出
cout << "R (numpy) = " << endl << format(R, Formatter::FMT_NUMPY) << endl << endl;
//以C语言的格式输出
cout << "R (c) = " << endl << format(R, Formatter::FMT_C) << endl << endl;
//2D点
Point2f P(5, 1);
cout << "Point (2D) = " << P << endl << endl;
//3D点
Point3f P3f(2, 6, 7);
cout << "Point (3D) = " << P3f << endl << endl;
//vec模板类,数值响亮输出
vector<float> v;
v.push_back((float)CV_PI); v.push_back(2); v.push_back(3.01f);
cout << "Vector of floats via Mat = " << Mat(v) << endl << endl;
//矢量输出
vector <Point2f> vPoints(20);
vector<Point2f> vPoints(20);
for (size_t i = 0; i < vPoints.size(); ++i)
vPoints[i] = Point2f((float)(i * 5), (float)(i % 7));
cout << "A vector of 2D Points = " << vPoints << endl << endl;
waitKey(0);
return 0;
}
输出结果如下所示:
3、图像矩阵如何存储在内存中?
正如之前所说到的那样,矩阵的大小取决于所使用的颜色系统。更准确地说,它取决于使用的通道数量。在灰度图像的情况下,我们有类似的东西:
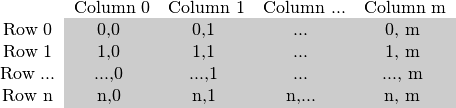
对于多通道图像,列包含与通道数一样多的子列。例如,在BGR颜色系统的情况下:

但是值得注意到的是:通道的顺序是反向的:BGR而不是RGB。因为在许多情况下,内存足够大以便以连续方式存储行,所以行可以一个接一个地跟随,从而创建单个长行。因为一切都在一个接一个的地方,这可能有助于加快扫描过程。我们可以使用cv :: Mat :: isContinuous()函数来询问矩阵是否是这种情况。
4、如何浏览图像的每个像素?
下面是官方提供的一个高效的图片处理的示例,
让我们考虑一种简单的减色方法。通过使用无符号字符C和C ++类型进行矩阵项存储,像素通道可以具有多达256个不同的值。对于三通道图像,这可以允许形成太多颜色(确切地说是1600万)。使用如此多的色调可能会严重影响我们的算法性能。但是,有时只需少量工作即可获得相同的最终结果。
在这种情况下,我们通常会减少色彩空间。这意味着我们将颜色空间当前值除以新的输入值,最终得到更少的颜色。例如,0到9之间的每个值都取新零值,每个值在10到19之间,值为10,依此类推。当您将uchar(unsigned char - 也就是0到255之间的值)值除以int值时,结果也将是char。这些值可能只是char值。因此,任何分数都将向下舍入。利用这一事实,uchar域中的上层操作可表示为:
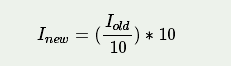
简单的颜色空间缩减算法包括仅通过图像矩阵的每个像素并应用该公式。值得注意的是,我们进行了除法和乘法运算。这些操作对于系统来说是非常昂贵的。如果可能的话,通过使用更便宜的操作(例如一些减法,添加或在最好的情况下使用简单的赋值)来避免它们是值得的。此外,请注意,上部操作只有有限数量的输入值。在uchar系统的情况下,这确切地说是256。
因此,对于较大的图像,最好事先计算所有可能的值,并在分配期间通过使用查找表进行分配。查找表是简单数组(具有一个或多个维度),对于给定的输入值变量,它保存最终输出值。它的优势在于我们不需要进行计算,我们只需要读取结果。
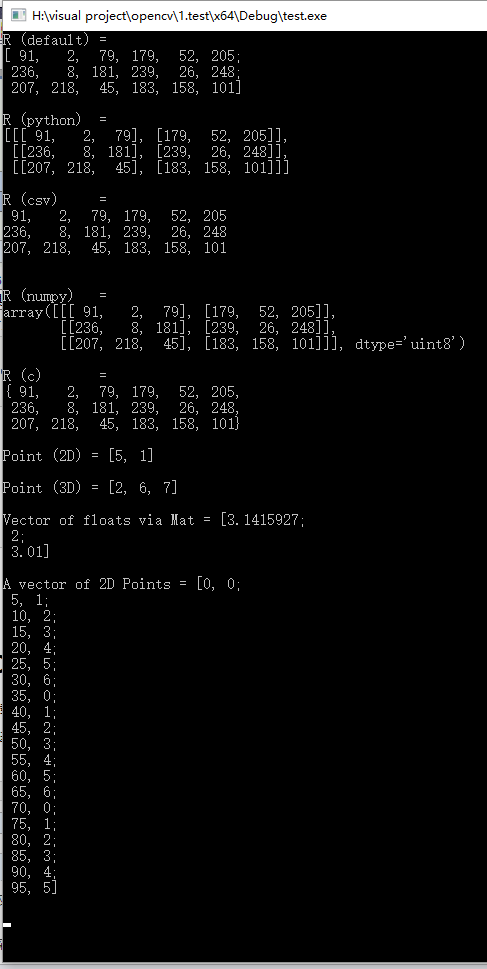
我们的测试用例程序(以及此处提供的示例)将执行以下操作:读取控制台行参数图像(可能是颜色或灰度 - 控制台行参数)并使用给定的控制台行参数整数值应用缩减。在OpenCV中,目前有三种主要方式逐像素地浏览图像。为了使事情更有趣,将使用所有这些方法扫描每个图像,并打印出它花了多长时间。
#include "stdafx.h"//viusal studio 必须加的linux下需删掉
#include <opencv2/core.hpp>
#include <opencv2/core/utility.hpp>
#include "opencv2/imgcodecs.hpp"
#include <opencv2/highgui.hpp>
#include <iostream>
#include <sstream>
using namespace std;
using namespace cv;
static void help()
{
cout
<< "\n--------------------------------------------------------------------------" << endl
<< "This program shows how to scan image objects in OpenCV (cv::Mat). As use case"
<< " we take an input image and divide the native color palette (255) with the " << endl
<< "input. Shows C operator[] method, iterators and at function for on-the-fly item address calculation." << endl
<< "Usage:" << endl
<< "./how_to_scan_images <imageNameToUse> <divideWith> [G]" << endl
<< "if you add a G parameter the image is processed in gray scale" << endl
<< "--------------------------------------------------------------------------" << endl
<< endl;
}
Mat& ScanImageAndReduceC(Mat& I, const uchar* table);
Mat& ScanImageAndReduceIterator(Mat& I, const uchar* table);
Mat& ScanImageAndReduceRandomAccess(Mat& I, const uchar * table);
int main(int argc, char* argv[])
{
help();
if (argc < 3)
{
cout << "Not enough parameters" << endl;
return -1;
}
Mat I, J;
if (argc == 4 && !strcmp(argv[3], "G"))
I = imread(argv[1], IMREAD_GRAYSCALE);
else
I = imread(argv[1], IMREAD_COLOR);
if (I.empty())
{
cout << "The image" << argv[1] << " could not be loaded." << endl;
return -1;
}
//! [dividewith]
int divideWith = 0; // convert our input string to number - C++ style
stringstream s;
s << argv[2];
s >> divideWith;
if (!s || !divideWith)
{
cout << "Invalid number entered for dividing. " << endl;
return -1;
}
uchar table[256];
for (int i = 0; i < 256; ++i)
table[i] = (uchar)(divideWith * (i / divideWith));
//! [dividewith]
const int times = 100;
double t;
t = (double)getTickCount();
for (int i = 0; i < times; ++i)
{
cv::Mat clone_i = I.clone();
J = ScanImageAndReduceC(clone_i, table);
}
t = 1000 * ((double)getTickCount() - t) / getTickFrequency();
t /= times;
cout << "Time of reducing with the C operator [] (averaged for "
<< times << " runs): " << t << " milliseconds." << endl;
t = (double)getTickCount();
for (int i = 0; i < times; ++i)
{
cv::Mat clone_i = I.clone();
J = ScanImageAndReduceIterator(clone_i, table);
}
t = 1000 * ((double)getTickCount() - t) / getTickFrequency();
t /= times;
cout << "Time of reducing with the iterator (averaged for "
<< times << " runs): " << t << " milliseconds." << endl;
t = (double)getTickCount();
for (int i = 0; i < times; ++i)
{
cv::Mat clone_i = I.clone();
ScanImageAndReduceRandomAccess(clone_i, table);
}
t = 1000 * ((double)getTickCount() - t) / getTickFrequency();
t /= times;
cout << "Time of reducing with the on-the-fly address generation - at function (averaged for "
<< times << " runs): " << t << " milliseconds." << endl;
//! [table-init]
Mat lookUpTable(1, 256, CV_8U);
uchar* p = lookUpTable.ptr();
for (int i = 0; i < 256; ++i)//
p[i] = table[i];
//! [table-init]
t = (double)getTickCount();
for (int i = 0; i < times; ++i)
//! [table-use]
LUT(I, lookUpTable, J);
//! [table-use]
t = 1000 * ((double)getTickCount() - t) / getTickFrequency();
t /= times;
cout << "Time of reducing with the LUT function (averaged for "
<< times << " runs): " << t << " milliseconds." << endl;
return 0;
}
Mat& ScanImageAndReduceC(Mat& I, const uchar* const table)
{
// accept only char type matrices
CV_Assert(I.depth() == CV_8U);
int channels = I.channels();
int nRows = I.rows;
int nCols = I.cols * channels;
if (I.isContinuous())
{
nCols *= nRows;
nRows = 1;
}
int i, j;
uchar* p;
for (i = 0; i < nRows; ++i)
{
p = I.ptr<uchar>(i);
for (j = 0; j < nCols; ++j)
{
p[j] = table[p[j]];
}
}
return I;
}
Mat& ScanImageAndReduceIterator(Mat& I, const uchar* const table)
{
// accept only char type matrices
CV_Assert(I.depth() == CV_8U);
const int channels = I.channels();
switch (channels)
{
case 1:
{
MatIterator_<uchar> it, end;
for (it = I.begin<uchar>(), end = I.end<uchar>(); it != end; ++it)
*it = table[*it];
break;
}
case 3:
{
MatIterator_<Vec3b> it, end;
for (it = I.begin<Vec3b>(), end = I.end<Vec3b>(); it != end; ++it)
{
(*it)[0] = table[(*it)[0]];
(*it)[1] = table[(*it)[1]];
(*it)[2] = table[(*it)[2]];
}
}
}
return I;
}
Mat& ScanImageAndReduceRandomAccess(Mat& I, const uchar* const table)
{
// accept only char type matrices
CV_Assert(I.depth() == CV_8U);
const int channels = I.channels();
switch (channels)
{
case 1:
{
for (int i = 0; i < I.rows; ++i)
for (int j = 0; j < I.cols; ++j)
I.at<uchar>(i, j) = table[I.at<uchar>(i, j)];
break;
}
case 3:
{
Mat_<Vec3b> _I = I;
for (int i = 0; i < I.rows; ++i)
for (int j = 0; j < I.cols; ++j)
{
_I(i, j)[0] = table[_I(i, j)[0]];
_I(i, j)[1] = table[_I(i, j)[1]];
_I(i, j)[2] = table[_I(i, j)[2]];
}
I = _I;
break;
}
}
return I;
}
程序运行方法的是:
执行文件 图像名.jpg 想要减少的整数值[G]
这里我用的是visual studio,则执行方法是,选中工程名——>右键——>属性
程序运行结果如下:
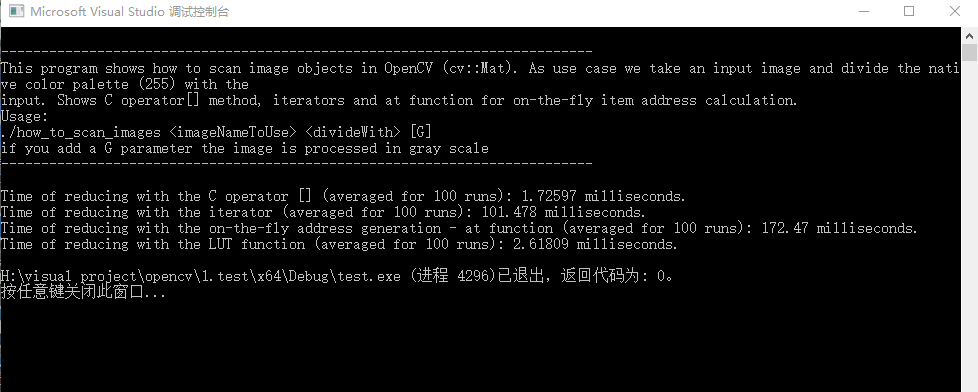
下面对程序的优点进行分析:
高效的方式(通过访问的方式提升访问速度)
说到性能,你无法击败经典的C访问。因此,我们建议的最有效的方法是:
Mat& ScanImageAndReduceC(Mat& I, const uchar* const table)
{
// accept only char type matrices
CV_Assert(I.depth() == CV_8U);
int channels = I.channels();
int nRows = I.rows;
int nCols = I.cols * channels;
if (I.isContinuous())
{
nCols *= nRows;
nRows = 1;
}
int i,j;
uchar* p;
for( i = 0; i < nRows; ++i)
{
p = I.ptr<uchar>(i);
for ( j = 0; j < nCols; ++j)
{
p[j] = table[p[j]];
}
}
return I;
}
在这里,我们基本上只获取指向每行开头的指针,然后直到它结束。在矩阵以连续方式存储的特殊情况下,我们只需要一次请求指针并一直到最后。我们需要注意彩色图像:我们有三个通道,所以我们需要在每行中传递三倍以上的项目。
还有另外一种方法。Mat对象的数据数据成员返回指向第一行第一列的指针。如果此指针为null,则表示该对象中没有有效输入。检查这是检查图像加载是否成功的最简单方法。如果存储是连续的,我们可以使用它来遍历整个数据指针。如果是灰度图像,这将看起来像:
uchar * p = I.data;
for(unsigned int i = 0; i <ncol * nrows; ++ i)
* p ++ = table [* p];
你会得到相同的结果。但是,这段代码后来很难阅读。如果你有更先进的技术,那就更难了。而且,在实践中我发现你会得到相同的性能结果(因为大多数现代编译器可能会自动为你做出这个小优化技巧)。
迭代器(安全)方法
如果有效的方法确保您通过正确数量的uchar字段并跳过行之间可能出现的间隙是您的责任。迭代器方法被认为是一种更安全的方式,因为它从用户接管这些任务。您需要做的就是询问图像矩阵的开始和结束,然后只需增加开始迭代器直到结束。要获取迭代器指向的值,请使用*运算符(在它之前添加它)。
Mat& ScanImageAndReduceIterator(Mat& I, const uchar* const table)
{
// accept only char type matrices
CV_Assert(I.depth() == CV_8U);
const int channels = I.channels();
switch(channels)
{
case 1:
{
MatIterator_<uchar> it, end;
for( it = I.begin<uchar>(), end = I.end<uchar>(); it != end; ++it)
*it = table[*it];
break;
}
case 3:
{
MatIterator_<Vec3b> it, end;
for( it = I.begin<Vec3b>(), end = I.end<Vec3b>(); it != end; ++it)
{
(*it)[0] = table[(*it)[0]];
(*it)[1] = table[(*it)[1]];
(*it)[2] = table[(*it)[2]];
}
}
}
return I;
}
在彩色图像的情况下,我们每列有三个uchar项目。这可以被认为是uchar项目的简短向量,已经在OpenCV中使用Vec3b名称进行了洗礼。要访问第n个子列,我们使用简单的operator []访问。重要的是要记住OpenCV迭代器遍历列并自动跳到下一行。因此,如果使用简单的uchar迭代器,在彩色图像的情况下,您将只能访问蓝色通道值。
带参考返回的动态地址计算
建议不要使用最终方法进行扫描。它是为了获取或修改图像中的某些随机元素。其基本用法是指定要访问的项目的行号和列号。在我们之前的扫描方法中,您已经可以观察到通过我们正在查看图像的类型来说这很重要。这里没有什么不同,因为您需要手动指定在自动查找中使用的类型。对于以下源代码(使用+ cv :: at()函数)的灰度图像,您可以观察到这种情况:
Mat& ScanImageAndReduceRandomAccess(Mat& I, const uchar* const table)
{
// accept only char type matrices
CV_Assert(I.depth() == CV_8U);
const int channels = I.channels();
switch(channels)
{
case 1:
{
for( int i = 0; i < I.rows; ++i)
for( int j = 0; j < I.cols; ++j )
I.at<uchar>(i,j) = table[I.at<uchar>(i,j)];
break;
}
case 3:
{
Mat_<Vec3b> _I = I;
for( int i = 0; i < I.rows; ++i)
for( int j = 0; j < I.cols; ++j )
{
_I(i,j)[0] = table[_I(i,j)[0]];
_I(i,j)[1] = table[_I(i,j)[1]];
_I(i,j)[2] = table[_I(i,j)[2]];
}
I = _I;
break;
}
}
return I;
}
这些函数采用您的输入类型和坐标,并即时计算查询项的地址。然后返回对它的引用。当您获得值时,这可能是常量,而在设置值时,这可能是非常数。作为调试模式中的安全步骤* 仅执行检查输入坐标是否有效且确实存在。如果不是这种情况,您将在标准错误输出流上获得一个很好的输出消息。与发布模式中的有效方式相比,使用它的唯一区别是,对于图像的每个元素,您将获得一个新的行指针,用于我们使用C运算符[]来获取列元素。
如果您需要使用此方法对图像执行多次查找,则为每个访问输入类型和at关键字可能会很麻烦且耗时。为了解决这个问题,OpenCV有一个cv :: Mat_数据类型。它与Mat相同,需要在定义时通过查看数据矩阵来指定数据类型,但是作为回报,您可以使用operator()来快速访问项目。为了使事情变得更好,这可以很容易地从通常的cv :: Mat数据类型转换。您可以在上部函数的彩色图像的情况下看到此示例用法。然而,重要的是要注意cv :: at()可以完成相同的操作(具有相同的运行时速度)功能。为懒惰的程序员技巧写一点。
核心功能
这是在图像中实现查找表修改的奖励方法。在图像处理中,您希望将所有给定图像值修改为其他值是很常见的。OpenCV提供了修改图像值的功能,无需编写图像的扫描逻辑。我们使用核心模块的cv :: LUT()函数。首先,我们构建一个Mat类型的查找表:
Mat lookUpTable(1,256,CV_8U);
uchar * p = lookUpTable.ptr();
for(int i = 0; i <256; ++ i)
p [i] = table [i];
最后调用函数(我是我们的输入图像,J是输出图像):
LUT(I,lookUpTable,J);
5、基本数据持久性和存储
在后续的模型中会用到函数存储和读取数据。校准或机器学习等很多应用会在完成计算时将结果保存,方便下一次检索到他们。OpenCV提供XML/YAML持久化层可以完成这个任务。
要将OpenCV数据或其他的数值数据写入文件,可以使用FileStorage类中(如STL流的)C运算符的流,下面是一个创建保存数据的存储文件的示例:
#include "stdafx.h"
#include "opencv2/opencv.hpp"
using namespace cv;
int main(int, char** argv)
{
// 创建流
FileStorage fs("test.yml", FileStorage::WRITE);
// Save an int
int fps = 5;
fs << "fps" << fps;
// 创建mat文例
Mat m1 = Mat::eye(2, 3, CV_32F);
Mat m2 = Mat::ones(3, 2, CV_32F);
Mat result = (m1 + 1).mul(m1 + 3);
// write the result
fs << "Result" << result;
//释放文件
fs.release();
FileStorage fs2("test.yml", FileStorage::READ);
Mat r;
fs2["Result"] >> r;
std::cout << r << std::endl;
fs2.release();
return 0;
}
该程序首先保存一个.yml文件,然后将数据从.yml文件中读取出来,程序运行结果如下:
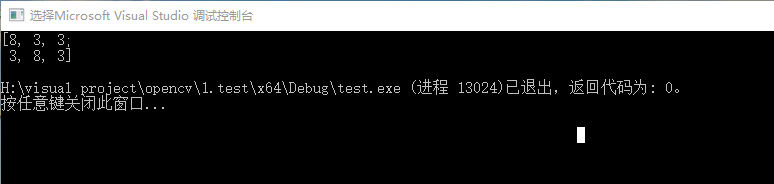
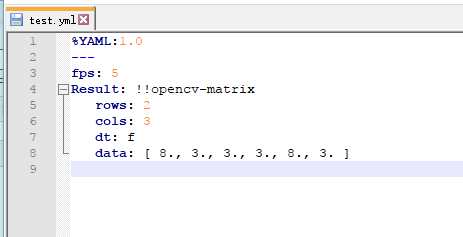
同时,在test.cpp的文件家中会产生一个test.yml文件,这个文件是由
FileStorage fs("test.yml", FileStorage::WRITE);
产生的,打开YAML格式文件可以看到如下内容:
6、C接口于C++接口的混合使用方法
下面是一个将C接口与C ++接口混合使用的示例:
#include "stdafx.h"
#include <iostream>
#include <opencv2/imgproc.hpp>
#include "opencv2/imgcodecs.hpp"
#include <opencv2/highgui.hpp>
using namespace cv; // //新的C ++接口API位于此命名空间内。导入它。
using namespace std;
//! [head]
static void help(char* progName)
{
cout << endl << progName
<< " shows how to use cv::Mat and IplImages together (converting back and forth)." << endl
<< "Also contains example for image read, splitting the planes, merging back and " << endl
<< " color conversion, plus iterating through pixels. " << endl
<< "Usage:" << endl
<< progName << " [image-name Default: 111.jpg]" << endl << endl;
}
//! [start]
// 注释掉define只使用最新的C ++ API
#define DEMO_MIXED_API_USE
#ifdef DEMO_MIXED_API_USE
# include <opencv2/highgui/highgui_c.h>
# include <opencv2/imgcodecs/imgcodecs_c.h>
#endif
int main(int argc, char** argv)
{
help(argv[0]);
const char* imagename = argc > 1 ? argv[1] : "111.jpg";
#ifdef DEMO_MIXED_API_USE
Ptr<IplImage> IplI(cvLoadImage(imagename)); // Ptr <T>是一个安全的引用计数指针类
if (!IplI)
{
cerr << "Can not load image " << imagename << endl;
return -1;
}
Mat I = cv::cvarrToMat(IplI); // 转换为新样式容器。只创建了标题。图像未复制。
#else
Mat I = imread(imagename); // 较新的cvLoadImage替代方案,MATLAB风格的函数
if (I.empty()) //与if(!I.data)相同
{
cerr << "Can not load image " << imagename << endl;
return -1;
}
#endif
//! [start]
//! [new]
//将图像转换为YUV颜色空间。输出图像将自动创建。
Mat I_YUV;
cvtColor(I, I_YUV, COLOR_BGR2YCrCb);
vector<Mat> planes; //使用STL的向量结构来存储多个Mat对象
split(I_YUV, planes); //将图像拆分为单独的颜色平面(YUV)
//! [new]
#if 1 // change it to 0 if you want to see a blurred and noisy version of this processing
//! [scanning]
// Mat扫描
//方法1.使用迭代器处理Y平面
MatIterator_<uchar> it = planes[0].begin<uchar>(), it_end = planes[0].end<uchar>();
for (; it != it_end; ++it)
{
double v = *it * 1.7 + rand() % 21 - 10;
*it = saturate_cast<uchar>(v*v / 255);
}
for (int y = 0; y < I_YUV.rows; y++)
{
//方法2.使用预先存储的行指针处理第一个色度平面。
uchar* Uptr = planes[1].ptr<uchar>(y);
for (int x = 0; x < I_YUV.cols; x++)
{
Uptr[x] = saturate_cast<uchar>((Uptr[x] - 128) / 2 + 128);
//方法3.使用单个元素访问处理第二色度平面
uchar& Vxy = planes[2].at<uchar>(y, x);
Vxy = saturate_cast<uchar>((Vxy - 128) / 2 + 128);
}
}
//! [scanning]
#else
//! [noisy]
Mat noisyI(I.size(), CV_8U); //创建指定大小和类型的矩阵
//使用正态分布的随机值填充矩阵(数字偏差关闭)。
//还有randu()用于均匀分布的随机数生成
randn(noisyI, Scalar::all(128), Scalar::all(20));
//模糊噪声I,内核大小为3x3,两个sigma都设置为0.5
GaussianBlur(noisyI, noisyI, Size(3, 3), 0.5, 0.5);
const double brightness_gain = 0;
const double contrast_gain = 1.7;
#ifdef DEMO_MIXED_API_USE
//将新矩阵传递给仅适用于IplImage或CvMat的函数:
//步骤1)转换标题(提示:不会复制数据)。
//步骤2)调用函数(提示:传递指针不要忘记一元“&”以形成指针)
IplImage cv_planes_0 = planes[0], cv_noise = noisyI;
cvAddWeighted(&cv_planes_0, contrast_gain, &cv_noise, 1, -128 + brightness_gain, &cv_planes_0);
#else
addWeighted(planes[0], contrast_gain, noisyI, 1, -128 + brightness_gain, planes[0]);
#endif
const double color_scale = 0.5;
// Mat :: convertTo()取代了cvConvertScale。
//必须明确指定输出矩阵类型(我们保持原样 - planes [1] .type())
//如果我们在编译时知道数据类型(这里是“uchar”),那么cv :: convertScale的替代形式。
//这个表达式不会创建任何临时数组(所以应该几乎和上面一样快)
planes[2] = Mat_<uchar>(planes[2] * color_scale + 128 * (1 - color_scale));
// Mat :: mul替换了cvMul()。同样,在简单表达式的情况下,不会创建临时数组。
planes[0] = planes[0].mul(planes[0], 1. / 255);
//! [noisy]
#endif
//! [end]
merge(planes, I_YUV); //现在合并结果
cvtColor(I_YUV, I, COLOR_YCrCb2BGR); //并生成输出RGB图像
namedWindow("image with grain", WINDOW_AUTOSIZE);//用它来创建图像
#ifdef DEMO_MIXED_API_USE
//这是为了证明I和IplI真正共享数据 - 上述结果
//处理存储在I中,因此也存储在IplI中。
cvShowImage("image with grain", IplI);
#else
imshow("image with grain", I); //新的MATLAB样式函数显示
#endif
//! [end]
waitKey();
// Tip:没有内存需要被释放
// 所有的内存都会被 Vector<>, Mat and Ptr<> 释放
return 0;
}
程序运行结果如下:
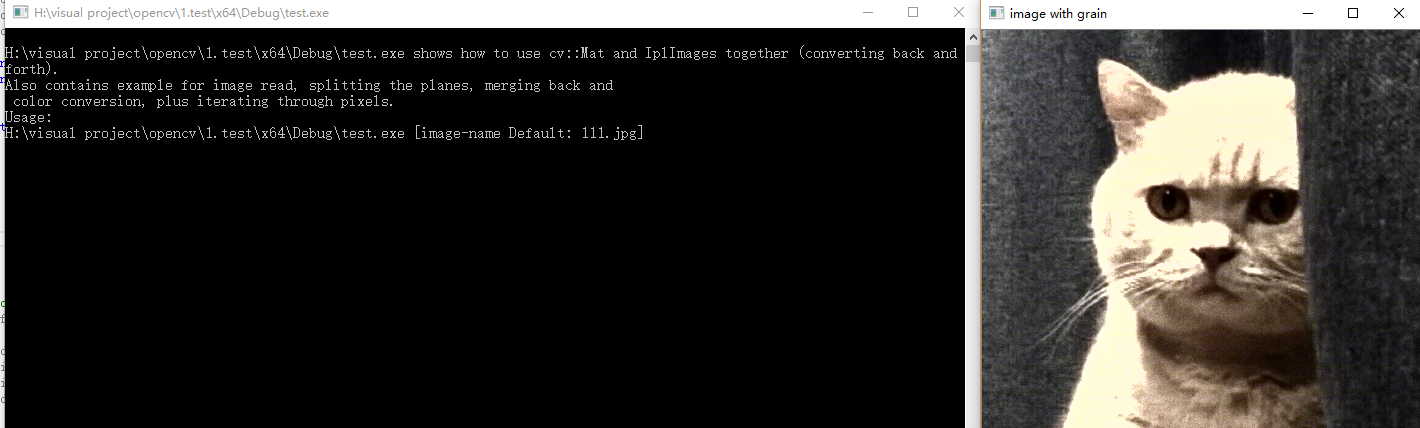
7、使用OpenCV parallel_for_来并行化代码
1、并行化运行代码的前提条件
第一个前提条件是使用并行框架构建OpenCV。在OpenCV 3.2中,以下并行框架按此顺序可用:
- 英特尔线程构建模块(第三方库,应明确启用)
- C =并行C / C ++编程语言扩展(第三方库,应该明确启用)
- OpenMP(集成到编译器,应该明确启用)
- APPLE GCD(系统范围,自动使用(仅限APPLE))
- Windows RT并发(系统范围,自动使用(仅限Windows RT))
- Windows并发(运行时的一部分,自动使用(仅限Windows - MSVC ++> = 10))
- Pthreads(如果有的话)
如您所见,OpenCV库中可以使用多个并行框架。一些并行库是第三方库,必须在CMake中明确构建和启用(例如TBB,C =),其他并行平台自动提供(例如APPLE GCD),但您应该可以访问并行框架直接或通过启用CMake中的选项并重建库。
第二个(弱)前提条件与您想要实现的任务更相关,因为并非所有计算都适合/可以通过并行方式运行。为了保持简单,可以拆分为多个基本操作且没有内存依赖性(没有可能的竞争条件)的任务很容易并行化。计算机视觉处理通常易于并行化,因为大多数时候一个像素的处理不依赖于其他像素的状态。
2、目标
编写一个程序来绘制一个Mandelbrot集,利用几乎所有可用的CPU负载。
Mandelbrot集定义的命名是由数学家Adrien Douady向数学家Benoit Mandelbrot致敬。它在数学领域之外是着名的,因为图像表示是一类分形的一个例子,一个数学集合展示了在每个尺度上显示的重复图案(甚至更多,Mandelbrot集合是自相似的,因为整个形状可以反复看到不同的规模)。有关更深入的介绍,您可以查看相应的Wikipedia文章。在这里,我们将介绍绘制Mandelbrot集的公式(来自上述维基百科文章)。
Mandelbrot集是c的值集 在二次映射迭代下0的轨道的复平面中
\[\left\{ {\begin{array}{*{20}{c}}
{{Z_0} = 0}\\
{{Z_{n + 1}} = Z_n^2 + c}
\end{array}} \right.\]
仍然有限。也就是说,复数c如果从z开始,则是Mandelbrot集的一部分0= 0并重复应用迭代,z的绝对值ñ仍然有界然而大ň得到。这也可以表示为
\[\mathop {\lim }\limits_{n \to \infty } \sup \left| {{Z_{{\rm{n}} + 1}}} \right| \le 2\]
3、伪代码
生成Mandelbrot集表示的简单算法称为“逃逸时间算法”。对于渲染图像中的每个像素,如果复数在有限或最大迭代次数下有界,我们使用递归关系进行测试。不属于Mandelbrot集的像素将快速逃逸,而我们假设在固定的最大迭代次数之后像素位于集合中。高迭代值将产生更详细的图像,但计算时间将相应增加。我们使用“转义”所需的迭代次数来描绘图像中的像素值。
For each pixel (Px, Py) on the screen, do:
{
x0 = scaled x coordinate of pixel (scaled to lie in the Mandelbrot X scale (-2, 1))
y0 = scaled y coordinate of pixel (scaled to lie in the Mandelbrot Y scale (-1, 1))
x = 0.0
y = 0.0
iteration = 0
max_iteration = 1000
while (x*x + y*y < 2*2 AND iteration < max_iteration) {
xtemp = x*x - y*y + x0
y = 2*x*y + y0
x = xtemp
iteration = iteration + 1
}
color = palette[iteration]
plot(Px, Py, color)
为了在伪代码和理论之间建立联系,我们有:
\[\begin{array}{*{20}{c}}
{z = x + iy}\\
{{z^2} = {x^2} + i2xy - {y^2}}\\
{c = {x_0} + i{y_0}}
\end{array}\]
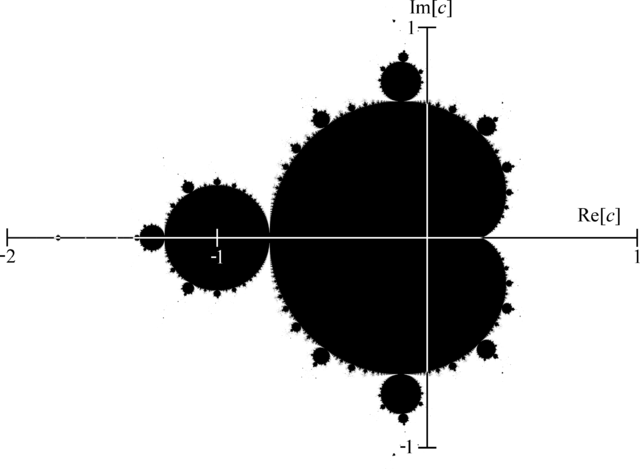
在这个图中,我们记得复数的实部在x轴上,虚部在y轴上。如果我们放大特定位置,您可以看到整个形状可以重复显示。
4、代码实现
#include "stdafx.h"
#include <iostream>
#include <opencv2/core.hpp>
#include <opencv2/imgcodecs.hpp>
using namespace std;
using namespace cv;
namespace
{
//! [mandelbrot-escape-time-algorithm]
int mandelbrot(const complex<float> &z0, const int max)
{
complex<float> z = z0;
for (int t = 0; t < max; t++)
{
if (z.real()*z.real() + z.imag()*z.imag() > 4.0f) return t;
z = z * z + z0;
}
return max;
}
//! [mandelbrot-escape-time-algorithm]
//! [mandelbrot-grayscale-value]
int mandelbrotFormula(const complex<float> &z0, const int maxIter = 500) {
int value = mandelbrot(z0, maxIter);
if (maxIter - value == 0)
{
return 0;
}
return cvRound(sqrt(value / (float)maxIter) * 255);
}
//! [mandelbrot-grayscale-value]
//! [mandelbrot-parallel]
class ParallelMandelbrot : public ParallelLoopBody
{
public:
ParallelMandelbrot(Mat &img, const float x1, const float y1, const float scaleX, const float scaleY)
: m_img(img), m_x1(x1), m_y1(y1), m_scaleX(scaleX), m_scaleY(scaleY)
{
}
virtual void operator ()(const Range& range) const CV_OVERRIDE
{
for (int r = range.start; r < range.end; r++)
{
int i = r / m_img.cols;
int j = r % m_img.cols;
float x0 = j / m_scaleX + m_x1;
float y0 = i / m_scaleY + m_y1;
complex<float> z0(x0, y0);
uchar value = (uchar)mandelbrotFormula(z0);
m_img.ptr<uchar>(i)[j] = value;
}
}
ParallelMandelbrot& operator=(const ParallelMandelbrot &) {
return *this;
};
private:
Mat &m_img;
float m_x1;
float m_y1;
float m_scaleX;
float m_scaleY;
};
//! [mandelbrot-parallel]
//! [mandelbrot-sequential]
void sequentialMandelbrot(Mat &img, const float x1, const float y1, const float scaleX, const float scaleY)
{
for (int i = 0; i < img.rows; i++)
{
for (int j = 0; j < img.cols; j++)
{
float x0 = j / scaleX + x1;
float y0 = i / scaleY + y1;
complex<float> z0(x0, y0);
uchar value = (uchar)mandelbrotFormula(z0);
img.ptr<uchar>(i)[j] = value;
}
}
}
//! [mandelbrot-sequential]
}
int main()
{
//! [mandelbrot-transformation]
Mat mandelbrotImg(4800, 5400, CV_8U);
float x1 = -2.1f, x2 = 0.6f;
float y1 = -1.2f, y2 = 1.2f;
float scaleX = mandelbrotImg.cols / (x2 - x1);
float scaleY = mandelbrotImg.rows / (y2 - y1);
//! [mandelbrot-transformation]
double t1 = (double)getTickCount();
#ifdef CV_CXX11
//! [mandelbrot-parallel-call-cxx11]
parallel_for_(Range(0, mandelbrotImg.rows*mandelbrotImg.cols), [&](const Range& range) {
for (int r = range.start; r < range.end; r++)
{
int i = r / mandelbrotImg.cols;
int j = r % mandelbrotImg.cols;
float x0 = j / scaleX + x1;
float y0 = i / scaleY + y1;
complex<float> z0(x0, y0);
uchar value = (uchar)mandelbrotFormula(z0);
mandelbrotImg.ptr<uchar>(i)[j] = value;
}
});
//! [mandelbrot-parallel-call-cxx11]
#else
//! [mandelbrot-parallel-call]
ParallelMandelbrot parallelMandelbrot(mandelbrotImg, x1, y1, scaleX, scaleY);
parallel_for_(Range(0, mandelbrotImg.rows*mandelbrotImg.cols), parallelMandelbrot);
//! [mandelbrot-parallel-call]
#endif
t1 = ((double)getTickCount() - t1) / getTickFrequency();
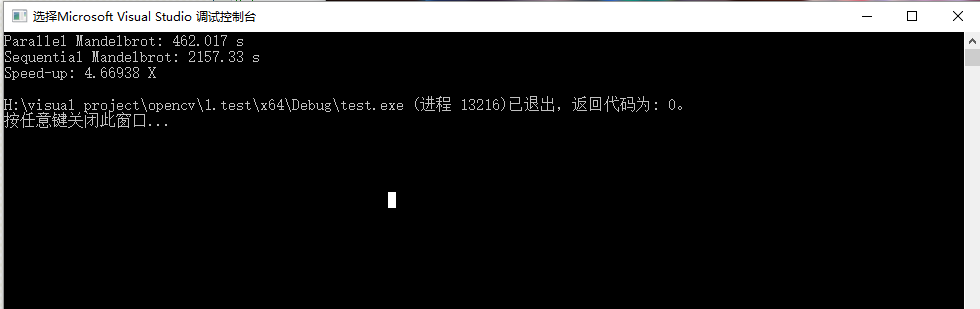
cout << "Parallel Mandelbrot: " << t1 << " s" << endl;
Mat mandelbrotImgSequential(4800, 5400, CV_8U);
double t2 = (double)getTickCount();
sequentialMandelbrot(mandelbrotImgSequential, x1, y1, scaleX, scaleY);
t2 = ((double)getTickCount() - t2) / getTickFrequency();
cout << "Sequential Mandelbrot: " << t2 << " s" << endl;
cout << "Speed-up: " << t2 / t1 << " X" << endl;
imwrite("Mandelbrot_parallel.png", mandelbrotImg);
imwrite("Mandelbrot_sequential.png", mandelbrotImgSequential);
return EXIT_SUCCESS;
}
程序运行结果如下:
参考资料:
1、Mat - 基本图像容器
2、OpenCV矩阵的基本操作
3、MoreWindows博客目录(微软最有价值专家,原创技术文章152篇)
4、Open Source Computer Vision Library
5、opencv实例精讲

 浙公网安备 33010602011771号
浙公网安备 33010602011771号