内存分配
1、内存分配的形式有哪些?
一个C/C++编译的程序所占用的系统内存一般分为以下几个部分的内容:
(1)由符号起始的区块(BSS),BSS段通常是是指用来存放程序中未初始化的全局数据和静态数据的一块内存区域。BSS段属于静态内存分配,程序结束后静态变量资源由系统自动释放。
(2)数据段(data segment):数据段通常是指用来存放程序中已初始化的全局变量的一块内存区域。数据段也属于静态内存分配。
(3)代码段(code segment/text segment):代码段也叫文本段,通常是指用来存放程序执行代码(包括类成员函数和全局函数以及其他函数代码)的一块内存区域,这部分区域的大小在程序运行前就已经确定,并且内存区域通常是只读,某些架构也允许代码段为可写,即允许修改程序。在代码段中,也由可能包含一些只读的常数变量,如字符串常量。这个段一般是可以被共享的,如在linux中打开两个vi来编辑文本,那么一般来说这两个vi是共享一个代码段的。
(4)堆(heap):堆用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc或new等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张),当利用free或delete等函数释放内存时,被释放的内存从堆中被删除(堆被缩减)。堆一般由程序员分配释放,若程序员不释放,程序结束可能由系统回收。需要注意的是,它与数据结构中的堆是两回事,分配方式类似于链表。
(5)栈(stack):栈用户存放程序临时创建的局部变量,一般包括函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此之外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且等到调用结束后,函数的返回值也会被存放回栈中。栈由编译器自动分配释放,存放函数的参数值、局部变量的值等。其操作方式类似于数据结构中的栈。栈内存分配运算内置于处理器的指令集中,一般使用寄存器来存取,效率很高,但是分配的内存容量有限。
需要注意的是,代码段和数据段之间有明确的分隔,但是数据段和堆栈段之间没有,而且栈是向下增长的,堆是向上增长的。
程序示例如下:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int global=0;//全局初始化区
char *p1; //全局未初始化区
int main()
{
int a; //栈
char s[]="abcdefg";//栈
char *p2;//栈
cahr *p3="123456789";//123456789在常量取,p3在栈上
static int c=0;//全局(静态)初始化区
p1=(char *)malloc(100);
p2=(char *)malloc(200);//分配得来的100和200b的区域就在堆区
strcpy(p1,"123456789");//123456789放在常量区,编译器可能会将它与p3所指向的
//“123456789”优化成一个地方
return 0;
}
除了全局静态对象,还有局部静态对象和类的静态成员,局部静态对象是在函数中定义的,就像栈对象一样,只不过,其前面多了个static关键字。局部静态对象的生命期是从其所在函数第一次被调用,更确切的说,是当第一次执行到该静态对象的声明代码时,产生该静态局部变量,知道整个程序结束后,才销毁对象,直到整个程序结束时,才销毁该对象。类的静态成员的生命周期是该类的第一次调用到程序的结束。
2、什么是内存泄露
堆是动态分配内存的,并且可以分配使用很大的内存,使用不好便会产生内存泄露。频繁的使用malloc和free会产生内存碎片(类似磁盘碎片)。
内存泄露(memory leak)是指由与疏忽或错误造成程序未能释放已经不再使用的内存的情况。一般常说的内存泄漏是指堆内存泄露,内存泄露其实并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,失去了堆该段内存的控制,因而造成了内存的浪费。内存泄露与许多其他问题有着相似的症状,并且通常情况下只能由那些可以获得程序源代码的程序员才可以分析出来。
应用程序一般使用malloc、calloc、realloc、new等函数从堆中分配到一块内存,使用完后,程序必须负责相应的调用free或delete释放该内存块,否则这块内存就不能被再次使用,造成内存泄露。
例如,对指针进行重新赋值,程序代码如下:
char *memoryArea=malloc(10); char *newArea=malloc(10); memoryArea=newArea;
堆memeoryArea的赋值会导致memoryArea之前指向的内容丢失,最终造成内存泄露。如下程序就因为未能堆返回值进行处理,最终导致内存泄露。
char *fun()
{
return malloc(20);
}
void callfun()
{
fun();
}
内存泄露往往会导致出现CPU资源耗尽的严重后果,所以我们用malloc或new分配的内存都应当在适当的时机用free或delete释放,在对指针赋值前,要确保没有内存位置会变为孤立的。每当释放结构化的元素,而该元素又包含指向动态分配的内存位置的指针时,都应首先遍历子内存位子并从那里开始释放,然后再遍历回父节点,始终正确返回动态分配的内存引用的函数返回值。
3、sizeof
对变量而言,sizeof的大小就像变量的体积一样,它的大小字节影响着变量的存储和访问效率。
1、sizeof是关键字吗
C语言一共有32个关键字,5种语言类型,具体内容见下表:
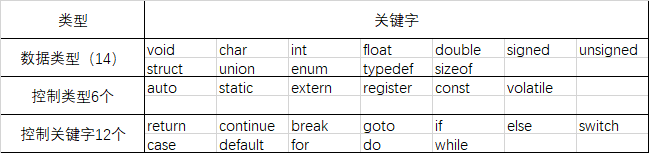
根据上表可知,sizeof是数据类型的关键字,而非函数,很多时候它都可能被误解为操作符,这是不对的。
引申:预处理指令是否是C语言中的语言类型?
不是。语句是编程语言的基础,C语言中的语言类型一共有一下5种:
(1)表达式语句。(2)函数调用语句。(3)控制语句。(4)复合语句(5)空语句
2、strlen与sizeof的区别
strlen执行的是一个计数器的工作,它从内存的某个位置(可以说字符串的开头,中间某个位置,甚至是某个不确定的内存区域)开始扫描,直到碰到第一个字符串结束符‘/0'为止,然后返回计算器值。
sizeof是C语言的关键字,它以字节的形式给出操作数的存储大小,操作数可以是一个表达式或括号内的类型名,操作符的存储大小由操作数决定。
strlen与sizeof的差别表现在一下几个方面:
- sizeof 是关键字,而strlen是函数。sizeof后如果是类型必须加括弧,如果是变量名可以不加括弧。、
- sizeof操作符的结果类型是size_t,它在头文件种typedef为unsigned int类型。该类型保证能够容纳实现所建立的最大对象的字节大小。
- sizeof可以用类型作为参数,strlen只能用char *做参数,并且必须是以“\0"结尾的。sizeof还可以以函数作为参数,如int g(),则sizeof(g())的值等于sizeof(int)的值,在32位计算机下,该值为4.
- 当数组名做sizeof的参数时不退化,传递给strlen就退化为指针了。以数组 char a[10]为例,在32位机器下,sizeof(a)=1*10=10,而传递给strlen就不一样了。
- 大部分编译程序的sizeof都是在编译的时候计算的,所以可以通过sizeof(x)来定义数组维数。而strlen的运算则是在运行期计算的,用来计算字符传的实际长度,不是类型占内存的大小。例如,char str[20]="0123456789",字符数组str是编译期大小已经固定的数组,在32位机器下,为1*20=20,而其strlen大小则是在运行期确定的,所以其值为字符串的实际长度为10.
- 当用于计算一个结构类型或变量的sizeof时,返回实际的大小,当用于计算一个静态变量或数组时,返回整个数组所占用的大小,而sizeof不能返回动态数组大小。
- 数组作为参数传给函数时传的时指针而不是数组,传递的时数组的首地址。例如:
fun(char[8]) fun(char[])
都等价于fun(char *).在C++内传递数组永远传递的都是传递指向首元素的指针,编译器不知道数组的大小,如果向在函数内知道数组的大小,需要这样做:进入函数后用memcpy复制出来,长度由另一个参数传进去。
fun(unsigned char *p1,int len)
{
unsigned char * buf=new unsigned char[len+1];
memcpy(buf,p1,len)
}
程序示例:
#include "stdafx.h"
#include<stdio.h>
#include<string.h>
int main()
{
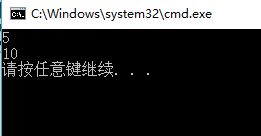
char arr[10] = "hello";
printf("%d\n", strlen(arr));
printf("%d\n", sizeof(arr));
return 0;
}
运行结果如下,sizeof返回定义的arr数组时,编译器为其分配的数组空间大小不关心里面存了多少数据。strlen只关心存储内容,不关心大小和类型。
3、对于结构体而言,为什么sizeof返回的值一般大于期望值。
struct是一种复合数据类型,其构成元素既可以是基本数据类型,如int、double、float、char等,也可以是复合数据类型,如数组、struct、union等数据单元。
一般而言,struct的sizeof是所有成员对齐后长度相加,而union的sizeof是取最大的成员长度。
在结构中,编译器为结构的每个成员按其自然边界(alignment)分配空间。各个成员按照它们被声明的顺序存储,第一个成员的地址和整个结构的地址相同。
字节对齐也称为字节填充。主要是为了在空间于复杂度上达到平衡。简单的讲,就是为了在可接受的空间浪费前提下,尽可能的提高对相同运算过程的最少(快)处理。字节对齐的作用不仅仅是便于CPU的快速访问,使CPU的性能达到最佳,而且可以有效的节省存储空间。例如,32位计算机的数据传输值位4字节,64位计算机传输是8字节,这样struct在默认情况下,编译器会对struct的结构进行(32位机)4的倍数或(64位机)8的倍数的数据,对齐。对于32位机来说,4字节对齐能够使CPU访问速度提高,比如说一个long类型的变量,如果跨越了4字节的边界存储,那么CPU就要读取2次。这样效率就低了,但需要注意的是,如果在32位机中使用1字节或者2字节对齐,不仅不会提高效率,反而会使变量访问速度降低。
在默认情况下,编译器为每一个变量或数据单元按其自然对界条件分配空间。一般的,可以通过下面的方法来改变默认的对界条件:
- 使用伪指令#pragma pack(n),C编译器讲按照n个字节对齐。
- 使用伪指令#pragma pack(),取消自定义字节对齐方式。
- 另外,还有一种方式:_attrbute((aligned(n))),让所作用的结构成员对齐在n字节自然边界上。如果结构中有成员的长度大于n,则按照最大成员的长度来对齐。_attribute_(packed))。取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐。
例如如下数据结构
struct test
{
char x1;//2
short x2;//2
float x3;//4
char x4;//4
}
由于编译器默认情况下会对struct做边界对齐,结构的第一个成员x1,其偏移地址为0,占据了第1个字节,第二个成员x2为short类型,其起始地址必须2字节对齐,因此编译器在x2和x1之间填充一个空字节。结构的第三个成员x3和第四个成员x4恰好落在其自然边界地址上,在它们前面不需要额外的填充字节。在test结构中,成员x3要求4字节对齐,使该结构中所有成员要求的最大边界单元,因而test结构的自然边界条件为4字节,编译器在成员x4后面填充了三个字节,整个结构所占据字节为12个字节。
字节对齐的细节与编译器实现相关,但一般而言,满足以下3个准则:
- 结构体变量的首地址能够被其最宽基本类型成员的大小所除。
- 结构体每个成员相对于接哦古提首地址的偏移量(offset)都是成员大小的整数倍。如有需要,编译器会在成员之间加上填充字节。
- 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节。
需要主要的是,基本类型是指前面提到的像char、short、int、float、double这样的内置数据类型,这里所说的“数据宽度”就是指其sizeof的大小,在64位和32位机器上,这些基本类型的sizeof大小分别为
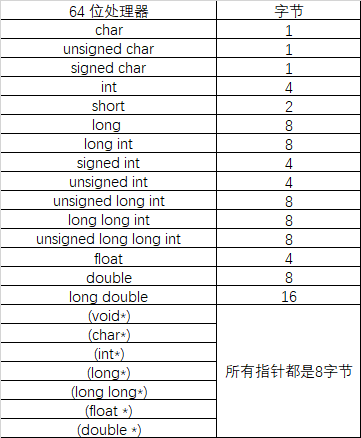
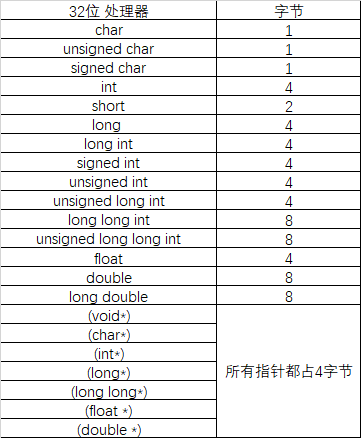
由于结构体的成员可以说复合类型,所以在寻找最宽基本类型成员时,应当包括复合类型成员的子成员,而不是把复合成员看成是一个个整体。如果一个结构体中包含另外一个结构体成员,那么此时最宽基本类型成员不是该结构体成员,而是取基本类型的最宽值。但在确定复合类型成员的偏移位置时,则是复合类型看作整体对待,即复杂类型(如结构)的默认对齐方式是它最长的成员的对齐方式,这样在成员是复杂类型时,可以最小化长度,达到程序优化的目的。
下面是一个相关示例:
#include "stdafx.h"
#include<iostream>
#include<string.h>
#include<wchar.h>
using namespace std;
struct MyNode
{
char ch2 : 3; //1+3
long ch : 5; //4
unsigned char ch1 : 3; //1+3
};
struct Node
{
unsigned char ch1 : 3; //1+3
char ch2 : 2;
unsigned ch3 : 5; //4
short st : 9; //4
int in : 23; //4
};
class IPNode
{
int ver : 4; //4个位
int len : 4; //4个位
int sev : 8; //8个位
int total : 16; //16个位
};//4+4+8+16=32个位=4个字节
class Mail
{
char address[30]; //地址 //30+2(对齐要求)
double zip; //邮政编码 //32+8=40
long int telenum; //电话号码 //40+8=48
};
class Information
{
char name[25]; //员工姓名 //25+3=28
Mail addinfo; //结构作为成员,嵌套 //28+48=76+4=80(对齐要求)
double salary; //工资 //80+8=88
};
class Object
{
};
class Test
{
void fun()
{}
};
struct Inventory
{
char description[15]; //货物名称 //15
char no[10]; //货号 //25+3=28(对齐要求)
int quantity; //库存数量 //28+4=32
double cost; //成本 //32+8=40
double retail; //零售价格 //40+8=48
};
struct Employee
{
char name[27]; //员工姓名 27
char address[30]; //家庭住址 57+3=60(对齐要求)
long int zip; //邮政编码 64
long int telenum; //联络电话 68+4=72(对齐要求)
double salary; //工资 72+8=80
};
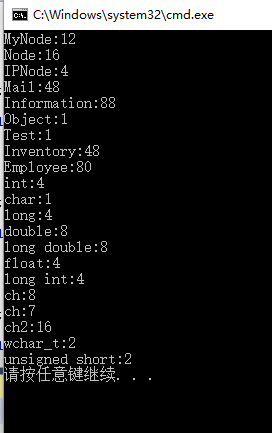
void main()
{
cout << "MyNode:" << sizeof(MyNode) << endl;
cout << "Node:" << sizeof(Node) << endl;
cout << "IPNode:" << sizeof(IPNode) << endl;
cout << "Mail:" << sizeof(Mail) << endl;
cout << "Information:" << sizeof(Information) << endl;
cout << "Object:" << sizeof(Object) << endl;
cout << "Test:" << sizeof(Test) << endl;
cout << "Inventory:" << sizeof(Inventory) << endl;
cout << "Employee:" << sizeof(Employee) << endl;
cout << "int:" << sizeof(int) << endl;
cout << "char:" << sizeof(char) << endl;
cout << "long:" << sizeof(long) << endl;
cout << "double:" << sizeof(double) << endl;
cout << "long double:" << sizeof(long double) << endl;
cout << "float:" << sizeof(float) << endl;
cout << "long int:" << sizeof(long int) << endl;
char ch[] = "newdata";
cout << "ch:" << sizeof(ch) << endl;
cout << "ch:" << strlen(ch) << endl;
//
wchar_t ch2[] = L"newdata";
cout << "ch2:" << sizeof(ch2) << endl;
cout << "wchar_t:" << sizeof(wchar_t) << endl;
cout << "unsigned short:" << sizeof(unsigned short) << endl;
}
程序运行结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号