Linux环境Clion使用Protobuf
一、protobuf
protobuf介绍
Protobuf是由google开发的一套开源序列化协议框架,类似于XML,JSON,采用协议序列化用于数据存储与读取,与XML相比,定义了数据格式更加简单,数据访问接口可以自动化生成,加快了开发者开发速度,最新的版本为proto3已经支持Java,C++, Python, Java Lite, Ruby,JavaScript, Objective-c 以及C#, go,等常用语言.目前很多项目都在使用Protobuf
官方链接(不需要FQ):https://developers.google.cn/protocol-buffers/
官方文档:https://developers.google.cn/protocol-buffers/docs/overview#whynotxml
优势
既然xml已经使用非常广泛,那么为什么还需要Protocol Buffer?其优势主要有以下几点:
简单
比xml要小3到10倍,proto文件被编译成bin二进制文件
比xml要快20到100倍
结构更加清晰,不会产生歧义
生成数据操作类更加容易,编程更加容易上手,访问接口代码基本都是自动生产
例如定义一个person数据结构,里面包含name和email两个个人信息,xml定义如下:
<person>
<name>John Doe</name>
<email>jdoe@example.com</email>
</person>
而使用protobuf定义时,其txt定义格式如下:
# Textual representation of a protocol buffer.
# This is *not* the binary format used on the wire.
person {
name: "John Doe"
email: "jdoe@example.com"
}
是不是有点像python中的元组,采用key-value形式.
protobuf语法
上述是采用txt格式进行定义的,但是一般protobuf都是使用.proto文件,其语法格式使用Message定义
采用Message定义,person定义如下:
message Person {
required string name = 1;
required string email= 2;
}
意思是Person中的第一个字段为name,其数据类型为string,比选项;第二个字段为email,其数据类型为string,比选项.数据结构前加message关键词,意思是定义一个名为Person的数据结构,Message结构里面的每个成员结构格式如下:
[rules][data_type] [data_name] = [number]
分别解释其各个字段意思
Specifying Field Rules
该字段主要是定义该变量的规则,主要有三种规则:
required:该字段变量为必须的,实例中必须包含的字段.如果是在调试模式下编译 libprotobuf,则序列化一个未初始化的message 将将导致断言失败。在优化的构建中,将跳过检查并始终写入消息。但是,解析未初始化的消息将始终失败(通过从解析方法返回 false)
optional:该字段是可选的,可以设置也可以不设置该字段.如果未设置可选字段值,则使用默认值。对于简单类型,你可以指定自己的默认值,就像我们在示例中为电话号码类型所做的那样。否则,使用系统默认值:数字类型为 0,字符串为空字符串,bools 为 false。对于嵌入 message,默认值始终是消息的 “默认实例” 或 “原型”,其中没有设置任何字段。调用访问器以获取尚未显式设置的 optional(或 required)字段的值始终返回该字段的默认值。
repeated:该字段可以重复任意次数(包括零次).重复值的顺序将保留在 protocol buffer 中。可以将 repeated 字段视为动态大小的数组。
Data type
Protobuf支持常用的数据类型,支持的数据类型如下表:
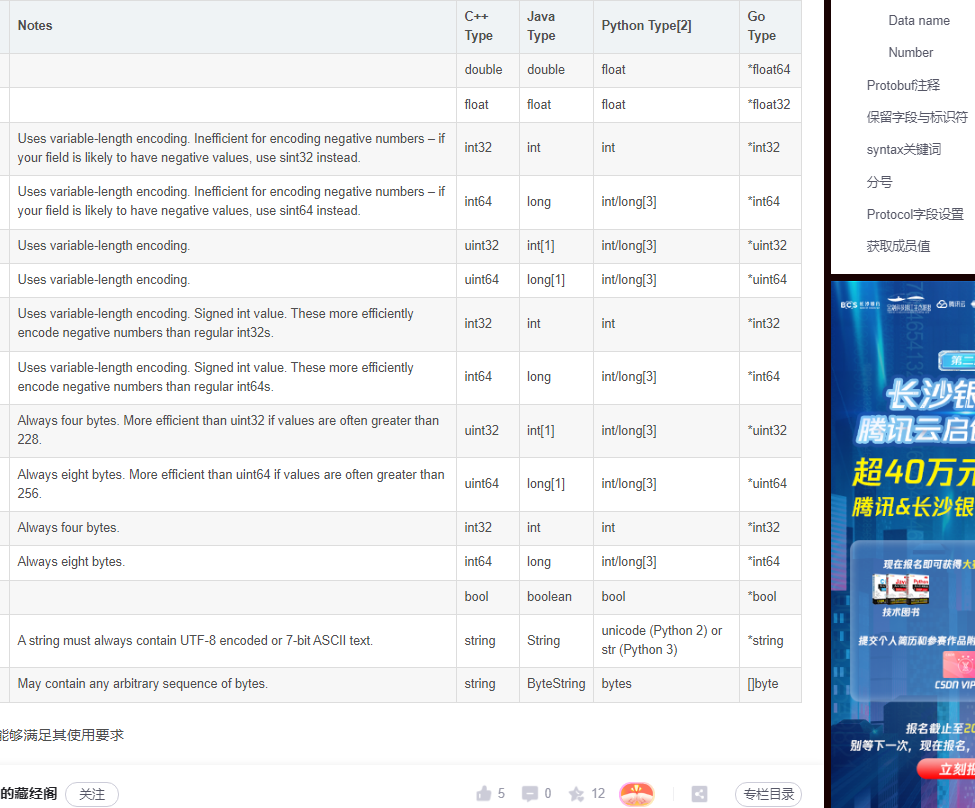
Data name
data name为数据成员名
Number
Protobuf是采用key-value形式,将成员名映射为number,这样就能实现数据的序列化.每个数据字段都有唯一的数值型标识符.这些标识符用于标识字段在消息中的二进制格式,使用中的类型不应该随意改动。需要注意的是,[1-15]内的标识在编码时只占用一个字节,包含标识符和字段类型。[16-2047]之间的标识符占用2个字节。建议为频繁出现的消息元素使用[1-15]间的标识符。如果考虑到以后可能或扩展频繁元素,可以预留一些标识符。number最小为为1,最大为229 - 1, or 536,870,911, 其中19000到19999为Protocol内部使用
Protobuf注释
在proto文件中经常需要添加注释对某个字段进行注释,支持C风格的双斜线//单行注释
保留字段与标识符
可以使用reserved关键字指定保留字段和保留标识符
message Foo {
reserved 2, 15, 9 to 11;
reserved "foo", "bar";
}
syntax关键词
sysntax关键字经常用到proto文件开头用来表明使用的是哪个proto版本
syntax = "proto2"
分号
行与行之间需要加分号,类似C语言.
Protocol字段设置
在对数据操作过程中经常需要对某个成员变量值进行修该,protocol提供了一系列很方便的API, 使用set函数,其格式为
set_[data_name]
例如定一个下面一个message
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
分别设置其中的name,id以及email,其操作为:
Person person;
person.set_name("John Doe");
person.set_id(1234);
person.set_email("jdoe@example.com");
获取成员值
获取成员值同样很简单,只有直接访问其成员即可,如下例子
fstream input("myfile", ios::in | ios::binary);
Person person;
person.ParseFromIstream(&input);
cout << "Name: " << person.name() << endl;
cout << "E-mail: " << person.email() << endl;
Packed 编码
在 proto2 中为我们提供了可选的设置 [packed = true],而这一可选项在 proto3 中已成默认设置。
packed 目前只能用于 repeated类型。
packed = true 主要使让 ProtoBuf 为我们把 repeated primitive 的编码结果打包,从而进一步压缩空间,进一步提高效率、速度。这里打包的含义其实就是:原先的 repeated 字段的编码结构为 Tag-Length-Value-Tag-Length-Value-Tag-Length-Value...,因为这些 Tag 都是相同的(同一字段),因此可以将这些字段的 Value 打包,即将编码结构变为 Tag-Length-Value-Value-Value...
optional default设置
optional字段的默认值可以使用default来设置,例如:
optional int32 num = 1 [default = 0];
将默认值设值为0
二、工程整合
下面使用一个简单的例子说明Protobuf的基本使用方法.
1. 新建PbTest.proto文件
syntax = "proto3";
message Person {
required int32 age = 1;
required string name = 2;
}
message Family {
repeated Person person = 1;
}
2. 开始转换
使用protoc命令编译proto文件,编译完成之后会自动生产.h和.cpp的代码
- 进入proto文件所在目录执行:
protoc --cpp_out=. PbTest.proto
语法: protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/XXXX.proto
案例: protoc --cpp_out=. XXXX.proto
- 会在当前目录生成两个文件,如下图:
 生成***.cc和***.h文件
生成***.cc和***.h文件protoc命令还可以将proto文件生成python和java文件接口,以供python和java使用,可以使用--help命令来查看protoc参数:
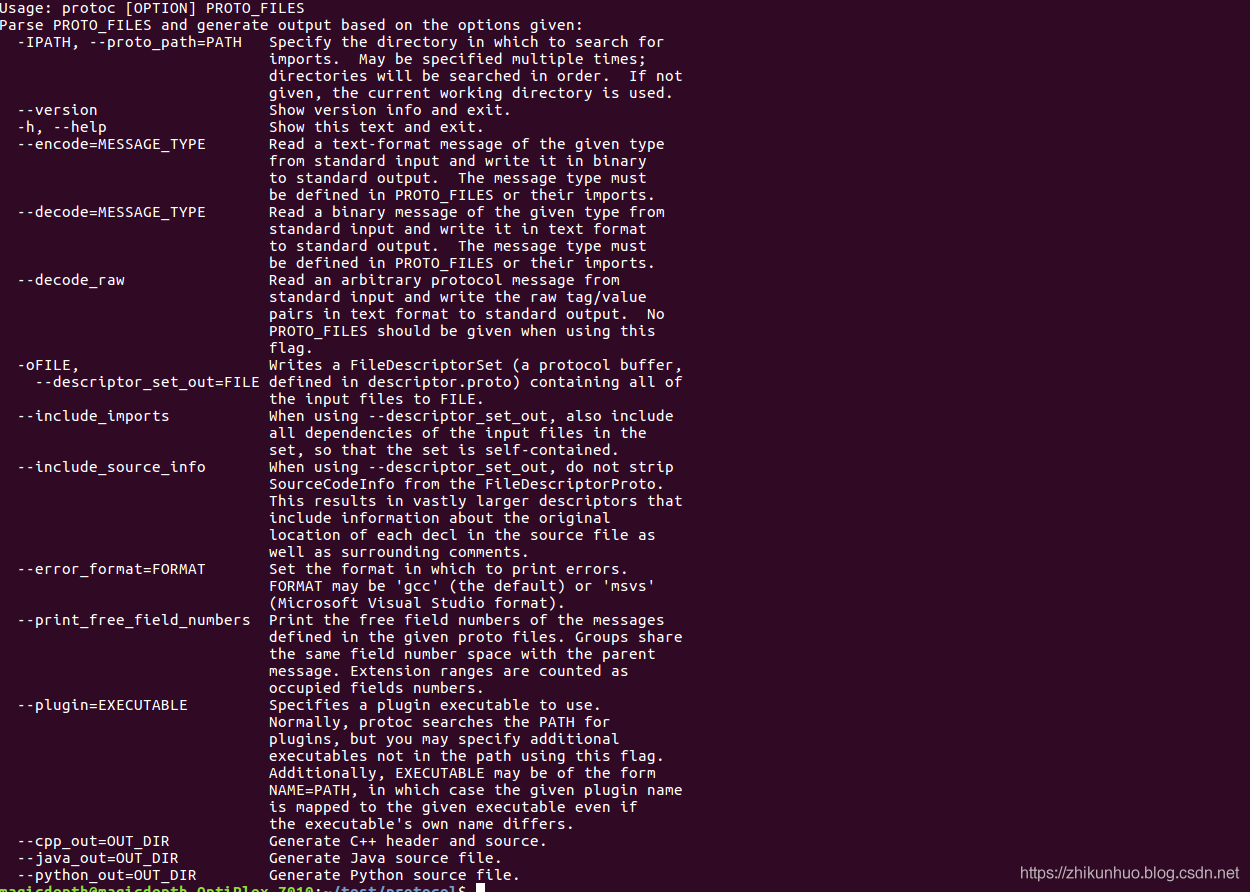
其中--cpp_out是生成c++接口文件以及源码,--jave_out是生成java接口,--python_out是生成python接口.
3. 文件加入工程

- 配置makelist文件:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号