【大厂面试04期】讲讲一条MySQL更新语句是怎么执行的?
在面试中,经常会问到在MySQL中一条更新语句是怎么执行的?在本文中,我们就来详细学习一下更新语句的执行流程,也有利于我们在工作中更好地使用MySQL。
流程图
这是在网上找到的一张流程图,写的比较好,大家可以先看图,然后看详细阅读下面的各个步骤。
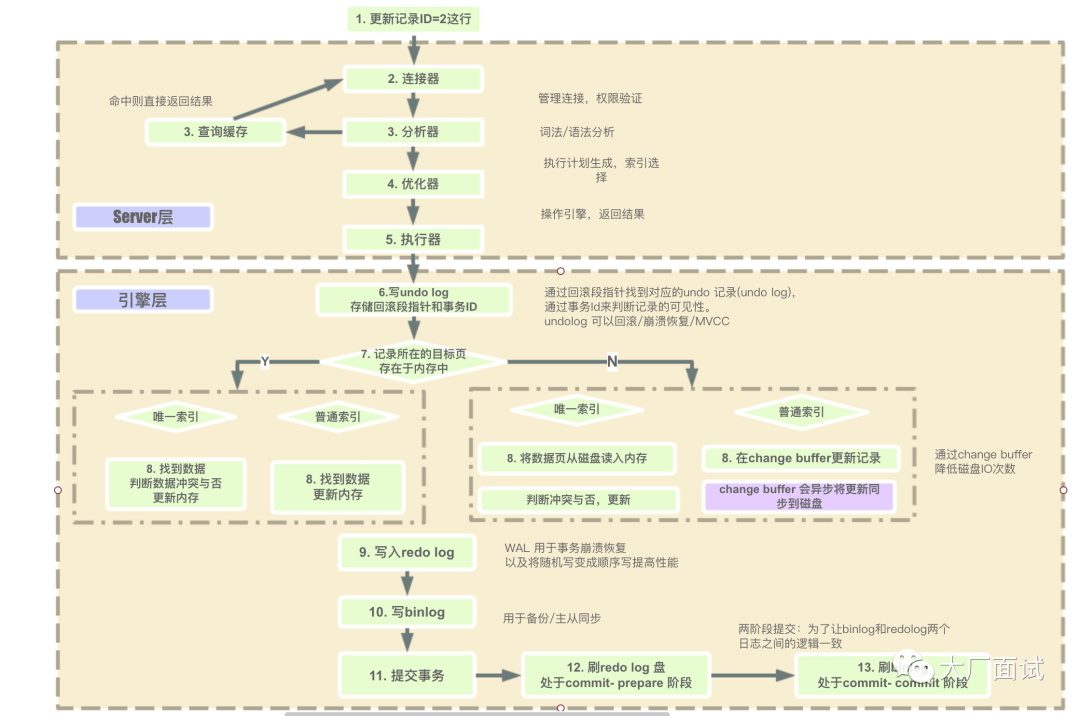
执行流程:
1.连接验证及解析
客户端与MySQL Server建立连接,发送语句给MySQL Server,接收到后会针对这条语句创建一个解析树,然后进行优化,(解析器知道语句是要执行什么,会评估使用各种索引的代价,然后去使用索引,以及调节表的连接顺序)然后调用innodb引擎的接口来执行语句。
2.写undo log
innodb 引擎首先开启事务,对旧数据生成一个UPDATE的语句(如果是INSERT会生成UPDATE语句),用于提交失败后回滚,写入undo log,得到回滚指针,并且更新这个数据行的回滚指针和版本号(会设置为更新的事务id)。
3.从索引中查找数据
根据查询条件去B+树中找到这一行数据(如果是唯一性索引,查到第一个数据就可以了(因为有唯一性约束),如果是普通索引,会把所有数据查找出来。)
4.更新数据
首先判断数据页是否在内存中?
4.1 如果数据页在内存中
先判断更新的索引是普通索引还是唯一性索引?
4.1.1 普通索引
如果更新的索引是普通索引,直接更新内存中的数据页
4.1.2 唯一性索引
如果更新的索引是唯一性索引,判断更新后是否会破坏数据的唯一性,不会的话就更新内存中的数据页。
4.2 如果数据页不在内存中
先判断更新的索引是普通索引还是唯一性索引?
4.2.1 普通索引
如果是更新的索引是普通索引,将对数据页的更新操作记录到change buffer,change buffer会在空闲时异步更新到磁盘。
4.2.2 唯一性索引
如果是更新的索引是唯一性索引,因为需要保证更新后的唯一性,所以不能延迟更新,必须把数据页从磁盘加载到内存,然后判断更新后是否会数据冲突,不会的话就更新数据页。
5.写undo log(prepare状态)
将对数据页的更改写入到redo log,将redo log设置为prepare状态。
6.写bin log(commit状态),提交事务
通知MySQL server已经更新操作写入到redo log 了,随时可以提交,将执行的SQL写入到bin log日志,将redo log改成commit状态,事务提交成功。(一个事务是否执行成功的判断依据是是否在bin log中写入成功。写入成功后,即便MySQL Server崩溃,之后恢复时也会根据bin log, redo log进行恢复。具体可以看看下面的崩溃恢复原则)
补充资料:
二段提交制是什么?
更新时,先改内存中的数据页,将更新操作写入redo log日志,此时redo log进入prepare状态,然后通知MySQL Server执行完了,随时可以提交,MySQL Server将更新的SQL写入bin log,然后调用innodb接口将redo log设置为提交状态,更新完成。
如果只是写了bin log就提交,那么忽然发生故障,主节点可以根据redo log恢复数据到最新,但是主从同步时会丢掉这部分更新的数据。
如果只是写binlog,然后写redo log,如果忽然发生故障,主节点根据redo log恢复数据时就会丢掉这部分数据。
MySQL崩溃后,事务恢复时的判断规则是怎么样的?(以redolog是否commit或者binlog是否完整来确定)
如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交;
如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整:a. 如果是,则提交事务;b. 否则,回滚事务。
undo log是什么?
undo log主要是保证事务的原子性,事务执行失败就回滚,用于在事务执行失败后,对数据回滚。undo log是逻辑日志,记录的是SQL。(可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。)
在事务提交后,undo log日志不会立即删除,会放到一个待删除的链表中,有purge线程判断是否有其他事务在使用上一个事务之前的版本信息,然后决定是否可以清理,简单的来说就是前面的事务都提交成功了,这些undo才能删除。
change buffer是什么(就是将更新数据页的操作缓存下来)
在更新数据时,如果数据行所在的数据页在内存中,直接更新内存中的数据页。
如果不在内存中,为了减少磁盘IO的次数,innodb会将这些更新操作缓存在change buffer中,在下一次查询时需要访问这个数据页时,在执行change buffer中的操作对数据页进行更新。
适合写多读少的场景,因为这样即便立即写了,也不太可能会被访问到,延迟更新可以减少磁盘I/O,只有普通索引会用到,因为唯一性索引,在更新时就需要判断唯一性,所以没有必要。
redo log 是什么?
redo log就是为了保证事务的持久性。因为change buffer是存在内存中的,万一机器重启,change buffer中的更改没有来得及更新到磁盘,就需要根据redo log来找回这些更新。
优点是减少磁盘I/O次数,即便发生故障也可以根据redo log来将数据恢复到最新状态。
缺点是会造成内存脏页,后台线程会自动对脏页刷盘,或者是淘汰数据页时刷盘,此时收到的查询请求需要等待,影响查询。
干货内容回顾:
【大厂面试01期】高并发场景下,如何保证缓存与数据库一致性?
【大厂面试02期】Redis过期key是怎么样清理的?
【大厂面试03期】MySQL是怎么解决幻读问题的?
【大厂面试04期】讲讲一条MySQL更新语句是怎么执行的?
【大厂面试05期】说一说你对MySQL中锁的理解?
【大厂面试06期】谈一谈你对Redis持久化的理解?
【大厂面试07期】说一说你对synchronized锁的理解?
【大厂面试08期】谈一谈你对HashMap的理解?
本文已收录到我自己做的原创开源后端学习指南-《大厂面试指北》,目前在Github已经获得1.4K+ Star了,扫描下方二维码进技术群,可以领取精选制作的《大厂面试指北》PDF,一起讨论技术,一起学习进步!
《大厂面试指北》Github地址:
https://github.com/NotFound9/interviewGuide




 浙公网安备 33010602011771号
浙公网安备 33010602011771号