[基础]深度学习分布式训练相关概念
分布式训练
分为数据并行与模型并行:
- 数据并行就是一张GPU可能一次跑不了那么大的batch size,所以多用几张卡
- 模型并行就是一张GPU可能一次跑不了整个模型,所以把模型结构分成几个部分,每张卡跑一部分。
分为单机与多机:
- 单机就是只在一台机器上跑
- 多机就是用到多台机器,当中会涉及到一些远程调用RPC机制之类的来实现同步。
下面列举的例子是 单机、数据并行的模式:
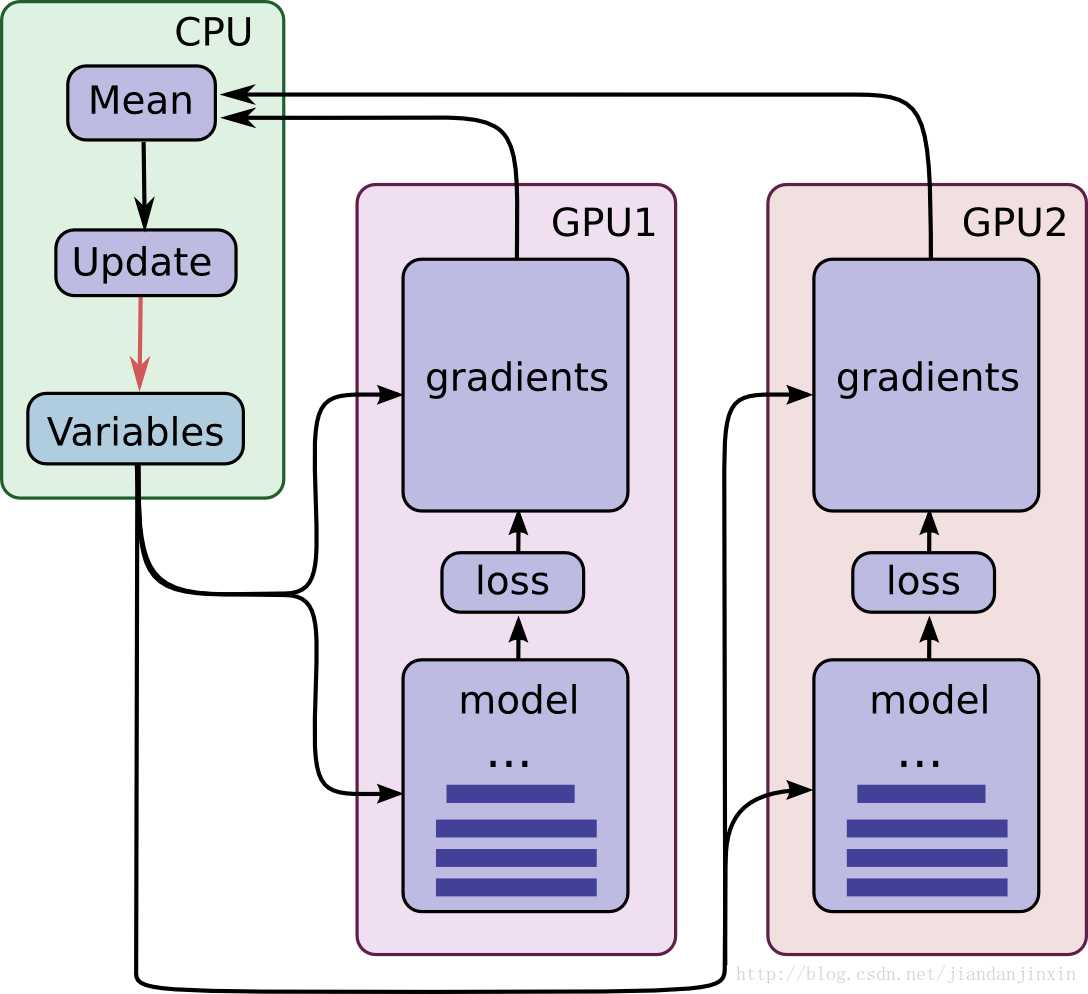
梯度更新
梯度更新的同步模式与异步模式,区别在于每个worker是否需要等其他的worker梯度计算完成:
- 同步模式,每个worker都forward完并计算好梯度之后,再归纳到一起求平均,更新参数,再将参数传递给每个卡的模型,执行下一轮迭代。好处是梯度比较稳定,坏处是存在短板效应,需要等待效率较低的设备完成。
- 异步模型,每个worker自己forward完计算完梯度,就去更新参数,然后继续迭代。每个worker迭代的时候读取的是当前模型的最新参数。好处是计算速度比较快,坏处是可能存在梯度失效的问题,即按照t0时刻读取的参数p0,经过forward计算完梯度之后,模型的参数可能已经被其他worker更新为p1,此时再利用旧参数的梯度去对新参数作更新,可能无法达到预期的效果。
是否等价于增大batch size
单机多卡训练、数据并行的方式,使用同步模式进行梯度更新的情况下,可以认为相当于 单卡的情况下增大 batch size
但也有一些要点需要考虑:
- 网络中是否使用了 batch norm,用了的话,batch norm是否有同步。如果没有同步,每张卡各算各的,那么 batch norm部分就只是一张卡的 batch size。
- CUDA随机种子的问题,每张卡可能随机种子会不同。
batch size增大,则相应的 lr 可以增大,同时,样本数量也要增大,维持足够的训练时长
为什么呢?首先理解一下GD, SGD, mini-batch SGD
- GD: 梯度下降,使用整个训练集计算梯度,也就是整个训练集都跑一遍 forward 之后再根据总的 loss 更新参数,然后进入下一轮迭代,同样再计算一次整个训练集。
- 优点:基于整个训练集计算的梯度,梯度估计相对较准,更新过程更准确。
- 缺点:耗时久。loss function 往往是非凸的(可以理解为有多个高峰和谷底),而更新网络参数所用到的优化算法都是基于凸优化理论的,因此只能收敛到 local minima,使用GD训练的话,最终收敛点很容易落在初始点附近的一个local minima,不太容易达到较好的收敛性能。
- SGD: 随机梯度下降,每次从整个训练集中随机选一个样本,forward 一次并计算梯度,根据梯度更新参数,再进行下一轮迭代,从训练集再随机选一个样本进行梯度更新。
- 优点:计算速度快,适合 online-learning ,数据流式到达的场景。
- 缺点:单个样本产生的梯度可能很不准确,方差较大,所以需要采用很小的learning rate 。另外,单个样本往往很难占满CPU/GPU的使用率,导致计算资源浪费。
- mini-batch SGD: 折中的方案,选一小批 batch size大小的样本进行梯度更新。
how to use
tensorflow:
- tower grad
- 每个gpu都用同一个计算图(变量是共享的),跑一个batch,得到每个gpu上的梯度,对梯度求和平均,再根据optimizer做反向传播,更新计算图中的变量值
pytorch:
- torch 提供了 DataParallel \ DataDistributedParallel ,从而对 model 进一步封装
参考资料
https://zhuanlan.zhihu.com/p/56991108 梯度的同步更新与异步更新,配图和流程说明比较清楚。
https://zhuanlan.zhihu.com/p/129912419 提及异步更新与同步更新的优缺点。
https://www.zhihu.com/question/323307595 是否等价于增大batch size
https://www.zhihu.com/question/421369328/answer/1479863790 有没有必要同步batch norm
https://www.zhihu.com/question/64134994/answer/216895968 batch size 对 LR 的影响
https://zhuanlan.zhihu.com/p/52596192 同步模式下,显卡之间怎么传输数据。
https://www.cnblogs.com/hellcat/p/9194110.html TensorFlow 使用分布式训练

 浙公网安备 33010602011771号
浙公网安备 33010602011771号