如何优雅的删除 Redis 中 以 xxx 开头的 key ?
一: 优雅分析
种种原因,业务中有时会有批量删 key 的需求,但如何删是一个值得讨论的问题。如题 “优雅” 二字,我们不希望这个操作 影响 Redis 的正常使用,或是性能波动等的问题。 所以,下面我们讨论的内容一切围绕 "优雅" 展开。
一个良好的 Redis 使用习惯,key 的命名应该是有规范的,方便后期的管理。基于这个规范,查找 以 xxx 开头,或包含 xx 的 所有 key 是容易的。 假如我们的实例中总的 key 有一个亿, room_user_list_ 开头的有 100w。要在 Redis 中清理这 100w 个 key,前提是你要先找到他们。
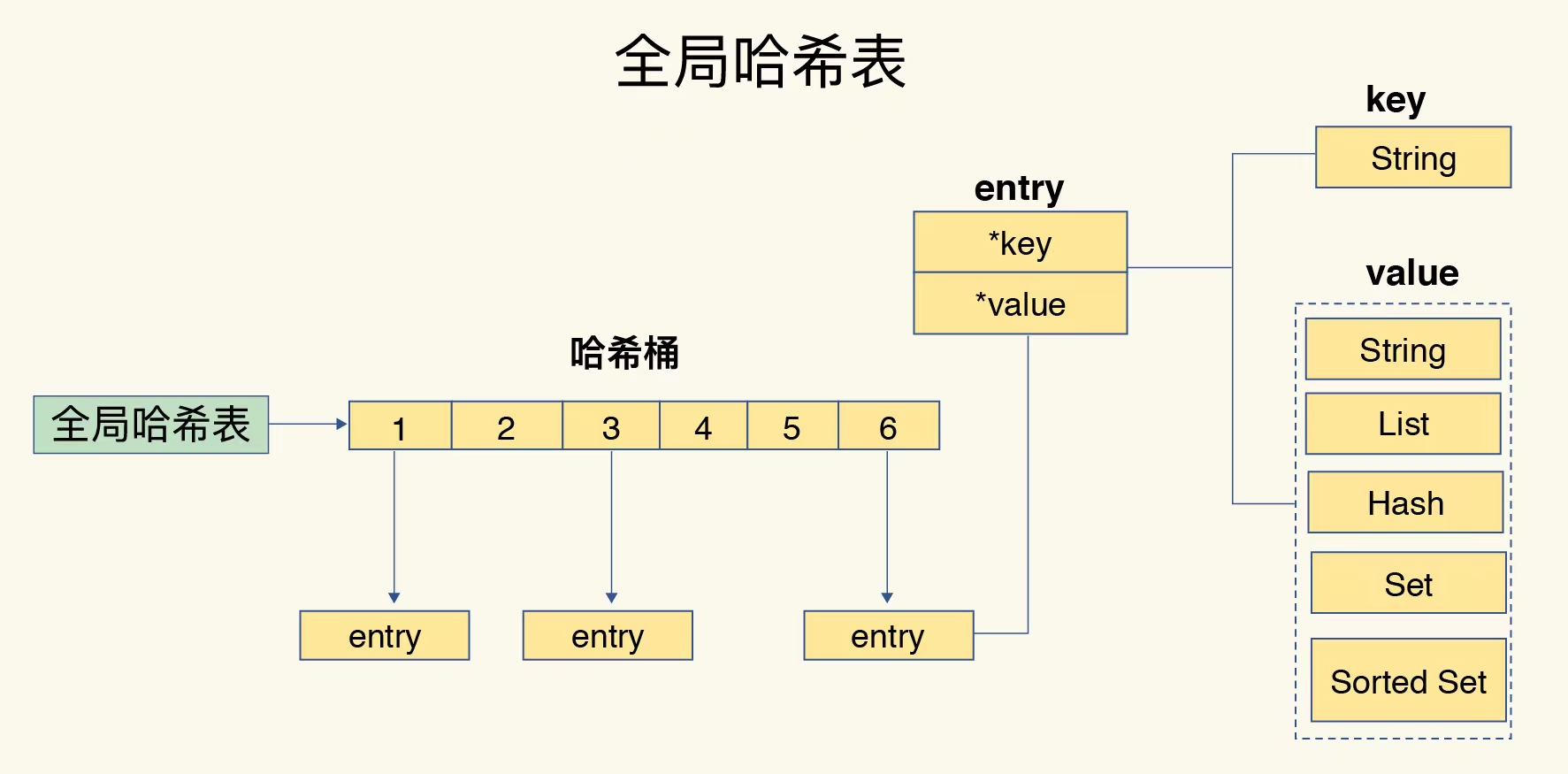
keys room_user_list_* 查找肯定不够优雅, 遍历全局哈希表是非常耗时的,这会导致实例阻塞(众所周知,Redis 的索引模型是 哈希表(链式),对 key 的 curd 操作是单线程的)。
keys 操作测试:
192.168.1.124:6379> keys zhangs*
1) "zhangs2"
2) "zhangs1"
3) "zhangs3"
(6.62s)
查 3 个 key 竟然花了 6s ,意味着我这个操作导致 redis 6s 不可用, 业务上是不可接受的。
因此,redis 提供了 scan 命令 替代 keys 这类的操作需求。Scan 语法格式如下:
语法格式:
SCAN cursor [MATCH pattern] [COUNT count]
cursor - 游标。
pattern - 匹配的模式。
count - 最大查找的 entry 数
SCAN 是一个基于游标的迭代器,每次调用该命令时,都会返回一个新的游标,需要在下一次调用时将其作为游标参数,以此完成对全局哈希表的迭代。
所以,scan 不会比 keys 操作快, 时间复杂度是相同的。不同的是 scan 基于游标,他每次只选取 哈希表中的一部分遍历,分段多次迭代,避免了
主线程阻塞。
scan 查找 room_user_list_* 开头的 key:
// 当游标被设置为 0 时,一个迭代开始,当迭代器返回的游标为 0 时,意味着迭代结束。 从0开始,至接收到 0 表示一次完整的迭代。
// count=10000 本次最多遍历 10000个 entry
192.168.1.124:6379> scan 0 match room_user_list_* count 10000
1) "5712896" // 返回的游标
2) 1) "room_user_list_2F9111DCExxxxC33DC5901307461"
2) "room_user_list_D7E2326D5yyyyy2479C33DC5901307461"
3) "room_user_list_D8997ACEAxxxxE59C33DC5901307461"
192.168.1.124:6379> scan 5712896 match room_user_list_* count 10000 // 本次调用使用上次调用的返回的游标继续迭代
1) "13866496"
2) (empty list or set)
192.168.1.124:6379> scan 13866496 match room_user_list_* count 10000
1) "10336512"
2) 1) "room_user_list_46E74F9EBF25AdddddC33DC5901307461"
192.168.1.124:6379> scan 10336512 match room_user_list_* count 10000
从这个结果中,我们发现每次 调用 返回的 key 个数是不一样的,有的为空,空列表并不意味着迭代结束,只有迭代器返回 0 才算结束。
个数不一样是因为,每次遍历的 entry 集合里符合 match 条件的 key 的个数不一样(这里也有一部分链式哈希的原因),没有符合条件的
key 就返回空列表,scan 并不保证返回 key 的数量。(count 参数容易使人误解,他不是限制每次返回的 key 数量)
每次迭代返回的游标似乎是随机的,没有什么规律。然而并不是这样。这里官网文档没有解释原因,社区里有人从源码分析了一下,大意是说,在
迭代的过程中,哈希表的大小可能发生变化, 游标采用 Reverse binary iteration 算法来计算,防止迭代的过程中哈希表大小改变漏 key 的问题。
count 越大,scan 总耗时越短,但是单次迭代的时间就越长,Redis 阻塞的时间也越长,如果 count = 1,和 keys 没什么区别。所以 count 的大小
设置需要取舍,10000 是推荐设置。
经过以上一系列原理的了解和验证,如何 优雅的 查找 room_user_list_* 开头的 key 是容易的, scan 0 match room_user_list_* count 10000 操作即可避免阻塞。
下一步是如何 优雅的 删 key,查找 和 删除 都做到优雅,才是我们想要的效果。删除主要是 避免 大 key 引起的性能波动,scan 返回的列表中如果得到的是 大 key,
我们是没法知道的,解决这个问题 我们 决定使用 ulink 操作,关于 unlink 的操作原理我之前的 文章 中已经有详细介绍,这里再简单回顾一下:unlink 是新启了一个线程
异步的执行 删除操作,删除后不会立即释放内存空间(标记清除),所以不会阻塞 Redis 主线程。
二:优雅实现
ok,基于已上分析,两个优雅的具体实现如下:(程序的逻辑: scan 遍历 hash 表 match 符合条件的 keys,unlink 异步 删除)
该操作已在生产环境验证,无阻塞,无性能波动,实现了 "优雅"。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import redis
import time
import logging
logging.basicConfig(filename='cli.txt', level=logging.INFO, filemode='a',
format='%(asctime)s - [%(levelname)s] %(message)s')
def cost(func):
def cost_time(*args, **kwargs):
start_time = time.time()
res = func(*args, **kwargs)
end_time = time.time()
logging.info('cost: {}'.format(end_time - start_time))
print('cost: {}'.format(end_time - start_time))
return res
return cost_time
class Redis:
"""
优雅 删除 以 xxx 开头的 Redis key
"""
def __init__(self, host, port=6379, password=None, db: 'int' = 0):
self.host = host
self.port = port
self.password = password
self.db = db
def cli(self):
connection_pool = redis.ConnectionPool(host=self.host, port=self.port, password=self.password, db=self.db,
decode_responses=True)
return redis.Redis(connection_pool=connection_pool)
@cost
def scan_unlink(self, match_regex, delete=False):
cursor = 0
count = 0
try:
redis_cli = self.cli()
while True:
cursor, keys = redis_cli.scan(cursor=cursor, match=match_regex, count=10000)
if len(keys) > 0 and delete is True:
redis_cli.unlink(*keys)
count += len(keys)
if cursor == 0:
logging.info('match keys: {}'.format(count))
print('match keys: {}'.format(count))
break
except Exception as e:
logging.error(e)
print(e)
return
instance = Redis("127.0.0.1")
instance.scan_unlink("name:siri*", delete=False)
参考文档:
- scan 的原理: https://redis.io/commands/scan/
- 极客时间 《Redis 核心技术与实践》
- scan course 原理: https://stackoverflow.com/questions/28102173/redis-how-does-scan-cursor-state-management-work
留一个思考问题:如果 Redis 中 有个较大的 集合类型(不仅是说 set ),业务上又不想清除集合中的全部元素,如何做到优雅?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号