
[二十六]JavaIO之再回首恍然(如梦? 大悟?)
流分类回顾
本文是JavaIO告一段落的总结帖
希望对JavaIO做一个基础性的总结(不涉及NIO)
从实现的角度进行简单的介绍
下面的这两个表格,之前出现过
| 数据源形式 | InputStream | OutputStream | Reader | Writer |
| ByteArray(字节数组) | ByteArrayInputStream | ByteArrayOutputStream | 无 | 无 |
| File(文件) | FileInputStream | FileOutputStream | FileReader | FileWriter |
| Piped(管道) | PipedInputStream | PipedOutputStream | PipedReader | PipedWriter |
| Object(对象) | ObjectInputStream | ObjectOutputStream | 无 | 无 |
| String | StringBufferInputStream | 无 | StringReader | StringWriter |
| CharArray(字符数组) | 无 | 无 | CharArrayReader | CharArrayWriter |
| 扩展功能点 | InputStream | OutputStream | Reader | Writer |
| Data(基本类型) | DataInputStream | DataOutputStream | 无 | 无 |
| Buffered(缓冲) | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter |
| LineNumber(行号) | 无 | LineNumberReader | 无 | |
| Pushback(回退) | PushbackInputStream | 无 | PushbackReader | 无 |
| Print(打印) | 无 | PrintStream | 无 | PrintWriter |
|
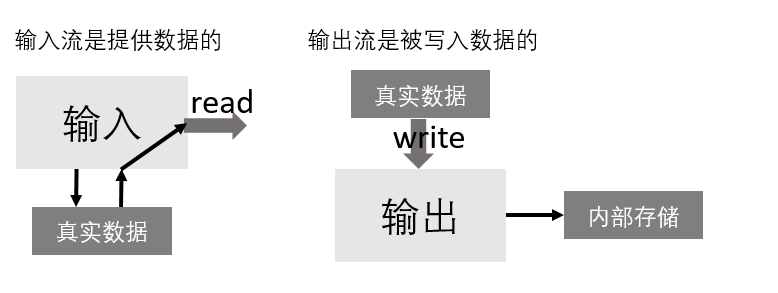
流分为输入输出流两种形式
数据格式又分为字节和字符两种形式
他们组合而来了四大家族
InputStream OutputStream Reader Writer
|
| 所有的四大家族的流有两种合成扩展方式: 按照数据源形式扩展 按照装饰功能点扩展 |
数据源形式扩展
现在我们换一个维度,从实现的角度,重新介绍下IO
| 数据源扩展的根本 |
| 从这种形式的数据中读取数据 写入数据到这种数据形式 |
我们上面列出来了ByteArray File Piped Object String CharArray 这几种常用的数据源形式
结合我们上面的概念,我们看一下,实际的实现
字节数组 / 字符数组 /String
| ByteArray 内存数据 |
|
| CharArray 内存数据 |
|
| String 内存数据 |
|
上面的这三种数据源形式,从上面看的话,逻辑非常清晰
| 读--->从哪里读?--->你给我一个数据源--->我以IO的操作习惯(InputStream/Reader) 读给你 |
|
写--->IO的操作习惯写(OutputStream/Writer) --->写到哪里?--->写到我自己内部的存储里
|
有人可能觉得写到你自己内部存储里面干嘛,有毛用?



|
内存数据,如果仅仅是存起来放到他自己肚子里面当然毛用没有
但是,他们都提供了吐出来的功能了
给[字节数组 字符数组 String] 提供了一个统一的一致性的读写形式,操作非常方便,不是么
|

真实数据使用引用指向
内部存储是内部的存储区
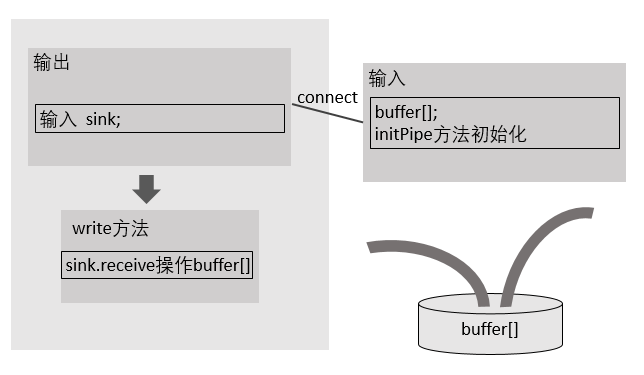
管道
| pipe 管道用于直连 然后进行数据的传输 主要用于多线程数据共享 In 输入管道里面有一个存储区 Out 输出管道内有个In的引用 Connect之后,In指向了某个实际的 输入流 然后Out通过引用操作In里面的存储区 In自己的读方法也是操作这个存储区  |
| Pipe |
|
所以一旦理解了,JavaIO管道的模型,管道就实在是太简单了
|
| 只需要记住: 输入In里面 有一个存储缓冲区, 输出有一个引用指向了In connect将他们连接起来,他们共同操作一个池子 输出往里面写,输入从里面读 管子的方向只能是 : 输出 -----> 输入 |
文件
| 文件相关的,都是实实在在的要通过操作系统了 所以也就必然需要使用本地方法 在Java中一个文件使用File来描述,File是抽象路径名 可以表示文件 也可以表示目录 File可以通过String路径名构造 另外还有文件描述符可以表示指代文件 |
| File 磁盘数据 |
|

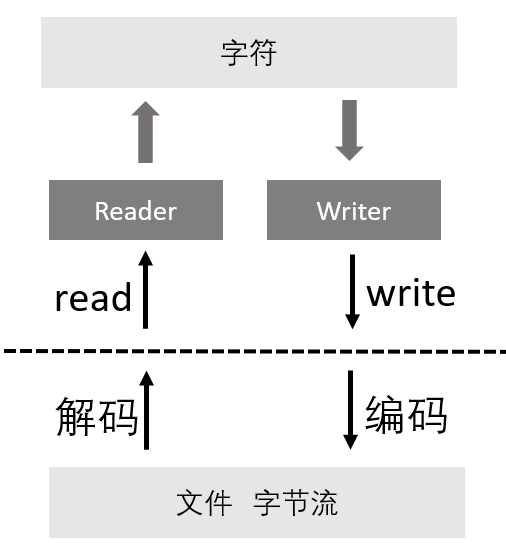
根据上面的说法,FileReader 和 FileWriter必然要是一种转换流
|
File
磁盘数据
|
|
关于FileReader 和FileWriter说了那么多
其实只有两句话,就是字节流与字符流之间进行转换
|
Reader reader = new InputStreamReader( new FileInputStream(.......));
Writer writer = new OutputStreamWriter( new FileOutputStream(.......));
|
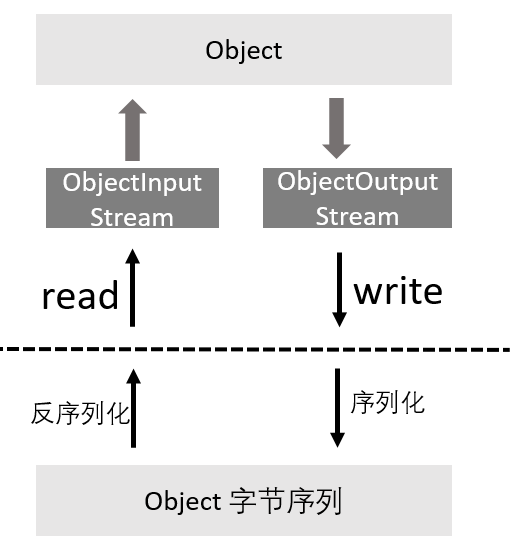
Object

功能的装饰扩展
既然是功能的装饰扩展,我们之前已经说过很多次,都是装饰器模式
也就是说了很多遍的
| 是你还有你,一切拜托你,中间增加点功能 |
这个你,就是需要被装饰的抽象角色Component
就是这四大家族 InputStream OutputStream Reader Writer
给读和写装饰增加新的功能,也就是最根本的读和写方法,将都是使用ConcreteComponent的
在基本的读和写方法之上,提供了新的功能
| Data |
|
缓冲的概念都是内部有一个缓冲区
缓冲输入 是通过底层的流往自己的缓冲区写入数据, 应用程序从缓冲输入的缓冲区中读取,提高了read速度
缓冲输出 是把数据写入到自己的缓冲区中,后续再把数据通过底层的流一并写入,从而提高了write的速度
因为读写都是从缓冲区中进行的了
| Buffered |
|
| LineNumberReader 内部使用了一个lineNumber = 0; 用来记录行号 这个行号可以使用方法设置和获取 getLineNumber setLineNumber 但是他不改变流的位置 |
PushBack
装饰器模式 方法依赖于被装饰的实体 ConcreteComponent
只是内部有一个缓冲区,可以存放被回退掉的字符
所有的读取方法在进行读取的时候,都会查看缓冲区的数据
| PushbackInputStream | 继承自FilterInputStream 得到一个InputStream 引用in 构造方法需要 InputStream 内部有缓冲区byte[] buf |
| FilterReader | 继承自FilterReader 得到一个Reader引用 in 构造方法需要一个Reader 内部有缓冲区char[] buf |
Print
提供了多种形式的打印,根本只是在真的写入数据前,将数据参数进行一些处理
根本的写操作 依赖被装饰的节点流提供
在数据写入之前进行必要的数据处理
| PrintStream | 继承自 FilterOutputStream得到一个OutputStream 引用 out 构造需要一个OutputStream |
| PrintWriter | 内部有一个out 构造方法需要一个Writer |
所以你看,扩展的功能通过装饰器模式,他们的行为都是类似的,那就是:
1. 最基本的读写依赖被装饰的具体的节点流
2. 然后进行了功能的增强
总结
说到这个地方,我们又从实现的角度把常用的一些流进行了介绍
你会发现看起来那么多,实际上并没有多少
四大家族,以及几种数据源形式,以及几个扩展功能点
只要找准了思路,理清楚了逻辑,就不难理解了
不知道到底是恍然大悟?还是?恍然如梦
?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}