

谈谈Java常用类库中的设计模式 - Part Ⅱ
概述
本文介绍的设计模式(建议按顺序阅读):
相关缩写:EJ - Effective Java
Here We Go
适配器 (Adapter)
定义:将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
场景:想使用现有的类,但此类的接口不符合已有系统的需要,同时双方不太容易修改;通过接口转换,将一个类插入到另一个类系中。
类型:结构型
适配器听起来像是一种亡羊补牢,仿佛使用了它就代表你承认了系统设计糟糕、不易扩展,所以才需要在两个类系之间增加中间者实现兼容。
但适配器真正的灵魂所在,是为一个事物提供多种 视角(perspective) 。
虽然 HashMap 快被讲烂了,但并不妨碍我们以 Design Pattern 的角度来欣赏 HashMap 中 Map::keySet 的实现细节。
/**
* Returns a {@link Set} view of the keys contained in this map.
* The set is backed by the map, so changes to the map are
* reflected in the set, and vice-versa. If the map is modified
* while an iteration over the set is in progress (except through
* the iterator's own <tt>remove</tt> operation), the results of
* the iteration are undefined. The set supports element removal,
* which removes the corresponding mapping from the map, via the
* <tt>Iterator.remove</tt>, <tt>Set.remove</tt>,
* <tt>removeAll</tt>, <tt>retainAll</tt>, and <tt>clear</tt>
* operations. It does not support the <tt>add</tt> or <tt>addAll</tt>
* operations.
*
* @return a set view of the keys contained in this map
*/
public Set<K> keySet() {
Set<K> ks = keySet;
if (ks == null) {
ks = new KeySet();
keySet = ks;
}
return ks;
}
final class KeySet extends AbstractSet<K> {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator<K> iterator() { return new KeyIterator(); }
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
}
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}
Map::keySet 是适配器模式的典型适用场景: HashMap 实现了 Map 接口,其与标准集合接口 Set 在继承层次(Map与Set)和数据结构(异构容器与同构容器)上大相径庭,它们代表着两个类系。
ketSet() 的职责是将键值对中的键抽出,组成一个 Set实例。
构造一个HashSet?循环add?
我们来看看 HashMap 是如何实现这一需求的:
观察代码可以发现,keySet() 本身逻辑十分简单,创建一个内部类 KeySet 的实例,并对其进行实例控制。
再来看看 KeySet 类的逻辑:一个继承自 AbstractSet的内部类。 AbstractSet 是实现了 Set 标准的骨架实现类 。继承它之后 KeySet 类只需实现剩下的基本类型接口就可称自己是一个 Set 了。那么这些接口是如何实现的呢?
size()-> 返回外部类的size字段,即键值对个数。
clear()-> 调用外部类clear()方法,即清空键值对数组。
iterator()-> 返回内部类KeyIterator实例,此类继承自通用迭代器HashIterator,重写next()返回下一元素的key字段。
contains()-> 调用外部类containsKey()方法。
remove()-> 调用外部类辅助方法removeNode(),即删除键值对。
针对 Set 所要求的接口能力, HashMap 最大限度地复用已有逻辑,在保持数据正确的前提下,将两个接口的职责建立映射。
再来看看上述代码片段中 keySet() 的JavaDoc注释。
Returns a {@link Set} view of the keys contained in this map.
The set is backed by the map, so changes to the map are
reflected in the set, and vice-versa.返回此map中包含的键的set视图。这个set是由map支撑的,所以对map的修改都会反映到set上,反之亦然。
不仅是 keySet(), values() 、 entrySet() 都使用了相同的适配器模式。这些适配器方法避免了为适应新标准而重新生成数据结构造成的浪费。
适配器的思路,就是对同一个对象建立多个视角,每一种视角下其特征、行为都不同,从而以更多维度来服务系统。
正所谓——
横看成岭侧成峰,远近高低各不同。
不识庐山真面目,只缘身在此山中。
模板方法 (Template Method)
定义:定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
场景:多个子类共有逻辑相同的方法;重要的、复杂的方法
类型:行为型
在上文适配器的介绍中引用了 HashMap的实现,其中介绍 KeySet 时提及到了 骨架实现类
的概念。而骨架实现类恰恰是模板模式的一种实践,本节以此为例。
首先复习一下Java的集合框架
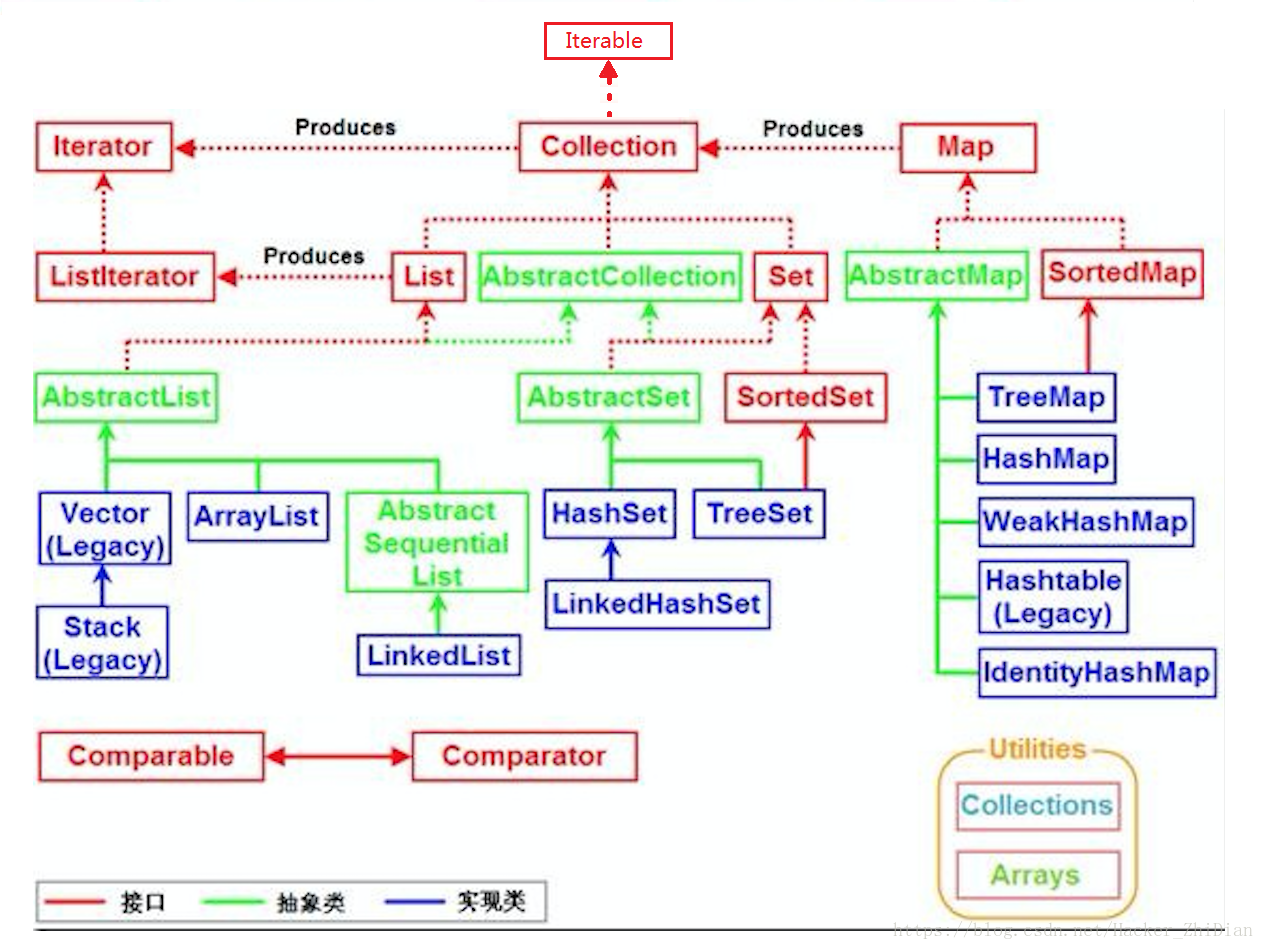
蓝色部分是我们熟知的各种集合实现,它们都继承自亮绿色部分、以Abstract开头命名的抽象类,这些类便称为骨架实现类,它们直接实现了 List 、 Set 、 Map等接口。
摘取一段EJ中关于骨架实现类的描述。
通过对接口提供一个抽象的骨架实现(skeletal implementation)类,可以把接口和抽象类的优点结合起来。接口负责定义类型,或许还提供一些缺省方法,而骨架实现类则负责实现除基本类型接口方法之外,剩下的非基本类型接口方法。扩展骨架实现占了实现接口之外的大部分工作。
什么是基本类型接口方法呢?对于这个冗长的命名,我理解就好比Java中万物皆对象,但所有对象最终的状态都要由基本类型来表示,组合对象也可看作是被封装好的基本类型之间进行组合。
换句话说,非基本类型接口方法可以凭借基本类型接口方法推导出自身的逻辑。这一点和接口的缺省方法十分相似。
比如这是List中排序接口的缺省方法。
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
这样,List的实现类只要保证toArray()、listIterator()这些基本类型接口方法行为正确,排序方法就隐式地被实现了。
再摘取AbstractList中的片段。
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
abstract public E get(int index);
public List<E> subList(int fromIndex, int toIndex) {
return (this instanceof RandomAccess ?
new RandomAccessSubList<>(this, fromIndex, toIndex) :
new SubList<>(this, fromIndex, toIndex));
}
class SubList<E> extends AbstractList<E> {...}
class RandomAccessSubList<E> extends SubList<E> implements RandomAccess {...}
}
AbstractList中的实现更趋于完整,已经通过编写辅助内部类将迭代器、子列表等功能进行了实现。
接口-缺省方法 与 骨架实现类-非基本类型接口方法 都是可根据其他方法推演自身逻辑的方法,那它们之间的区别在哪呢?不如把骨架实现类中的代码搬到接口当中!然而这样是不妥的,它们之间还是有区别的。
骨架实现类为抽象类提供了实现上的帮助,但又不强加“抽象类被用作类型定义时”所特有的严格限制。 如果预置的类无法扩展骨架实现类,这个类始终都可以手工实现这个接口,同时仍然受益于接口的缺省方法。
接口定义了整个类系的类型,缺省方法是针对这一批类型的通解;而骨架实现类是接口的某一种实现方案,它趋于完整,方便最终实现类的编写,但不一定是最佳方案,所以不能绑定到整个类系之上。
无论是缺省方法,还是骨架实现类,都是模板方法的实践,通过定义模板、继承模板,可以让开发者专注于关键逻辑,同时也能随意覆盖模板,让子类实现高效又灵活。
装饰器 (Decorator)
定义:动态地将一个对象添加一些额外的职责,就添加功能来说,装饰模式比生成子类更为灵活。
场景:在不想增加很多子类的情况下扩展类;动态增加功能,动态撤销。
类型:结构型
复合优先于继承,这是EJ中提到装饰器时的Tip标题,它很好的表达了装饰器出现的原因。
继承是实现代码重用的强大工具,但并非总是最佳工具,其中一个原因是:继承破坏了封装性。
换句话说,子类依赖于其超类中特定功能的实现细节。超类的实现有可能会随着发行版本的不同而有所变化,如果真的发生了变化,子类可能会遭到破坏,即使它的代码完全没有改变。
这里所讲的变化可以是以下任意一种:
- 父类的方法在类内互相调用,这种 自用性 (self-use) 是实现细节,开发者可能会认为方法之间是独立的,如果覆盖某个被依赖的方法,依赖方也会受影响,并且在未来的发行版本中这种依赖关系是变化的、不稳定的。
- 子类对所有方法加入了一种先决条件,例如验参,父类如果在后续的发行版本添加新的方法,就会成为“漏网之鱼”,造成安全问题。
- 在新的发行版本中父类编写了一个新方法,恰好与某个子类的新增方法签名冲突,造成编译失败。
- ···
总而言之,倘若不是专门为了继承而设计并且具有很好的文档说明的类,在多人协作,特别是跨越包边界时(泛指不再对子类编写、迭代的规范有强约束力)使用继承非常危险,会让系统变得更加脆弱。
所幸有一种方法可以避免继承的种种问题,即 复合-转发。
不扩展现有的类,而是在新的类中增加私有域,引用现有类的一个实例,这种设计被称为 “复合”(composition) ;
新类中每个实例方法都可以调用被包含的现有类实例中对应的方法,并返回他的结果,这被称为 “转发”(forwarding) 。
我们还是来看集合框架中的一个典型例子(今天跟集合框架杠上了...
public class Collections {
public static <K, V> Map<K, V> checkedMap(Map<K, V> m,
Class<K> keyType,
Class<V> valueType) {
return new CheckedMap<>(m, keyType, valueType);
}
private static class CheckedMap<K,V> implements Map<K,V>, Serializable {
private final Map<K, V> m;
final Class<K> keyType;
final Class<V> valueType;
CheckedMap(Map<K, V> m, Class<K> keyType, Class<V> valueType) {
this.m = Objects.requireNonNull(m);
this.keyType = Objects.requireNonNull(keyType);
this.valueType = Objects.requireNonNull(valueType);
}
public int size() { return m.size(); }
public boolean isEmpty() { return m.isEmpty(); }
public boolean containsKey(Object key) { return m.containsKey(key); }
public boolean containsValue(Object v) { return m.containsValue(v); }
public V get(Object key) { return m.get(key); }
public V remove(Object key) { return m.remove(key); }
public void clear() { m.clear(); }
public Set<K> keySet() { return m.keySet(); }
public Collection<V> values() { return m.values(); }
public boolean equals(Object o) { return o == this || m.equals(o); }
public int hashCode() { return m.hashCode(); }
public String toString() { return m.toString(); }
public V put(K key, V value) {
typeCheck(key, value);
return m.put(key, value);
}
private void typeCheck(Object key, Object value) {
if (key != null && !keyType.isInstance(key))
throw new ClassCastException(badKeyMsg(key));
if (value != null && !valueType.isInstance(value))
throw new ClassCastException(badValueMsg(value));
}
//省略剩余方法
}
}
这回介绍的是Collections::checkedMap,这个静态工厂使用不多,其作用是为map实例提供键值对类型检查。现如今Map接口已是一个泛型,但在JAVA SE5之前编写的各类map实现,是没有类型检查的能力的。当我们不能去改造老的类库时,只需一句简单的调用:
Map<Integer, String> typeSafeMap = Collections.checkedMap(new OldMap(), Integer.class, String.class);
即可为老类库赋予和泛型一样的类型检查能力,我们来细品代码。
静态工厂中返回了 CheckedMap 的新实例, CheckedMap 是实现了 Map 接口的内部类,定义了私有变量 Map 用于接收map实例;两个 Class 字段,分别保存键值的类型。对于大多数方法, CheckedMap 直接将调用 转发 至原map上,但在 put 这样的插入操作中,在转发前调用了私有的 typeCheck 方法,执行类型检查。
避开继承,使用装饰器,我们同样能为现有类追加新的功能。同时装饰器本身还可以再次被装饰,这使得装饰器是动态的、可拆卸的。
例如对现有类同时赋予 类型安全、线程安全 的特性。
Map<Integer, String> safeMap = Collections.synchronizedMap(
Collections.checkedMap(new OldMap(), Integer.class, String.class)
);
装饰器本身也有编写成本,因为需要将所有方法进行转发,但往往需要装饰的方法较少。 Guava 做了这方面考虑,在collect包下为所有集合接口编写了转发类,类名格式:ForwardingXXX。开发者只需继承这些转发类,重写需要装饰的方法即可。
参考:
[1] Effective Java - 机械工业出版社 - Joshua Bloch (2017/11)
[2] 《大话设计模式》 - 清华大学出版社 - 陈杰 (2007/12)

