WeakHashMap源码阅读
本人的源码阅读主要聚焦于类的使用场景,一般只在java层面进行分析,没有深入到一些native方法的实现。并且由于知识储备不完整,很可能出现疏漏甚至是谬误,欢迎指出共同学习
本文基于corretto-17.0.9源码,参考本文时请打开相应的源码对照,否则你会不知道我在说什么
简介
了解过WeakReference这个类的都知道,当WeakReference引用的对象不再被强引用时就会被GC回收,此时在若引用上尝试获取对象会返回null。WeakHashMap就利用了弱引用的这个特性,将键保存在弱引用中,当键不再被强引用的时候,尝试获取entry上的键就会返回null,然后WeakHashMap就会自动清除这个entry以节省内存。
模型
就哈希表结构上来说,与HashMap一样用的是拉链法来解决冲突,但WeakHashMap没有使用红黑树桶来优化单个桶元素较多的情况,只是拉成简单的单链表,图中实线箭头代表链表的指针:
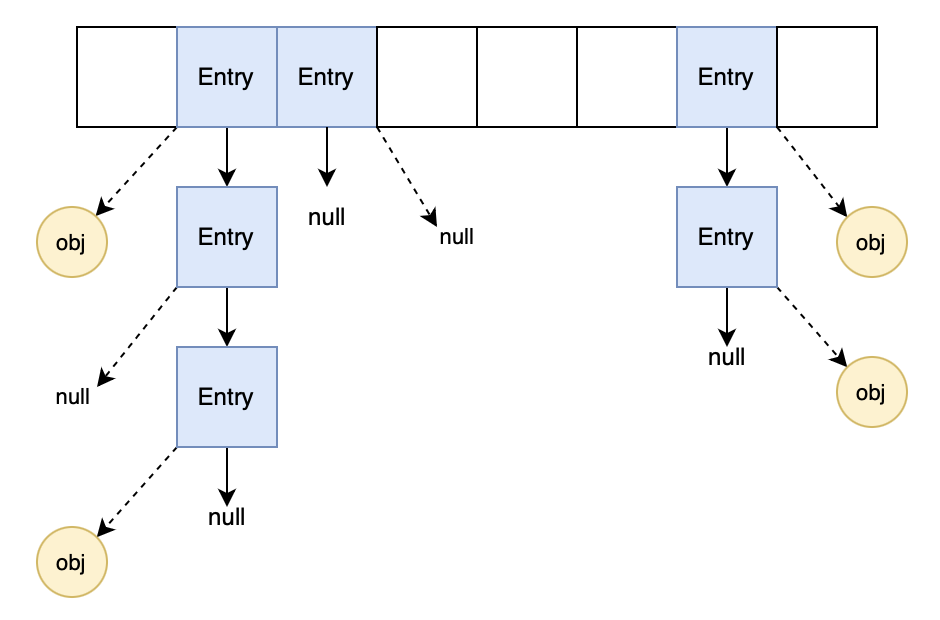
Entry就是一个键值对,也称为一个节点(HashMap中命名为Node),Entry继承自WeakReference,并且将key保存在父类,因此图中我用虚线箭头指向弱引用的key对象,如果对象已经被GC,则指向null。图中空白的正方形格子表示该位置存储null,即空桶。
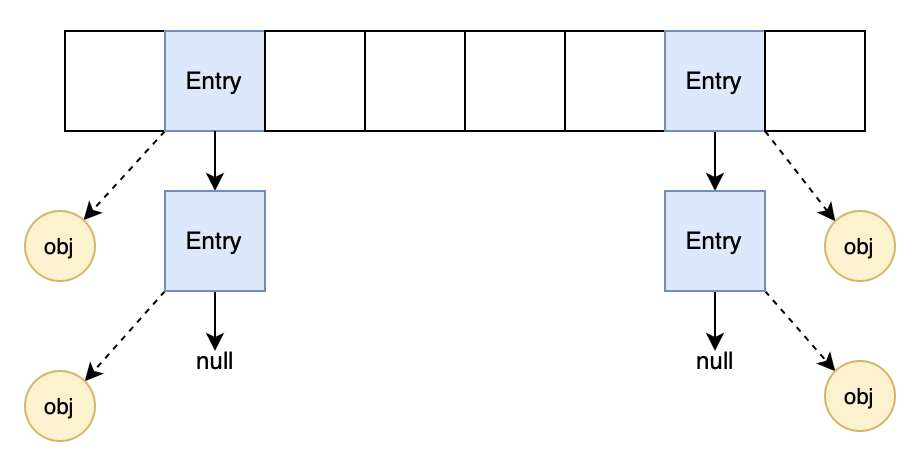
弱引用指向null的节点称为无效节点,虽然指向的对象被GC了,但是节点本身也是一个对象,因此无效节点的清除由WeakHashMap负责。比如经过一轮清除后变成如下:
代码分析
成员变量
public class WeakHashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V> {
// 哈希表
Entry<K,V>[] table;
// 已被清除的entry集合
private final ReferenceQueue<Object> queue = new ReferenceQueue<>();
}
成员变量几乎跟HashMap一样,就不全部列出。相比HashMap只新增了一个queue,在构造WeakReference的时候将这个队列传进构造函数中,当被引用对象被GC的时候就会将弱引用(注意不是被引用对象,而是WeakReference对象)自动入队到这个队列,WeakHashMap就可以使用它来清理table中无效节点。
WeakHashMap的节点本身就是弱引用,继承自WeakReference:
private static class Entry<K,V> extends WeakReference<Object> implements Map.Entry<K,V> {
V value;
final int hash;
WeakHashMap.Entry<K,V> next;
Entry(Object key, V value,
ReferenceQueue<Object> queue,
int hash, WeakHashMap.Entry<K,V> nex t) {
// 注意这行
super(key, queue);
this.value = value;
this.hash = hash;
this.next = next;
}
public K getKey() {
return (K) WeakHashMap.unmaskNull(get());
}
public V getValue() {
return value;
}
public V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
相比HashMap.Entry,WeakHashMap.Entry将key交给了父类来保存,相当于key是被弱引用引用的,获取key的时候通过调用父类的get来获取。这样就能做到当键不再被外界强引用时,Entry.getKey返回null。而Entry的其他的成员比如hash、value等都由Entry自身保存(强引用),因此用户需要保证value不会对key强引用,否则key永远不会自动被清除。
构造函数就不说了,与HashMap没什么差别,直接看增删改查,首先是get:
// 获取key对应的value,如果key在此之前已经不被强引用,那么可能已经被清除。
public V get(Object key) {
// WeakHashMap允许null key,因此如果key为null的话要转换成NULL_KEY,与弱引用对象被GC时得到的null区分开来
Object k = maskNull(key);
int h = hash(k);
// getTable简单返回table,不过在返回前会清除无效节点
WeakHashMap.Entry<K,V>[] tab = getTable();
int index = indexFor(h, tab.length);
WeakHashMap.Entry<K,V> e = tab[index];
// 搜索桶(遍历单链表)
while (e != null) {
if (e.hash == h && matchesKey(e, k))
return e.value;
e = e.next;
}
return null;
}
get流程比较简单,需要注意的点已经在注释中注明,不过函数matchKey可以看一下,其功能是检查弱引用是否引用了传入的键:
private boolean matchesKey(Entry<K,V> e, Object key) {
// 如果是同一个对象
if (e.refersTo(key)) return true;
// 如果equals返回true
Object k = e.get();
return k != null && key.equals(k);
}
WeakReference.refersTo功能是检查传入的对象与弱引用的对象是否是同一个,不用get() == obj的原因在于get返回对象的强引用,对GC不友好。如果你只是想检测一下,并不想要返回强引用的话,refersTo是最佳选择。Map键的唯一性是基于equals的,如果refersTo返回false只能说明不是同一个对象,而这两个对象equals可能成立。
WeakReference.refersTo在之前ThreadLocals源码阅读一文中也有提到过。
下面继续看put方法:
public V put(K key, V value) {
/***** 获取桶下标 *****/
Object k = maskNull(key);
int h = hash(k);
WeakHashMap.Entry<K,V>[] tab = getTable();
int i = indexFor(h, tab.length);
/***** 如果桶中已存在key,则直接更新其value *****/
for (WeakHashMap.Entry<K,V> e = tab[i]; e != null; e = e.next) {
if (h == e.hash && matchesKey(e, k)) {
V oldValue = e.value;
if (value != oldValue)
e.value = value;
return oldValue;
}
}
/***** 将新节点头插到链表 *****/
modCount++;
WeakHashMap.Entry<K,V> e = tab[i];
tab[i] = new WeakHashMap.Entry<>(k, value, queue, h, e);
// 哈希表扩容
if (++size >= threshold)
resize(tab.length * 2);
return null;
}
简单,不说,继续看remove:
public V remove(Object key) {
Object k = maskNull(key);
int h = hash(k);
WeakHashMap.Entry<K,V>[] tab = getTable();
int i = indexFor(h, tab.length);
// 被删除节点的前驱
WeakHashMap.Entry<K,V> prev = tab[i];
// 被删除的节点
WeakHashMap.Entry<K,V> e = prev;
while (e != null) {
// 被删除节点的后继
WeakHashMap.Entry<K,V> next = e.next;
if (h == e.hash && matchesKey(e, k)) {
modCount++;
size--;
if (prev == e)
tab[i] = next;
else
prev.next = next;
return e.value;
}
prev = e;
e = next;
}
return null;
}
简单,其实就是链表节点的删除操作。
至此,最基本的增删改查已经过完一遍,比HashMap还要简单(因为少了红黑树),没什么特别的地方。而且弱引用所引用的对象也会被自动GC,因此WeakHashMap要负责无效弱引用本身从表中清除:
// 清除哈希表中所有无效弱引用(无效节点,即getKey返回null的Entry)
private void expungeStaleEntries() {
// 遍历引用队列queue中所有无效节点
for (Object x; (x = queue.poll()) != null; ) {
synchronized (queue) {
WeakHashMap.Entry<K,V> e = (WeakHashMap.Entry<K,V>) x;
int i = indexFor(e.hash, table.length);
WeakHashMap.Entry<K,V> prev = table[i];
WeakHashMap.Entry<K,V> p = prev;
// 从桶中找到该节点并从链表中断开
while (p != null) {
WeakHashMap.Entry<K,V> next = p.next;
if (p == e) {
if (prev == e)
table[i] = next;
else
prev.next = next;
// Must not null out e.next;
// stale entries may be in use by a HashIterator
e.value = null; // Help GC
size--;
break;
}
prev = p;
p = next;
}
}
}
}
简单,不分析。不过要注意里面没有为了“Help GC”将被删除节点的next也置空,因为迭代器可能刚好遍历到这个节点,置空的话会导致遍历不到后续节点。expungeStaleEntries会在三个地方被调用:getTable()、size()、resize()
再看看扩容:
void resize(int newCapacity) {
WeakHashMap.Entry<K,V>[] oldTable = getTable();
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 创建新表并将旧表rehash(transfer)到新表
WeakHashMap.Entry<K,V>[] newTable = newTable(newCapacity);
transfer(oldTable, newTable);
table = newTable;
// 在rehash后如果size减小到threshold/2以下的话,将所有节点再放回旧表
if (size >= threshold / 2) {
threshold = (int)(newCapacity * loadFactor);
} else {
expungeStaleEntries();
transfer(newTable, oldTable);
table = oldTable;
}
}
// 将src表中所有节点rehash到dest表,并在这个过程中会检查无效节点并清理这些节点,使得size减小
private void transfer(WeakHashMap.Entry<K,V>[] src, WeakHashMap.Entry<K,V>[] dest) {
for (int j = 0; j < src.length; ++j) {
WeakHashMap.Entry<K,V> e = src[j];
src[j] = null;
while (e != null) {
WeakHashMap.Entry<K,V> next = e.next;
if (e.refersTo(null)) {
e.next = null; // Help GC
e.value = null; // " "
size--;
} else {
int i = indexFor(e.hash, dest.length);
e.next = dest[i];
dest[i] = e;
}
e = next;
}
}
}
扩容很有意思的一点是,rehash的过程中会检查无效节点并清理这些节点,使得size减小。rehash完后size如果小到一定程度的话,会认为没必要做这个扩容,然后将所有元素再rehash回旧表,以节省内存。
以上就是核心方法,迭代器什么的就不说了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号