LinkedHashMao & LinkedHashSet源码阅读
本人的源码阅读主要聚焦于类的使用场景,一般只在java层面进行分析,没有深入到一些native方法的实现。并且由于知识储备不完整,很可能出现疏漏甚至是谬误,欢迎指出共同学习
本文基于corretto-17.0.9源码,参考本文时请打开相应的源码对照,否则你会不知道我在说什么
简介
LinkedHashMap继承于HashMap,在看本篇之前需要先看过HashMap & HashSet源码阅读。相比HashMap,LinkedHashMap增加了一个特性:迭代顺序与插入顺序相同,没别的。
模型
这个小节主要介绍如何做到在HashMap的基础上,让元素的迭代顺序与他们的插入顺序相同。其实主要是修改了节点,在HashMap.Node的基础上,LinkedHashMap添加了两个指针before和after,before指向上一个被插入的节点,after指向下一个插入的节点:
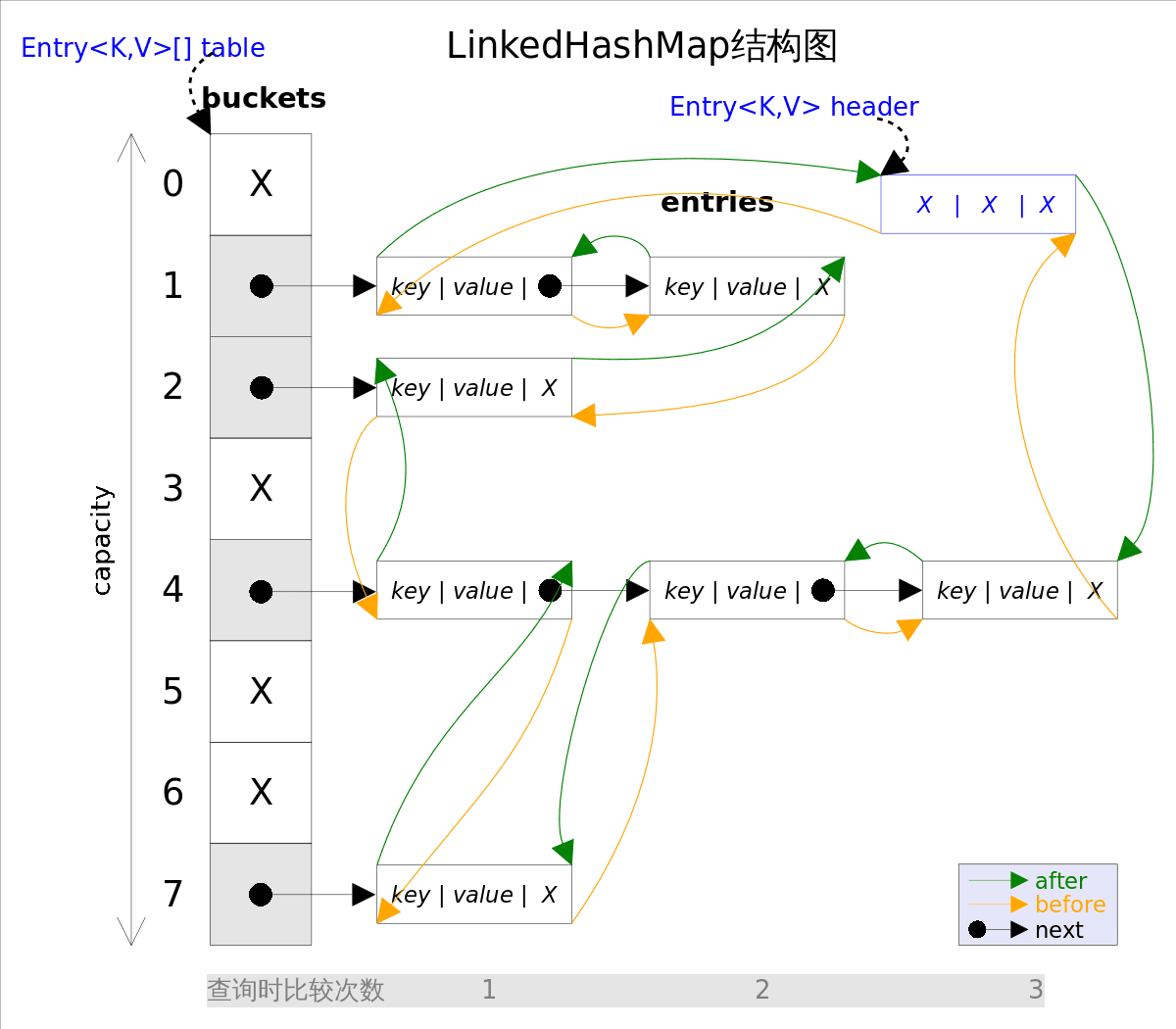
千万别将before/after和next/prev这两对指针搞混了,前者是将哈希表所有节点按照插入的顺序依次连接起来,形成一个全局的链表;而后者是将桶中的节点连接起来,形成一个局部的链表。
LinkedHashMap只需要维护一个指针tail,指向最新插入哈希表的节点,在下次插入的时候,采用尾插法将其链到tail之后。
而对于迭代,LinkedHashMap还需再维护一个指针head,指向最老插入哈希表的节点,从这个节点开始遍历这个全局链表,就能做到“迭代顺序与插入顺序相同”。
明白了模型之后,代码分析其实也就很简单。
代码分析
成员变量
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
static class Entry<K,V> extends HashMap.Node<K,V> {
// before指向上一个插入哈希表的节点,after指向下一个插入哈希表的节点
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
// 指向最新插入哈希表的节点
transient java.util.LinkedHashMap.Entry<K,V> head;
// 指向最老插入哈希表的节点
transient java.util.LinkedHashMap.Entry<K,V> tail;
// 按照插入顺序还是访问顺序迭代
final boolean accessOrder;
}
除了accessOrder外,在模型都提到过,不再赘述。在模型中说的是“迭代顺序与插入顺序相同”,其实LinkedHashMap还支持“迭代顺序与访问顺序相同”,所谓“访问”指的是key在哈希表已经存在,get或put都算访问,当然,访问模式下插入新节点的话,与插入模式的行为相同。两种模式的区别在于,插入模式下访问已经存在的key不会改变其迭代顺序。
在开始分析实现前,可以猜一下访问模式是如何实现的。我猜应该是将被访问的节点从链表断开,然后重新插入到链表尾...
方法
构造方法没什么可介绍的,直接看核心方法。核心方法是在HashMap中定义的三个钩子函数:
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
之前在介绍HashMap的方法时候,可以看到put、remove等方法实现里调用了这三个方法。这是一种名为 模版模式 的设计模式:定义一个操作中的算法的骨架(这里是HashMap的put、get等),而将一些步骤延迟到子类中(钩子函数)。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
通过「模型」这个小节可以知道,LinkedHashMap要维护一个全局链表(节点是LinkedHashMap.Entry),因此这三个方法就是为了在增删改查节点后用来更新全局链表。由于比较简单,下面一次性通过代码注释解析:
// 节点被删除后
void afterNodeRemoval(HashMap.Node<K,V> e) {
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
// 更新head和被删节点前驱的after
if (b == null)
head = a;
else
b.after = a;
// 更新head和被删节点后继的before
if (a == null)
tail = b;
else
a.before = b;
}
// 新节点插入后
void afterNodeInsertion(boolean evict) {
LinkedHashMap.Entry<K,V> first;
// 移除最老的节点,是否移除与removeEldestEntry有关
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
// 节点访问后
void afterNodeAccess(HashMap.Node<K,V> e) {
LinkedHashMap.Entry<K,V> last;
// 如果是访问模式并且访问的不是尾节点,那么要将该节点从全局链表断开,并重新插入链表尾
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 下面都是链表操作,比较简单不说了
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
值的注意的是afterNodeInsertion中有一个删除最老节点的操作,这个是为了实现LRU/FIFO缓存算法。首先LRU删除的是最老的(最久未被使用)节点,并且LinkedHashMap确实也支持找到最老的节点,因此多了这个“删除最老节点”的操作,但LinkedHashMap默认是不会删除最老节点的,也就是removeEldestEntry返回false,这样就跟普通的Map一样,存多少就是多少:
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
用户可以继承LinkedHashMap,并重写这个方法来实现一个KV缓存类,比如下面实现了一个基于LRU策略的键值对缓存(代码来自com.mysql.cj.util.LRUCache,随手拿来作为例子):
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
protected int maxElements;
// maxSize为哈希表可存储最多的键值对,当键值对超过maxSize时,最老的键会被自动删除
public LRUCache(int maxSize) {
super(maxSize, 0.75F, true); // 注意第三个参数传accessOrder传true,否则就变成FIFOCache了
this.maxElements = maxSize;
}
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return this.size() > this.maxElements;
}
}
至于LinkedHashMap的其他方法没什么好分析,迭代器呢,很明显就是从head开始顺着after往后遍历,也没啥好讲,不过迭代性能是比HashMap好点的,因为HashMap是遍历整个table,相当于遍历所有桶,包括空桶。而LinkedHashMap是遍历全局链表,迭代时间就只跟size(实际节点的个数)相关,而跟table.length无关。
补充 - LinkedHashSet
参考HashMap & HashSet源码阅读中介绍的HashSet与HashMap的关系。
总结
LinkedHashMap在HashMap的基础上,根据节点插入/访问的先后顺序将所有节点用双指针串起来,实现了迭代顺序与插入/访问的顺序相同的特性。另外,因为LinkedHashMap可以直接获取到最老的节点,因此进一步支持用户通过继承LinkedHashMap实现键值对缓存。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号