Http请求时URL中的中文编码
Http请求时,URL中作为参数值的中文字符等会被编码
1、处理编码思路:
注意:[在浏览器上访问时,每个空格会被转码为 %20 ,URLencode会将每个空格转码为 + ]
URLEncode的转码会将一些不需要转码的字符也进行转码(例如不是参数值的& : /等)
1.对于需要的参数先进行编码。(如果是get请求可以先使用URLEncode编码后进行URL的拼接)
2.对URL进行截取,然后统一编码,将特殊字符编码后替换回来(路径中的& / : 当其作为参数值的时候需要转码,否
则不能被转码);此方法弊端:当& 和 / 作为参数值时需要被转码,不好处理。
2、一些常见字符被URLEncode转码后的值(中文字符会被转码为 以%E开头,长度为9的字符串)
英文 ? 编码后 : %3F
/ 编码后:%2F
% 编码后:%25
中文? 编码后:%EF%BC%9F
单个空格 编码后:+ (在浏览器上访问时,每个空格会被转码为 %20 ,URLencode会将
每个空格转码为 +;可以转码后将其中的 + 用 %20替换掉 )
+ 编码后:%2B
英文 : 编码后:%3A
中文 : 编码后:%EF%BC%9A
& 编码后:%26
3、简单的拼接demo(存在不足之处)
public static void main(String[] args) {
//被转码后的url
String result = "";
//需要转码的url
String url = "https://www.baidu.com/s?wd=语 文 ?&rsv_spt=1"
+ "&rsv_iqid=0xd13fd9040001fb1d&issp=1&f=8&rsv_bp=0"
+ "&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_sug3=2"
+ "&rsv_sug1=2&rsv_sug7=101&rsv_sug2=0&inputT=774&rsv_sug4=1367 &AAAA=1";
int index = url.indexOf("?");
result = url.substring(0,index+1);
String temp = url.substring(index+1);
try {
//URLEncode转码会将& : / = 等一些特殊字符转码,(但是这个字符 只有在作为参数值 时需要转码;例如url中的&具有参数连接的作用,此时就不能被转码)
String encode = URLEncoder.encode(temp, "utf-8");
System.out.println(encode);
encode = encode.replace("%3D", "=");
encode = encode.replace("%2F", "/");
encode = encode.replace("+", "%20");
encode = encode.replace("%26", "&");
result += encode;
System.out.println("转码后的url:"+result);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
编码前地址:http://hi.baidu.com/test/?a=张三&b=_a123&c=+abc
编码后地址:http://hi.baidu.com/test/?a=%E5%BC%A0%E4%B8%89&b=_a123&c=+abc (中文字符已被转码)
字符对应的值:
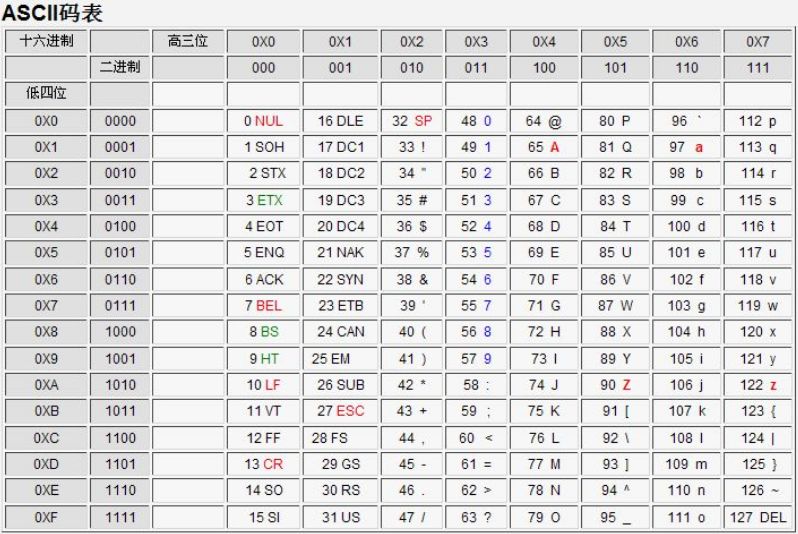
/ → 47 a-z → 97~122 A-Z → 65~90 : → 58 % → 37
中文字符对应的值是大于255的
char c = '我';
System.out.println((int)c) / /可以查看对应的数值
在字符编码方面,ASCII码为标准符号、数字、英文等进行了保留,取值范围是0~127,还有一部分作为扩展ASCII码128~255
当操作系统采用非ASCII编码时(比如汉字编码),一般用扩展ASCII码来进行,约定用128~255范围的编码连续2~3甚至4个来进
行汉字编码,(比如国标用连续两个128~255的编码表示1个汉字,分别是区码和位码的编码;UTF-8可以用3个连续的数来表示一
个汉字),具体编码规则要看具体定义,一般不相同的。因此,在处理字符串时,如果是有符号字符串,遇到小于0的字符,会结合
后面紧跟的字符来组成一个汉字,大于0的为标准西文字符;如果是无符号的,则可以判断是否大于127。