

pandas和numpy学习
1.导入:
1 import numpy as np 2 import pandas as pd
原始文件:
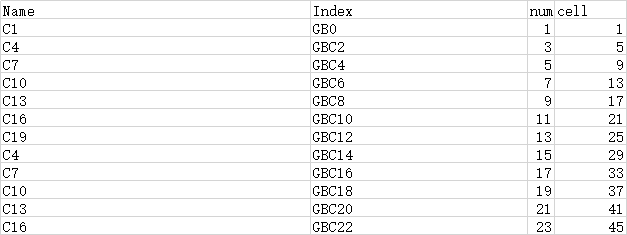
1 xlsx=pd.ExcelFile('1.xlsx') 2 df=pd.read_excel(xlsx,0,index_col=None,na_values=['NA']) 3 print(df.head())


C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/txt.py Name Index num cell 0 C1 GB0 1 1 1 C4 GBC2 3 5 2 C7 GBC4 5 9 3 C10 GBC6 7 13 4 C13 GBC8 9 17 Process finished with exit code 0
2.数据筛选和选择:
1 print(df.shape) 2 print("*"*111) 3 print(df.index) 4 print("*"*111) 5 print(df.index.values) 6 print("*"*111) 7 print(df.columns) 8 print("*"*111) 9 print(df.columns.values) 10 print("*"*111) 11 print(df.columns.get_loc("num")) 12 print("*"*111) 13 print(df.columns.get_indexer(["num","cell"])) 14 print("*"*111) 15 print(df["num"]) 16 print("*"*111) 17 print(df[["num","cell"]]) 18 print("*"*111) 19 print(df[["num","cell"]].values) 20 print("*"*111) 21 print(df.iloc[2:6]) 22 print("*"*111) 23 print(df.iloc[2:6,2:4]) 24 print("*"*111) 25 print(df.iloc[2:6,df.columns.get_indexer(["cell","num"])]) 26 print("*"*111) 27 print(df.loc[2:6,["cell","num"]]) 28 print("*"*111) 29 print(df.loc[2:6,"num":"cell"]) 30 print("*"*111) 31 print(df.loc[2:8:2,["cell","num"]]) 32 print("*"*111) 33 print(df[(df["cell"]==9)|(df["num"]==9)]) 34 print("*"*111) 35 print(df[(df["num"]==9)|(df["num"]==1)]) 36 print("*"*111) 37 print(df.loc[df["num"]<7]) 38 print("*"*111) 39 print(df.loc[df.num<7,['cell','num']])
结果:
C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/txt.py (12, 4) *************************************************************************************************************** RangeIndex(start=0, stop=12, step=1) *************************************************************************************************************** [ 0 1 2 3 4 5 6 7 8 9 10 11] *************************************************************************************************************** Index(['Name', 'Index', 'num', 'cell'], dtype='object') *************************************************************************************************************** ['Name' 'Index' 'num' 'cell'] *************************************************************************************************************** 2 *************************************************************************************************************** [2 3] *************************************************************************************************************** 0 1 1 3 2 5 3 7 4 9 5 11 6 13 7 15 8 17 9 19 10 21 11 23 Name: num, dtype: int64 *************************************************************************************************************** num cell 0 1 1 1 3 5 2 5 9 3 7 13 4 9 17 5 11 21 6 13 25 7 15 29 8 17 33 9 19 37 10 21 41 11 23 45 *************************************************************************************************************** [[ 1 1] [ 3 5] [ 5 9] [ 7 13] [ 9 17] [11 21] [13 25] [15 29] [17 33] [19 37] [21 41] [23 45]] *************************************************************************************************************** Name Index num cell 2 C7 GBC4 5 9 3 C10 GBC6 7 13 4 C13 GBC8 9 17 5 C16 GBC10 11 21 *************************************************************************************************************** num cell 2 5 9 3 7 13 4 9 17 5 11 21 *************************************************************************************************************** cell num 2 9 5 3 13 7 4 17 9 5 21 11 *************************************************************************************************************** cell num 2 9 5 3 13 7 4 17 9 5 21 11 6 25 13 *************************************************************************************************************** num cell 2 5 9 3 7 13 4 9 17 5 11 21 6 13 25 *************************************************************************************************************** cell num 2 9 5 4 17 9 6 25 13 8 33 17 *************************************************************************************************************** Name Index num cell 2 C7 GBC4 5 9 4 C13 GBC8 9 17 *************************************************************************************************************** Name Index num cell 0 C1 GB0 1 1 4 C13 GBC8 9 17 *************************************************************************************************************** Name Index num cell 0 C1 GB0 1 1 1 C4 GBC2 3 5 2 C7 GBC4 5 9 *************************************************************************************************************** cell num 0 1 1 1 5 3 2 9 5 Process finished with exit code 0
按照行列遍历
1 import numpy as np 2 import pandas as pd 3 xlsx=pd.ExcelFile('1.xlsx') 4 df=pd.read_excel(xlsx,0,index_col=None,na_values=['NA']) 5 print(df) 6 print("*"*111) 7 #三种迭代函数,interrows()返回(index,Series)行对 8 for index,row in df.iterrows(): 9 print(index,'\n',row) 10 print("*"*111) 11 #返回本身就是一个series,可以按照series的情况提取具体元素 12 for index,row in df.iterrows(): 13 print(row[2:3]) 14 print("*"*111) 15 #interitems()返回(column,series)列对 16 for index,col in df.iteritems(): 17 print(col[2:3]) 18 print("*"*111) 19 #以上方式遍历不能对数据进行修改,要对数据进行修改,数据小的话直接按照行数遍历修改 20 #如果很大,建议使用apply函数或者转为list进行处理 21 for i in df.index: 22 print(df.loc[i,:]) 23 print("*"*111) 24 # 也可以用shape[0]表示行数 25 for i in range(df.shape[0]): 26 print(df.loc[i,:])
结果:
C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/txt.py Name Index num cell 0 C1 GB0 1 1 1 C4 GBC2 3 5 2 C7 GBC4 5 9 3 C10 GBC6 7 13 4 C13 GBC8 9 17 5 C16 GBC10 11 21 6 C19 GBC12 13 25 7 C4 GBC14 15 29 8 C7 GBC16 17 33 9 C10 GBC18 19 37 10 C13 GBC20 21 41 11 C16 GBC22 23 45 *************************************************************************************************************** 0 Name C1 Index GB0 num 1 cell 1 Name: 0, dtype: object 1 Name C4 Index GBC2 num 3 cell 5 Name: 1, dtype: object 2 Name C7 Index GBC4 num 5 cell 9 Name: 2, dtype: object 3 Name C10 Index GBC6 num 7 cell 13 Name: 3, dtype: object 4 Name C13 Index GBC8 num 9 cell 17 Name: 4, dtype: object 5 Name C16 Index GBC10 num 11 cell 21 Name: 5, dtype: object 6 Name C19 Index GBC12 num 13 cell 25 Name: 6, dtype: object 7 Name C4 Index GBC14 num 15 cell 29 Name: 7, dtype: object 8 Name C7 Index GBC16 num 17 cell 33 Name: 8, dtype: object 9 Name C10 Index GBC18 num 19 cell 37 Name: 9, dtype: object 10 Name C13 Index GBC20 num 21 cell 41 Name: 10, dtype: object 11 Name C16 Index GBC22 num 23 cell 45 Name: 11, dtype: object *************************************************************************************************************** num 1 Name: 0, dtype: object num 3 Name: 1, dtype: object num 5 Name: 2, dtype: object num 7 Name: 3, dtype: object num 9 Name: 4, dtype: object num 11 Name: 5, dtype: object num 13 Name: 6, dtype: object num 15 Name: 7, dtype: object num 17 Name: 8, dtype: object num 19 Name: 9, dtype: object num 21 Name: 10, dtype: object num 23 Name: 11, dtype: object *************************************************************************************************************** 2 C7 Name: Name, dtype: object 2 GBC4 Name: Index, dtype: object 2 5 Name: num, dtype: int64 2 9 Name: cell, dtype: int64 *************************************************************************************************************** Name C1 Index GB0 num 1 cell 1 Name: 0, dtype: object Name C4 Index GBC2 num 3 cell 5 Name: 1, dtype: object Name C7 Index GBC4 num 5 cell 9 Name: 2, dtype: object Name C10 Index GBC6 num 7 cell 13 Name: 3, dtype: object Name C13 Index GBC8 num 9 cell 17 Name: 4, dtype: object Name C16 Index GBC10 num 11 cell 21 Name: 5, dtype: object Name C19 Index GBC12 num 13 cell 25 Name: 6, dtype: object Name C4 Index GBC14 num 15 cell 29 Name: 7, dtype: object Name C7 Index GBC16 num 17 cell 33 Name: 8, dtype: object Name C10 Index GBC18 num 19 cell 37 Name: 9, dtype: object Name C13 Index GBC20 num 21 cell 41 Name: 10, dtype: object Name C16 Index GBC22 num 23 cell 45 Name: 11, dtype: object *************************************************************************************************************** Name C1 Index GB0 num 1 cell 1 Name: 0, dtype: object Name C4 Index GBC2 num 3 cell 5 Name: 1, dtype: object Name C7 Index GBC4 num 5 cell 9 Name: 2, dtype: object Name C10 Index GBC6 num 7 cell 13 Name: 3, dtype: object Name C13 Index GBC8 num 9 cell 17 Name: 4, dtype: object Name C16 Index GBC10 num 11 cell 21 Name: 5, dtype: object Name C19 Index GBC12 num 13 cell 25 Name: 6, dtype: object Name C4 Index GBC14 num 15 cell 29 Name: 7, dtype: object Name C7 Index GBC16 num 17 cell 33 Name: 8, dtype: object Name C10 Index GBC18 num 19 cell 37 Name: 9, dtype: object Name C13 Index GBC20 num 21 cell 41 Name: 10, dtype: object Name C16 Index GBC22 num 23 cell 45 Name: 11, dtype: object Process finished with exit code 0
重要:
1 #如果数据量较大,可以在list中转下 2 modify_result=[] #优化遍历速度,使用list进行 3 column_names=list(df.columns.values) 4 modify_result.append(column_names) #添加标题行 5 for i ,row in df.iterrows(): 6 newrows=list(row) 7 if i>=4: 8 newrows[column_names.index("num")]=99 9 modify_result.append(newrows) #添加每一行数据 10 df=pd.DataFrame(modify_result[1:],columns=modify_result[0]) #重新变回df 11 print(df)
结果:
C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/txt.py Name Index num cell 0 C1 GB0 1 1 1 C4 GBC2 3 5 2 C7 GBC4 5 9 3 C10 GBC6 7 13 4 C13 GBC8 99 17 5 C16 GBC10 99 21 6 C19 GBC12 99 25 7 C4 GBC14 99 29 8 C7 GBC16 99 33 9 C10 GBC18 99 37 10 C13 GBC20 99 41 11 C16 GBC22 99 45 Process finished with exit code 0
赋值修改:
1 for i in df.index: 2 if i>2: 3 df.loc[i,"cell"]=28 4 5 print(df)
C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/txt.py Name Index num cell 0 C1 GB0 1 1 1 C4 GBC2 3 5 2 C7 GBC4 5 9 3 C10 GBC6 7 28 4 C13 GBC8 9 28 5 C16 GBC10 11 28 6 C19 GBC12 13 28 7 C4 GBC14 15 28 8 C7 GBC16 17 28 9 C10 GBC18 19 28 10 C13 GBC20 21 28 11 C16 GBC22 23 28 Process finished with exit code 0
矢量运算:
1 df['num']=50 2 print(df)
C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/txt.py Name Index num cell 0 C1 GB0 50 1 1 C4 GBC2 50 5 2 C7 GBC4 50 9 3 C10 GBC6 50 13 4 C13 GBC8 50 17 5 C16 GBC10 50 21 6 C19 GBC12 50 25 7 C4 GBC14 50 29 8 C7 GBC16 50 33 9 C10 GBC18 50 37 10 C13 GBC20 50 41 11 C16 GBC22 50 45 Process finished with exit code 0
组建新的形式
1 for m ,row in df.iterrows(): 2 excel_id="{}-{}-{}".format(row['cell'],row['num'],row['Name']) 3 print(excel_id) 4 print("*" * 111) 5 for i, row in df.iterrows(): 6 print(row[['num','Name']]) 7 print("*"*111) 8 for t in df.index: 9 excel_id="{}-{}-{}".format(df.loc[t,'cell'],df.loc[t,'num'],df.loc[t,'Name']) 10 print(excel_id)
1 df['Col_sum'] = df.apply(lambda x: x.sum(), axis=1) 2 3 df.loc['Row_sum'] = df.apply(lambda x: x.sum()) 4 print(df)
结果:
C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/12.py 1-1-C1 5-3-C4 9-5-C7 13-7-C10 17-9-C13 21-11-C16 25-13-C19 29-15-C4 33-17-C7 37-19-C10 41-21-C13 45-23-C16 *************************************************************************************************************** num 1 Name C1 Name: 0, dtype: object num 3 Name C4 Name: 1, dtype: object num 5 Name C7 Name: 2, dtype: object num 7 Name C10 Name: 3, dtype: object num 9 Name C13 Name: 4, dtype: object num 11 Name C16 Name: 5, dtype: object num 13 Name C19 Name: 6, dtype: object num 15 Name C4 Name: 7, dtype: object num 17 Name C7 Name: 8, dtype: object num 19 Name C10 Name: 9, dtype: object num 21 Name C13 Name: 10, dtype: object num 23 Name C16 Name: 11, dtype: object *************************************************************************************************************** 1-1-C1 5-3-C4 9-5-C7 13-7-C10 17-9-C13 21-11-C16 25-13-C19 29-15-C4 33-17-C7 37-19-C10 41-21-C13 45-23-C16 Process finished with exit code 0
C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/12.py name index num cell Col_sum 0 1 0 1 1 3 1 4 2 3 5 14 2 7 4 5 9 25 3 10 6 7 13 36 4 13 8 9 17 47 5 16 10 5 21 52 6 10 8 9 5 32 7 13 10 13 7 43 8 16 12 17 9 54 9 19 14 3 5 41 10 4 20 5 41 70 11 16 22 7 45 90 Row_sum 129 116 84 178 507 Process finished with exit code 0
排序:
1 1 print(df) 2 2 print("*"*111) 3 3 print(df.sort_values(by="cell")) 4 4 print("*"*111) 5 5 print(df) 6 6 print("*"*111) 7 7 print(df.sort_values(by=['cell','num','name']).reset_index(drop=True)) 8 8 print("*"*111) 9 9 print(df.sort_values(by=['cell','num','name']).reset_index(drop=False))
结果:
C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/12.py name index num cell 0 1 0 1 1 1 4 2 3 5 2 7 4 5 9 3 10 6 7 13 4 13 8 9 17 5 16 10 5 21 6 10 8 9 5 7 13 10 13 7 8 16 12 17 9 9 19 14 3 5 10 4 20 5 41 11 16 22 7 45 *************************************************************************************************************** name index num cell 0 1 0 1 1 1 4 2 3 5 6 10 8 9 5 9 19 14 3 5 7 13 10 13 7 2 7 4 5 9 8 16 12 17 9 3 10 6 7 13 4 13 8 9 17 5 16 10 5 21 10 4 20 5 41 11 16 22 7 45 *************************************************************************************************************** name index num cell 0 1 0 1 1 1 4 2 3 5 2 7 4 5 9 3 10 6 7 13 4 13 8 9 17 5 16 10 5 21 6 10 8 9 5 7 13 10 13 7 8 16 12 17 9 9 19 14 3 5 10 4 20 5 41 11 16 22 7 45 *************************************************************************************************************** name index num cell 0 1 0 1 1 1 4 2 3 5 2 19 14 3 5 3 10 8 9 5 4 13 10 13 7 5 7 4 5 9 6 16 12 17 9 7 10 6 7 13 8 13 8 9 17 9 16 10 5 21 10 4 20 5 41 11 16 22 7 45 *************************************************************************************************************** level_0 name index num cell 0 0 1 0 1 1 1 1 4 2 3 5 2 9 19 14 3 5 3 6 10 8 9 5 4 7 13 10 13 7 5 2 7 4 5 9 6 8 16 12 17 9 7 3 10 6 7 13 8 4 13 8 9 17 9 5 16 10 5 21 10 10 4 20 5 41 11 11 16 22 7 45 Process finished with exit code 0
合并方法:注意表头一致
1 import numpy as np 2 import pandas as pd 3 excel1 = pd.ExcelFile('1.xlsx') 4 df1 = pd.read_excel(excel1 ,0,index_col=None,na_values=['NA']) 5 excel2 = pd.ExcelFile('2.xlsx') 6 df2 = pd.read_excel(excel2 ,0,index_col=None,na_values=['NA']) 7 print(df1) 8 print("*"*111) 9 print(df2) 10 print("*"*111) 11 print(df1[:3]) 12 print("*"*111) 13 pieces=[df1[1:4],df1[2:4],df2[2:3]] 14 print( pd.concat(pieces,sort=True)) 15 print("*"*111) 16 print( pd.concat(pieces,sort=False))
结果:
C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/12.py N IN num cell 0 1 0 1 1 1 4 2 3 5 2 7 4 5 9 3 10 6 7 13 4 13 8 9 17 5 16 10 5 21 6 10 8 9 5 7 13 10 13 7 8 16 12 17 9 9 19 14 3 5 10 4 20 5 41 11 16 22 7 45 *************************************************************************************************************** name index num cell 0 1 6 1 1 1 2 7 3 5 2 3 8 5 9 3 4 9 7 13 4 5 10 9 17 5 6 11 11 21 6 7 12 13 25 7 8 13 15 29 8 9 14 17 33 9 10 15 19 37 10 11 16 21 41 11 12 17 23 45 *************************************************************************************************************** N IN num cell 0 1 0 1 1 1 4 2 3 5 2 7 4 5 9 *************************************************************************************************************** IN N cell index name num 1 2.0 4.0 5 NaN NaN 3 2 4.0 7.0 9 NaN NaN 5 3 6.0 10.0 13 NaN NaN 7 2 4.0 7.0 9 NaN NaN 5 3 6.0 10.0 13 NaN NaN 7 2 NaN NaN 9 8.0 3.0 5 *************************************************************************************************************** N IN num cell name index 1 4.0 2.0 3 5 NaN NaN 2 7.0 4.0 5 9 NaN NaN 3 10.0 6.0 7 13 NaN NaN 2 7.0 4.0 5 9 NaN NaN 3 10.0 6.0 7 13 NaN NaN 2 NaN NaN 5 9 3.0 8.0 Process finished with exit code 0
C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/12.py name index num cell 0 1 0 1 1 1 4 2 3 5 2 7 4 5 9 3 10 6 7 13 4 13 8 9 17 5 16 10 5 21 6 10 8 9 5 7 13 10 13 7 8 16 12 17 9 9 19 14 3 5 10 4 20 5 41 11 16 22 7 45 *************************************************************************************************************** name index num cell 0 1 6 1 1 1 2 7 3 5 2 3 8 5 9 3 4 9 7 13 4 5 10 9 17 5 6 11 11 21 6 7 12 13 25 7 8 13 15 29 8 9 14 17 33 9 10 15 19 37 10 11 16 21 41 11 12 17 23 45 *************************************************************************************************************** name index num cell 0 1 0 1 1 1 4 2 3 5 2 7 4 5 9 *************************************************************************************************************** cell index name num 1 5 2 4 3 2 9 4 7 5 3 13 6 10 7 2 9 4 7 5 3 13 6 10 7 2 9 8 3 5 *************************************************************************************************************** name index num cell 1 4 2 3 5 2 7 4 5 9 3 10 6 7 13 2 7 4 5 9 3 10 6 7 13 2 3 8 5 9 Process finished with exit code 0
第一个表头不一致,第二个一致
三种合并的方法:
1 import numpy as np 2 import pandas as pd 3 excel1 = pd.ExcelFile('1.xlsx') 4 df1 = pd.read_excel(excel1 ,0,index_col=None,na_values=['NA']) 5 excel2 = pd.ExcelFile('2.xlsx') 6 df2 = pd.read_excel(excel2 ,0,index_col=None,na_values=['NA']) 7 excel3 = pd.ExcelFile('3.xlsx') 8 df3 = pd.read_excel(excel3 ,0,index_col=None,na_values=['NA']) 9 excel4 = pd.ExcelFile('4.xlsx') 10 df4 = pd.read_excel(excel4 ,0,index_col=None,na_values=['NA']) 11 print(df1) 12 print(df2) 13 print(df3) 14 print(df4)
表格结果如下:
C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/12.py name index num cell 0 1 1 5 5 1 2 1 2 4 2 3 1 3 4 3 4 2 2 2 4 5 2 1 1 name index num cell 0 6 6 7 10 1 7 7 8 7 2 8 8 9 8 3 9 9 7 9 4 10 6 9 10 name index num cell 0 11 12 13 10 1 12 13 12 13 2 13 10 13 12 3 14 12 10 10 4 15 14 12 12 name index num cell 0 16 20 16 17 1 17 17 17 17 2 18 18 18 18 3 19 19 19 20 4 20 16 17 16 Process finished with exit code 0
concat参数
1 """ 2 concat参数 3 pd.concat(objs, axis=0, join='outer', join_axes=None, 4 ignore_index=False,keys=None,levels=None, 5 names=None,verify_integrity=False, 6 copy=True) 7 1、objs : #输入,DataFrame格式或list(多个合并). 8 9 2、axis: {0, 1, ...}, default 0. #控制连接的方向,0代表列纵向,1代表行横向 10 11 3、join : {‘inner’, ‘outer’}, default ‘outer’. #控制连接的索引,inner表示取表索引之间的交集,outer表示取索引的并集 12 13 4、ignore_index: boolean, default False. #是否使用原索引,选舍弃便对新表重新进行索引排序。 14 15 5、join_axes : list of Index objects. #设定使用的索引,例以df1的索引为标准,join_axes=[df1.index] 16 17 6、keys : sequence, default None. #类似Multiindex,设立另一层索引 18 """ 19 pieces=[df1[1:4],df2[2:4],df3[2:],df4[4:]] 20 print( pd.concat(pieces,axis=0)) 21 print("*"*111) 22 print( pd.concat(pieces,axis=1)) 23 print("*"*111) 24 list=(df1,df2,df3,df4) 25 print( pd.concat(list)) 26 print("*"*111) 27 print( pd.concat(list,axis=1)) 28 print("*"*111) 29 print( pd.concat(list,axis =0, ignore_index=False)) 30 print("*"*111) 31 print( pd.concat(list,axis =0, ignore_index=True))
结果:
C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/txt.py name index num cell 1 2 1 2 4 2 3 1 3 4 3 4 2 2 2 2 8 8 9 8 3 9 9 7 9 2 13 10 13 12 3 14 12 10 10 4 15 14 12 12 4 20 16 17 16 *************************************************************************************************************** name index num cell name ... cell name index num cell 1 2.0 1.0 2.0 4.0 NaN ... NaN NaN NaN NaN NaN 2 3.0 1.0 3.0 4.0 8.0 ... 12.0 NaN NaN NaN NaN 3 4.0 2.0 2.0 2.0 9.0 ... 10.0 NaN NaN NaN NaN 4 NaN NaN NaN NaN NaN ... 12.0 20.0 16.0 17.0 16.0 [4 rows x 16 columns] *************************************************************************************************************** name index num cell 0 1 1 5 5 1 2 1 2 4 2 3 1 3 4 3 4 2 2 2 4 5 2 1 1 0 6 6 7 10 1 7 7 8 7 2 8 8 9 8 3 9 9 7 9 4 10 6 9 10 0 11 12 13 10 1 12 13 12 13 2 13 10 13 12 3 14 12 10 10 4 15 14 12 12 0 16 20 16 17 1 17 17 17 17 2 18 18 18 18 3 19 19 19 20 4 20 16 17 16 *************************************************************************************************************** name index num cell name index ... num cell name index num cell 0 1 1 5 5 6 6 ... 13 10 16 20 16 17 1 2 1 2 4 7 7 ... 12 13 17 17 17 17 2 3 1 3 4 8 8 ... 13 12 18 18 18 18 3 4 2 2 2 9 9 ... 10 10 19 19 19 20 4 5 2 1 1 10 6 ... 12 12 20 16 17 16 [5 rows x 16 columns] *************************************************************************************************************** name index num cell 0 1 1 5 5 1 2 1 2 4 2 3 1 3 4 3 4 2 2 2 4 5 2 1 1 0 6 6 7 10 1 7 7 8 7 2 8 8 9 8 3 9 9 7 9 4 10 6 9 10 0 11 12 13 10 1 12 13 12 13 2 13 10 13 12 3 14 12 10 10 4 15 14 12 12 0 16 20 16 17 1 17 17 17 17 2 18 18 18 18 3 19 19 19 20 4 20 16 17 16 *************************************************************************************************************** name index num cell 0 1 1 5 5 1 2 1 2 4 2 3 1 3 4 3 4 2 2 2 4 5 2 1 1 5 6 6 7 10 6 7 7 8 7 7 8 8 9 8 8 9 9 7 9 9 10 6 9 10 10 11 12 13 10 11 12 13 12 13 12 13 10 13 12 13 14 12 10 10 14 15 14 12 12 15 16 20 16 17 16 17 17 17 17 17 18 18 18 18 18 19 19 19 20 19 20 16 17 16 Process finished with exit code 0
merge的参数(暂时没有用到,用到时补充) merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x', '_y'), copy=True, indicator=False) 1、on:列名,join用来对齐的那一列的名字,用到这个参数的时候一定要保证左表和右表用来对齐的那一列都有相同的列名。 2、left_on:左表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。 3、right_on:右表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。 4、left_index/ right_index: 如果是True的haunted以index作为对齐的key 5、how:数据融合的方法。 6、 sort:根据dataframe合并的keys按字典顺序排序,默认是,如果置false可以提高表现。
Append用法:
df1.append([df2,df3,df4])= pd.concat([df1,df2,df3,df4])
判断是否重复:
df1 = pd.read_excel(excel1 ,0,index_col=None,na_values=['NA']) print(df1) print("*"*111) print(df1.duplicated())
结果:
C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/txt.py name index num cell 0 1 1 5 5 1 2 1 2 4 2 3 3 3 3 3 4 2 2 2 4 4 2 2 2 *************************************************************************************************************** 0 False 1 False 2 False 3 False 4 True dtype: bool Process finished with exit code 0
剔除重复:
1 print(df1) 2 print("*"*111) 3 print(df1.drop_duplicates("index"))
结果:
C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/txt.py name index num cell 0 1 1 5 5 1 2 1 2 4 2 3 3 3 3 3 4 2 2 2 4 4 2 2 2 *************************************************************************************************************** name index num cell 0 1 1 5 5 2 3 3 3 3 3 4 2 2 2 Process finished with exit code 0
分类汇总:
1 import numpy as np 2 import pandas as pd 3 excel1 = pd.ExcelFile('1.xlsx') 4 df1 = pd.read_excel(excel1 ,0,index_col=None,na_values=['NA']) 5 print("原始数据:",df1) 6 print("*"*111) 7 print(df1.groupby(['num'])) 8 print("*"*111) 9 print(df1.groupby(['num']).groups) 10 print("*"*111) 11 for name ,group in df1.groupby(['num']): 12 print("group:",name) 13 print(group) 14 print("*"*111) 15 print(df1.groupby(['num']).sum()) 16 print("*"*111) 17 grouped=df1.groupby(['num']) 18 print(grouped.size()) 19 print("*"*111) 20 print(len(grouped)) 21 print("*"*111) 22 print(grouped.first()) 23 print("*"*111) 24 print(grouped.last()) 25 print("*"*111) 26 print(grouped.get_group(3)) 27 print("*"*111) 28 grouped2=df1.groupby(['num','cell']) 29 print(grouped2.groups) 30 print("*"*111) 31 print(grouped2.get_group((2,4))) 32 print("*"*111) 33 for (k1,k2),group_t in grouped2: 34 print("group:",k1,k2) 35 print(group_t)
结果:
C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/txt.py 原始数据: name index num cell 0 1 1 5 5 1 2 1 2 4 2 3 3 3 3 3 4 2 2 2 4 4 2 2 2 *************************************************************************************************************** <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x07746D90> *************************************************************************************************************** {2: Int64Index([1, 3, 4], dtype='int64'), 3: Int64Index([2], dtype='int64'), 5: Int64Index([0], dtype='int64')} *************************************************************************************************************** group: 2 name index num cell 1 2 1 2 4 3 4 2 2 2 4 4 2 2 2 group: 3 name index num cell 2 3 3 3 3 group: 5 name index num cell 0 1 1 5 5 *************************************************************************************************************** name index cell num 2 10 5 8 3 3 3 3 5 1 1 5 *************************************************************************************************************** num 2 3 3 1 5 1 dtype: int64 *************************************************************************************************************** 3 *************************************************************************************************************** name index cell num 2 2 1 4 3 3 3 3 5 1 1 5 *************************************************************************************************************** name index cell num 2 4 2 2 3 3 3 3 5 1 1 5 *************************************************************************************************************** cell index name 2 3 3 3 *************************************************************************************************************** {(2, 2): Int64Index([3, 4], dtype='int64'), (2, 4): Int64Index([1], dtype='int64'), (3, 3): Int64Index([2], dtype='int64'), (5, 5): Int64Index([0], dtype='int64')} *************************************************************************************************************** name index num cell 1 2 1 2 4 *************************************************************************************************************** group: 2 2 name index num cell 3 4 2 2 2 4 4 2 2 2 group: 2 4 name index num cell 1 2 1 2 4 group: 3 3 name index num cell 2 3 3 3 3 group: 5 5 name index num cell 0 1 1 5 5 Process finished with exit code 0
数据透视表
1 import numpy as np 2 import pandas as pd 3 excel1 = pd.ExcelFile('1.xlsx') 4 df1 = pd.read_excel(excel1 ,0,index_col=None,na_values=['NA']) 5 print(df1) 6 print("*"*111) 7 pvt=pd.pivot_table(df1,index=["name"],values=['num','cell'],aggfunc=np.sum) 8 print(pvt) 9 print("*"*111) 10 print(pvt.loc[('A'),'num']) 11 print("*"*111) 12 print(pvt.reset_index()) 13 print("*"*111) 14 print(df1) 15 print("*"*111) 16 pvt2=pd.pivot_table(df1,index=["name"],values=['num'],columns=['dex'],aggfunc=np.sum) 17 print(pvt2) 18 print("*"*111) 19 df2=pvt2.reset_index() 20 print(df2) 21 print("*"*111) 22 print(df2.columns.values) 23 print("*"*111) 24 print(df2.shape[1])
结果:
C:\Users\zte\AppData\Local\Programs\Python\Python37-32\python.exe C:/Users/zte/PycharmProjects/radioparametercheck/csvfiles/txt.py name dex num cell 0 A 1 5 5 1 A 2 2 4 2 B 3 3 3 3 B 4 2 2 4 E 5 2 2 *************************************************************************************************************** cell num name A 9 7 B 5 5 E 2 2 *************************************************************************************************************** 7 *************************************************************************************************************** name cell num 0 A 9 7 1 B 5 5 2 E 2 2 *************************************************************************************************************** name dex num cell 0 A 1 5 5 1 A 2 2 4 2 B 3 3 3 3 B 4 2 2 4 E 5 2 2 *************************************************************************************************************** num dex 1 2 3 4 5 name A 5.0 2.0 NaN NaN NaN B NaN NaN 3.0 2.0 NaN E NaN NaN NaN NaN 2.0 *************************************************************************************************************** name num dex 1 2 3 4 5 0 A 5.0 2.0 NaN NaN NaN 1 B NaN NaN 3.0 2.0 NaN 2 E NaN NaN NaN NaN 2.0 *************************************************************************************************************** [('name', '') ('num', 1) ('num', 2) ('num', 3) ('num', 4) ('num', 5)] *************************************************************************************************************** 6 Process finished with exit code 0
