

C语言 Ubuntu系统 UTF-8 文字处理
关于UTF-8的规则:https://baike.baidu.com/item/UTF-8/481798?fr=aladdin
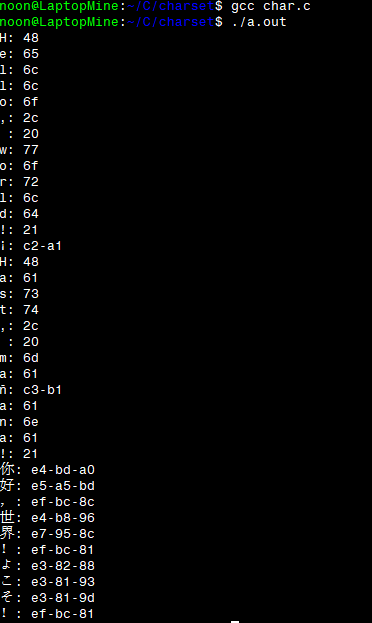
使用windows系统下的Ubuntu子系统 ,实现C语言对UTF-8编码格式的文字处理。
,实现C语言对UTF-8编码格式的文字处理。
#include <stdio.h> // 根据UTF-8的编码格式,打印处文字以及它们相应的编码 // 形参:获取一个无符号字符指针 void PrintUTF8Encoding(unsigned char *str) { unsigned char *chr = str; // 根据UTF-8的规则,一个文字占几个字节可以从首个编码的二进制高位数看出来 // 0代表1个字节,11代表两个字节,以此类推,最多有六个字节 unsigned char bytesArr[] = {0b0, 0b11, 0b111, 0b1111, 0b11111, 0b111111}; int i, j; // bytes存储当前字符的字节数 int bytes; unsigned char *tmp; // C中字符字面量都由'\0'结尾 while (*chr != '\0') { // 依次循环,确认当前字符有多少个字节 for (i = 6; i > 0; i--) { j = 8 - i; if ((*chr>>j) == bytesArr[i-1]) { bytes = i; break; } } // 循环打印出当前字符的字节 // 注意:多字节必须放在一起打印才能显示出正确的文字 tmp = chr; for (i = 0; i < bytes; i++) { putchar(*tmp); ++tmp; } // 打印出字节的十六进制编码 printf(": "); tmp = chr; for (i = 0; i < bytes; i++) { printf("%x-", *tmp); ++tmp; } printf("\b \n"); // 根据当前字符的字节数,跳过相应个字节 chr += bytes; } } int main() { PrintUTF8Encoding("Hello, world!¡Hast, mañana!你好,世界!よこそ!"); return 0; }
Resistance is Futile!
