LLL(Life Long Learning)&灾难性遗忘(Catastrophic Forgetting)
LLL(Life Long Learning)&灾难性遗忘(Catastrophic Forgetting)
Life Long Learning
通常机器学习中,单个模型只解决单个或少数几个任务。对于新的任务,我们一般重新训练新的模型。而LifeLong learning,则先在task1上使用一个模型,然后在task2上仍然使用这个模型,一直到task n。Lifelong learning探讨的问题是,一个模型能否在很多个task上表现都很好。如此下去,模型能力就会越来越强。这和人类不停学习新的知识,从而掌握很多不同知识,是异曲同工的。
但是在一个顺序无标注的、可能随机切换的、同种任务可能长时间不复现的任务序列中,AI对当前任务B进行学习时,对先前任务A的知识会突然地丢失的现象。通常发生在对任务A很重要的神经网络的权重正好满足任务B的目标时。
如下图的例子中在没有学习task5时acc为0,学习后可以到达百分之百,但是在学习过后续任务后正确率就会回到较低的水平,而即使一次性地(simultaneously)给到20个人俗的时候,对20个任务的学习程度也不尽相同,要解决灾难性遗忘的问题
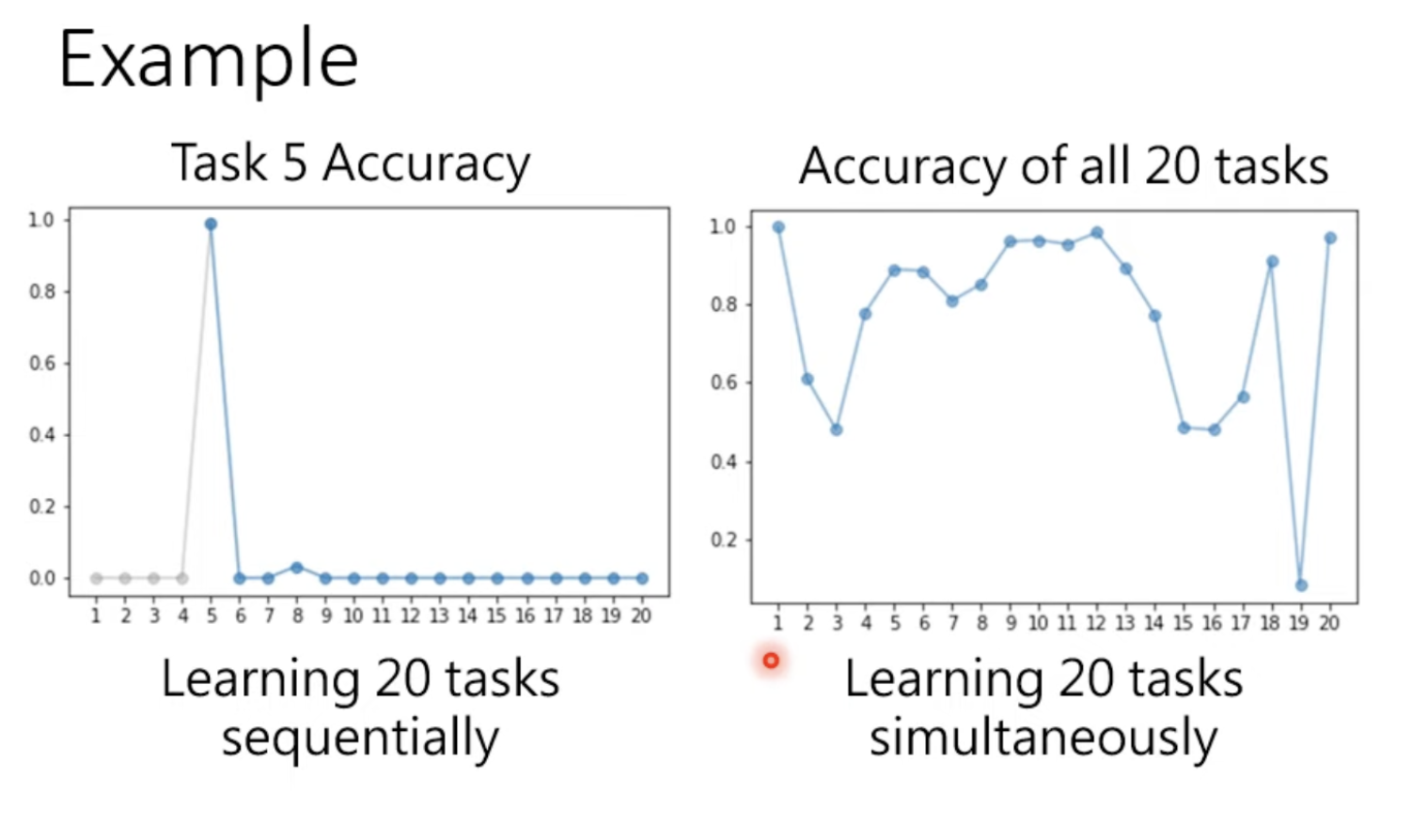
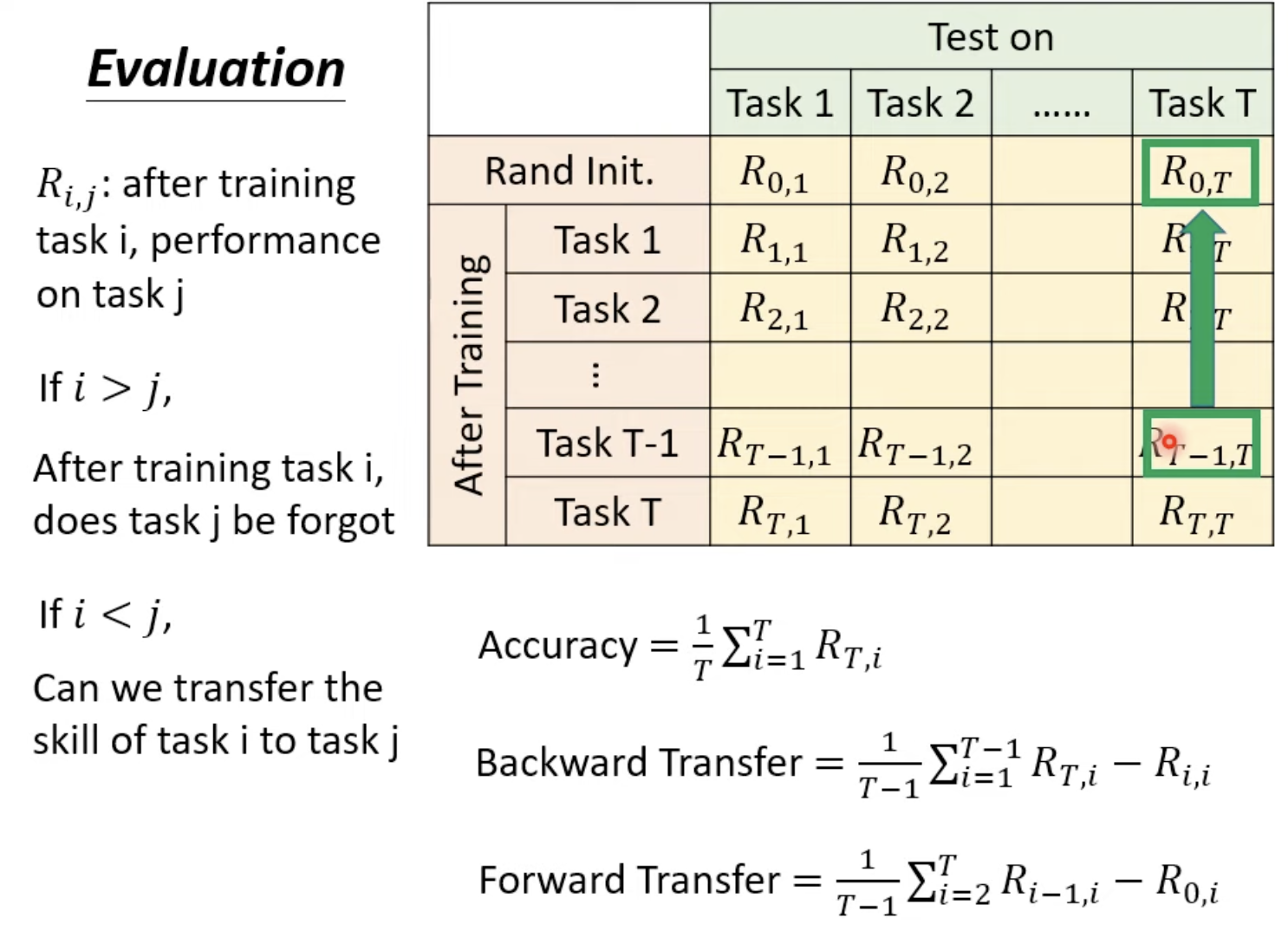
而从task1到taskT的正确率中可以得到这些信息
-
模型准确率
即学习完Task T后在前面所有task上的准确率表现
-
模型的记忆能力
即Backward Transfer,对于同一个Task i 学习完T后正确率和刚刚学习完i时的差值,由于有遗忘的出现,一般值都为负数(如果为正则证明遗忘程度少甚至有一定迁移能力?)
-
模型的迁移能力
即Forward Transfer,还没有学到Task T时对于T的理解程度
Catastrophic Forgetting
LwF
Many practical vision applications require learning new visual capabilities while maintaining perfor- mance on existing ones. For example, a robot may be delivered to someone’s house with a set of default object recognition capabilities, but new site-specific object models need to be added. Or for construction safety, a system can identify whether a worker is wearing a safety vest or hard hat, but a superintendent may wish to add the ability to detect improper footware. Ideally, the new tasks could be learned while sharing parameters from old ones, without suffering from Catastrophic Forgetting, (degrading performance on old tasks) or having access to the old training data. Legacy data may be unrecorded, proprietary, or simply too cumbersome to use in training a new task. This problem is similar in spirit to transfer, multitask, and lifelong learning.
EWC
https://www.pnas.org/doi/pdf/10.1073/pnas.1611835114
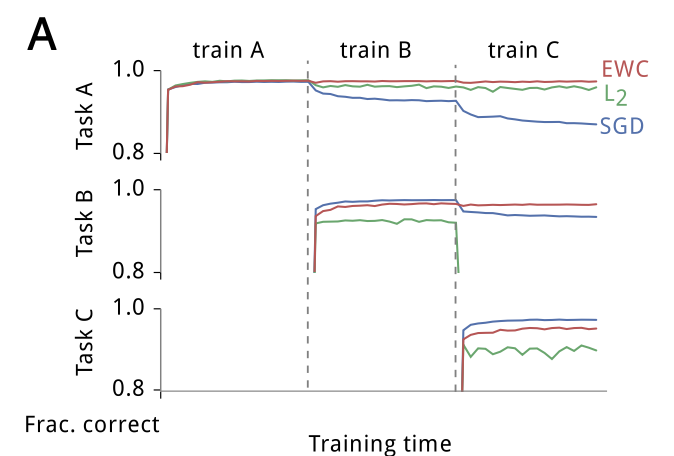
任务A在刚学习时候的时候正确率很高,而在SGD曲线中出现了catastrophic forgetting,而在l2曲线中,刚刚学习B和C时正确率都不高,新的任务学习程度不高即为Intransigence
EWC. In brains, synaptic consolidation might enable continual learning by reducing the plasticity of synapses that are vital to previously learned tasks. We implement an algorithm that per- forms a similar operation in artificial neural networks by con- straining important parameters to stay close to their old values. In this section, we explain why we expect to find a solution to a new task in the neighborhood of an older one, how we implement the constraint, and finally how we determine which parameters are important.
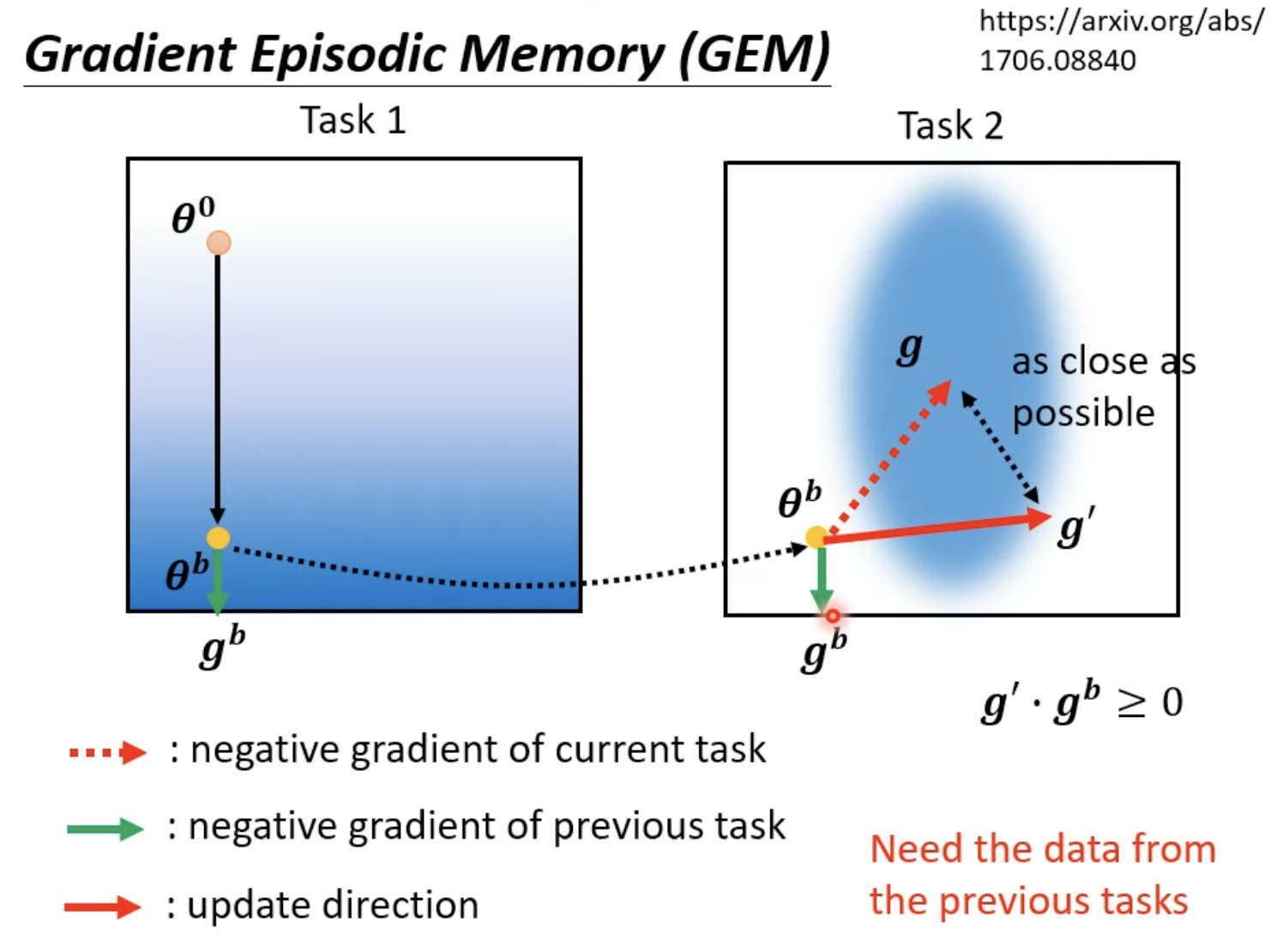
GEM
其他方法
Progressive NN
如果对于新的task要创建新的NN的话,task不断增多最后储存会被耗尽,但是对于小型的任务还是可行的
PackNet/CPG
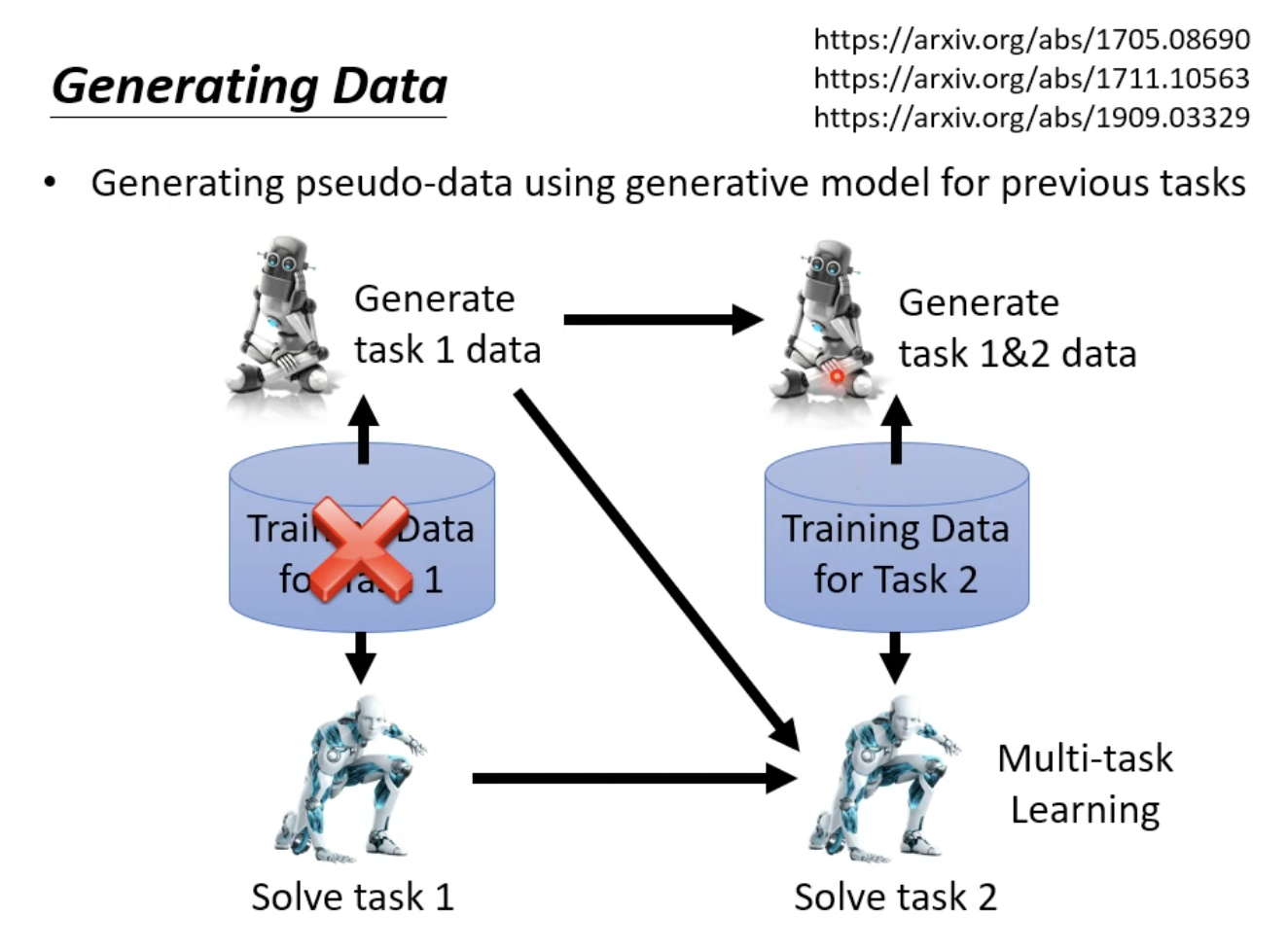
Memory Replay
其他链接
https://zhuanlan.zhihu.com/p/29196822

 浙公网安备 33010602011771号
浙公网安备 33010602011771号