20221114
0
改进的点
- 增加input,为input增加循环
- load_data增加归一化,与之对应输出时需要将归一化还原
存疑的点
-
分类阈值是否和常识一样为0.5/如果改成不是奇偶数判断(例如是否被3整除)阈值是否是0.5
-
BATCH_SIZE:即一次训练所抓取的数据样本数量,更改之后有什么影响,built_model里面的参数的依据
-
现行代码accuracy很低,且predicted值在x值较大时全部为1,是代码 / model问题(多次model.predict除了y之外都相同)
-
神经网络的建立(完全无了解)
原代码
built_model
def built_model():
model = Sequential()
model.add(Dense(units=256,
input_dim=2,
activation='relu'))
# input_length就是输入数据的长度,Input_dim就是数据的维度
# https://www.jianshu.com/p/807936809af4
# https://blog.csdn.net/weixin_46322028/article/details/110873992 dense参数参考
# activation=None, #激活函数.但是默认 liner
# https://long97.blog.csdn.net/article/details/107749268 激活函数的类型
model.add(Dropout(0.5))
# https://blog.csdn.net/yangwohenmai1/article/details/123346240 关于dropout
model.add(Dense(units=128,
activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=1,
activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
# https://blog.csdn.net/weixin_48207979/article/details/110855623 关于summary()
return model
# https://blog.csdn.net/weixin_42499236/article/details/84624195
train_model
def train_model(batch_size=32, verbose=0, validation_split=0.2, model=None):
# BATCH_SIZE:即一次训练所抓取的数据样本数量;
# BATCH_SIZE的大小影响训练速度和模型优化。同时按照以上代码可知,其大小同样影响每一epoch训练模型次数。
# verbose是日志显示,有三个参数可选择,分别为0,1和2。
# 当verbose=0时,简单说就是不输出日志信息 ,进度条、loss、acc这些都不输出。
# 当verbose=1时,带进度条的输出日志信息
# 当verbose=2时,为每个epoch输出一行记录,和1的区别就是没有进度条
# validation_split 的意思是将 data_dir 目录的所有图片的 百分之多少划分为验证集 。 这里设置为 0.2 表示,20% 为验证集,80% 为训练集
data, labels = load_data()
train_x, train_y = data[: int(len(data) * 0.7), 0: 2], labels[: int(len(labels) * 0.7)]
# print(train_x,train_y)
test_x, test_y = data[int(len(data) * 0.7): len(data), 0: 2], labels[int(len(labels) * 0.7): len(labels)]
# print('=============')
# print(test_x,test_y)
if model is None:
model = built_model()
history = model.fit(train_x, train_y,
batch_size=batch_size,
epochs=10, # epoch:整数,训练终止时的epoch值,训练将在达到该epoch值时停止,当没有设置initial_epoch时,它就是训练的总轮数,否则训练的总轮数为epochs - inital_epoch
verbose=verbose,
validation_split=validation_split)# 用来指定训练集的一定比例数据作为验证集
# print ("刻画损失函数的变化趋势")
# plt.figure('f1')
# plt.plot(history.history['loss'], label='train')
# plt.plot(history.history['val_loss'], label='valid')
# plt.legend()
# plt.show()
print ("模型构建成功,开始预测数据")
score = model.evaluate(test_x, test_y,
batch_size=batch_size)
batch_size参数调整试验
尝试16和64发现最终accuracy并不是设置batch=32时最高,而在使用SGD的情况下,GPU对2的整数次幂的batchsize表现更好,所以更换batch_size为其他2的整数幂进行尝试
batch_size=16,epoch=20,summary:376/376 [==============================] - 2s 5ms/step - loss: 0.1809 - accuracy: 0.9008
batch_size=32,epoch=20,summary:188/188 [==============================] - 1s 4ms/step - loss: 0.2348 - accuracy: 0.8970
batch_size=64,94/94 [==============================] - 0s 4ms/step - loss: 0.2730 - accuracy: 0.9022
batch_size=128,47/47 [==============================] - 0s 4ms/step - loss: 0.3888 - accuracy: 0.7012
batch_size=8,751/751 [==============================] - 3s 4ms/step - loss: 0.0366 - accuracy: 1.0000
可以看到在2的整数幂情况下,幂越大模型运算速度越快,而只是因为好奇尝试跑的batch_size=8跑出了这串代码第一次1.0的accuracy
以下是使用batch_size=8模型所做的尝试
234
2022-11-15 18:29:02.997431: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:114] Plugin optimizer for device_type GPU is enabled.
234 4 0.99903727
偶数
235
235 5 0.07666259
奇数
2356
2356 6 0.9681723
偶数
53467
53467 7 0.024803855
奇数
1231245
1231245 5 1.0896908e-07
奇数
12312344
12312344 4 5.098695e-25
奇数
1231244
1231244 4 0.00010418004
奇数
123124
123124 4 0.99661297
偶数
依旧无法幸免大数的predict最终向0靠近
可以感知到,小batchsize导致代码运行过慢,过大batchsize会导致accuracy降低而可能收敛到一些不好的局部最优点
增加的output部分
while(1):
x = int(input())
if x == 0:
print('finish')
break
else:
y = np.array([x, x % 10])
test_x[0] = y
# 单独输出model.predict(y,batch_size=batch_size,verbose=0)会报错 unsolved
predicted = model.predict(test_x,
batch_size=batch_size,
verbose=0)
print(test_x[0], predicted[0][0])
if (predicted[0][0] > 0.5):
print("偶数")
else:
print("奇数")
增加的归一化 和 归一化还原部分
# load_data
seclar = pp.MinMaxScaler(feature_range=(0, 1))
data = seclar.fit_transform(data)
np.random.shuffle(data)
data = np.array(data)
# model
y = np.array([(x-1)/20000, (x % 10)/(10-1)])
现状:
- 1-100000(10num)accuracy尚可,100000后mod0-4基本正确其余错误,再变大数字会逐渐变成1/0(在前面改变batch_size时进一步尝试,界限并不严格是10num
- epoch为偶数时 最后大数predict为1,但是epoch为奇数时大数predict结果为0
- 更换模10(特征)到模3/模5 accuracy很低
- 更换模2到模3 accuracy很低,个人认为是阈值(threshold)划分问题
神经网络
另一个例子
Requires
from numpy import array,exp,random,dot
创建数据
然后创建一个矩阵X,将小A、小B、小C三个人前五次的数据放到矩阵中去;创建一个装置矩阵y,将小D前五次的数据放到矩阵中去。注意矩阵X是3x5的,所以这里需要将1x5的矩阵y转置一下成5x1的矩阵,才能进行矩阵运算。
X = array([[0,1,0],[1,1,0],[1,0,1],[0,0,1],[0,1,1]])
y = array([[1,1,0,0,1]]).T
初始假设
下面利用随机数做一个假设,假设小D去不去爬山与小A、小B、小C三人去不去爬山的相关关系的数值(权重)为weights。
random.seed(1)
weights = 2 * random.random((3,1))-1
神经元计算
接下来进入循环,使用假设的weights算出output(output数值越接近“0”,代表小D去不去爬山的可能性越大,output数值越接近“1”,代表小D去爬山的可能性越大),前五次小D的数据y - 利用假设关系得到的output数值=得到误差 error,通过循环不断调整假设关系weights,减小误差,最终得到误差最小的一组关系系数weights。
for it in range(100000):
output = 1/(1+exp(-dot(X,weights)))
error = y - output
delta = error * output *(1-output)
weights += dot(X.T,delta)
使用纯numpy进行奇偶数预测(依旧增加模数特征) (todo)
伪代码大致为
X = data
y = label
# get the weight
for it in range(100000):
output = 1/(1+exp(-dot(X,weights)))
error = y - output
delta = error * output *(1-output)
weights += dot(X.T,delta)
num = input()
print("误差为:\n",error)
print("相关系数为:\n",weights)
climbing_probability = 1/(1+exp(-dot([[num,num%10]],weights)))
print("小D会去爬山的概率为(数字为奇数/偶数的概率是):\n",climbing_probability)
原神经网络解读(todo, Chap 5)
关于阈值(threshold)Chap 2.3.3
https://blog.csdn.net/weixin_39781323/article/details/110262035
- TP: True Positives, 表示实际为正例且被分类器判定为正例的样本数
- FP: False Positives, 表示实际为负例且被分类器判定为正例的样本数
- FN: False Negatives, 表示实际为正例但被分类器判定为负例的样本数
- TN: True Negatives, 表示实际为负例且被分类器判定为负例的样本数
ROC曲线
在分类任务中,测试部分通常是获得一个概率表示当前样本属于正例的概率, 我们往往会采取一个阈值,大于该阈值的为正例, 小于该阈值的为负例。 如果我们减小这个阈值, 那么会有更多的样本被识别为正类,这会提高正类的识别率,但同时会降低负类的识别率。
为了形象的描述上述的这种变化, 引入ROC曲线来评价一个分类器的好坏。 ROC 曲线主要关注两个指标:
其中, FPR 代表将负例错分为正例的概率, TPR 表示能将正例分对的概率, 如果我们增大阈值, 则 TPR 会增加,而对应的FPR也会增大, 而绘制ROC曲线能够帮助我们找到二者的均衡点。
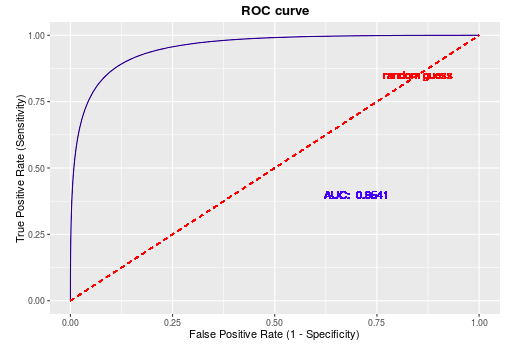
AUC:Area under Curve
AUC 为ROC 曲线下的面积, 这个面积的数值介于0到1之间, 能够直观的评价出分类器的好坏, AUC的值越大, 分类器效果越好。
- AUC = 1: 完美分类器, 采用该模型,不管设定什么阈值都能得出完美预测(绝大多数时候不存在)
- 0.5 < AUC < 1: 优于随机猜测,分类器好好设定阈值的话,有预测价值
- AUC = 0.5: 跟随机猜测一样,模型没有预测价值
- AUC < 0.5 :比随机猜测还差,但是如果反着预测,就优于随机猜测。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号