20221027&20221028 神经网络入门:神经网络判断奇偶数
神经网络
神经网络反映人类大脑的行为,允许计算机程序识别模式,以及解决人工智能、机器学习和深度学习领域的常见问题。
神经网络,也称为人工神经网络 (ANN) 或模拟神经网络 (SNN),是机器学习的子集,并且是深度学习算法的核心。其名称和结构是受人类大脑的启发,模仿了生物神经元信号相互传递的方式。
人工神经网络 (ANN) 由节点层组成,包含一个输入层、一个或多个隐藏层和一个输出层。 每个节点也称为一个人工神经元,它们连接到另一个节点,具有相关的权重和阈值。 如果任何单个节点的输出高于指定的阈值,那么该节点将被激活,并将数据发送到网络的下一层。 否则,不会将数据传递到网络的下一层。
运作方式
将各个节点想象成其自身的线性回归模型,由输入数据、权重、偏差(或阈值)和输出组成。公式大概是这样的:
∑wixi + bias = w1x1 + w2x2 + w3x3 + bias
output = f(x) = 1 if ∑wixi + b> = 0; 0 if ∑w1x1 + b < 0
具体一点可以认为是一个事件由多个因素影响(W),不同因素的影响有相应的权重(X),有正面影响有负面影响,对于事件的影响到了一定值才会导致决策(bias)
但是在上面的例子中,我们利用感知器来说明这里发挥作用的一些数学运算,而神经网络利用 sigmoid 神经元,它们的值介于 0 到 1 之间。 由于神经网络的行为类似于决策树,它将数据从一个节点级联到另一个节点,x 值介于 0 到 1 之间将减少单个变量的任何给定变化对任何给定节点的输出乃至神经网络的输出的影响。
随着我们开始思考更实际的神经网络用例,例如图像识别或分类,我们将利用监督式学习或标签化数据集来训练算法。 当我们训练模型时,我们将使用成本(或损失)函数来评估其准确性。 这通常也称为均方误差 (MSE)。 在下面的等式中,
- i 表示样本的索引,
- y-hat 是预测的结果,
- y 是实际值,而
- m 是样本的数量。

最终的目标是,使我们的成本函数最小化,以确保对任何给定观测的拟合的正确性。 当模型调整其权重和偏差时,它使用成本函数和强化学习来达到收敛点或局部最小值。 算法通过梯度下降调整权重,这使模型可以确定减少错误(或使成本函数最小化)的方向。 通过每个训练示例,模型的参数不断调整,逐渐收敛到最小值。(简单来说是喂养计算机大量数据,让计算机尝试因素的不同权重,得到的结果与真实结果进行比较并逐渐纠正权重,最终训练出一个模型)
常见神经网络类型
前馈神经网络或多层感知器 (MLP)
输入层、一个或多个隐藏层以及输出层组成。 虽然这些神经网络通常也被称为 MLP,但值得注意的是,它们实际上由 sigmoid 神经元而不是感知器组成,因为大多数现实问题是非线性的。 数据通常会馈送到这些模块中以进行训练,它们是计算机视觉、自然语言处理和其他神经网络的基础。
卷积神经网络 (CNN)
类似于前馈网络,但通常用于图像识别、模式识别和/或计算机视觉。 这些网络利用线性代数的原理(特别是矩阵乘法)来识别图像中的模式。
循环神经网络 (RNN)
由其反馈环路来识别。这些学习算法主要用在使用时间序列数据来预测未来结果(如股票市场预测或销售预测)的情况中。
神经网络与深度学习
深度学习和神经网络在对话中往往可以互换使用,这可能会让人感到困惑。 因此,值得注意的是,深度学习中的“深度”只是指神经网络中层的深度。 由三个以上的层组成的神经网络(包含输入和输出)即可视为深度学习算法。 只有两层或三层的神经网络只是基本神经网络。
AI vs. 机器学习 vs. 深度学习 vs. 神经网络
至此对于几个定义的理解为
- 在前面一篇笔记中提及到AI包括ML&DL,但是可以理解成ML和DL都属于AI的子集,但是两者不在一个维度
- 深度学习是神经网络的一种应用,深度指的是神经网络的深层数
- 深度学习是机器学习的一个子集。在这一点上,你更有可能在应用程序中使用机器学习,而不是深度学习,但它仍然是一个发展中的技术,而且部署起来很昂贵。
使用神经网络制作一个能判断奇偶数的训练器
数据集生成
import numpy as np
import sklearn.preprocessing as pp
def load_data(number=10001):
temp = [i for i in range(1, number * 2)]
data, labels = [], []
for i in temp:
if i % 2 == 0:
data.append([i, i % 10, 1])
else:
data.append([i, i % 10, 0]) #在1-number之间随机生成数字
seclar = pp.MinMaxScaler(feature_range=(0, 1))#设置归一化,将一列数字都归入0-1范围
# new_num = (old_num - min_value) / (max_value - min_value)
data = seclar.fit_transform(data)
np.random.shuffle(data)
print data
labels = data[:, -1]
return data, labels
if __name__ == '__main__':
load_data()
环境配置
在运行模型代码时使用了tensorflow,keras,但是tensorflow官网的描述python版本为3.6–3.9,本机使用环境为3.10,使用pip安装时报错
ERROR: No matching distribution found for tensorflow
回头安装python3.8
发现改使用python3.8依旧产生相同报错
再次搜索,发现可能是本机m1芯片的原因
可惜文章没有看完直接开始配置miniconda+python3.8
途中遇到的问题包括但不限于
(base) weiwei@weiweideMacBook-Air ~ % conda create -n tf26 python==3.8
~
Solving environment: failed
PackagesNotFoundError: The following packages are not available from current channels:
- python==3.8
To search for alternate channels that may provide the conda package you're
looking for, navigate to
https://anaconda.org
and use the search bar at the top of the page.
(base) weiwei@weiweideMacBook-Air ~ % conda activate tf26
EnvironmentNameNotFound: Could not find conda environment: tf26
You can list all discoverable environments with `conda info --envs`.
按照提示去anaconda寻找包但是不存在
(base) weiwei@weiweideMacBook-Air ~ % conda config --append channels conda-forge
Warning: 'conda-forge' already in 'channels' list, moving to the bottom
将miniconda删除并下载miniforge
使用下列指令进行安装
chmod +x ~/Downloads/Miniforge3-MacOSX-arm64.sh
sh ~/Downloads/Miniforge3-MacOSX-arm64.sh
询问y/n均为yes
source ~/miniforge3/bin/activate
发现创建conda环境依旧报错,在pycharm配置解释器时看到miniforge中有python3.10。尽管官网描述不支持python3.10,但是由于对前面的问题一筹莫展只能尝试直接使用3.10
(base) weiwei@weiweideMacBook-Air ~ % conda create -n tf26 python==3.10
Collecting package metadata (current_repodata.json): done
Solving environment: failed with repodata from current_repodata.json, will retry with next repodata source.
Collecting package metadata (repodata.json): done
Solving environment: done
创建环境成功
后使用conda指令对依赖包进行安装
conda install -c apple tensorflow-deps
python -m pip install tensorflow-macos
python -m pip install tensorflow-metal
对其他依赖包进行安装
(sklearn需安装sci-kitlearn)
模型建立
首先是对Keras的初步了解
快速开始:30s上手Keras
Keras的核心数据结构是“模型”,模型是一种组织网络层的方式。Keras中主要的模型是Sequential模型,Sequential是一系列网络层按顺序构成的栈。你也可以查看函数式模型来学习建立更复杂的模型
Sequential模型如下
from keras.models import Sequential
model = Sequential()
将一些网络层通过.add()堆叠起来,就构成了一个模型:
from keras.layers import Dense, Activation
model.add(Dense(units=64, input_dim=100))
model.add(Activation("relu"))
model.add(Dense(units=10))
model.add(Activation("softmax"))
完成模型的搭建后,我们需要使用.compile()方法来编译模型:
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
编译模型时必须指明损失函数和优化器,如果你需要的话,也可以自己定制损失函数。Keras的一个核心理念就是简明易用,同时保证用户对Keras的绝对控制力度,用户可以根据自己的需要定制自己的模型、网络层,甚至修改源代码。
from keras.optimizers import SGD
model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=0.01, momentum=0.9, nesterov=True))
完成模型编译后,我们在训练数据上按batch进行一定次数的迭代来训练网络
model.fit(x_train, y_train, epochs=5, batch_size=32)
当然,我们也可以手动将一个个batch的数据送入网络中训练,这时候需要使用:
model.train_on_batch(x_batch, y_batch)
随后,我们可以使用一行代码对我们的模型进行评估,看看模型的指标是否满足我们的要求:
loss_and_metrics = model.evaluate(x_test, y_test, batch_size=128)
或者,我们可以使用我们的模型,对新的数据进行预测:
classes = model.predict(x_test, batch_size=128)
https://keras-cn.readthedocs.io/en/latest/getting_started/sequential_model/#shape
import numpy as np
import sklearn.preprocessing as pp
def load_data(number=10001):
temp = [i for i in range(1, number * 2)]
data, labels = [], []
for i in temp:
if i % 2 == 0:
data.append([i, i % 10, 1])
else:
data.append([i, i % 10, 0])
# print(data)
seclar = pp.MinMaxScaler(feature_range=(0, 1))
data = seclar.fit_transform(data)
np.random.shuffle(data)
labels = data[:, -1]
# print(data)
# print(labels)
# data归一化前分别为 数字,尾数,奇偶性
# label为从data中提取出来的奇偶性
# 对data进行归一化
return data, labels
if __name__ == '__main__':
load_data()
模型通过利用数个全连接层(Dense,用于特征学习,层层推导特征向量,然后将特征映射到标签)和(全连接层数-1)层的Dropout层(去除模型过拟合)
理解代码需要对numpy,matplotlib进行初步了解
https://www.runoob.com/numpy/numpy-advanced-indexing.html
https://blog.csdn.net/weixin_43629813/article/details/101122997
最终代码为
from keras.layers import Dense, Dropout
from keras.models import Sequential
import matplotlib.pyplot as plt
import numpy as np
import sklearn.preprocessing as pp
from load_data import load_data
def built_model():
model = Sequential()
model.add(Dense(units=256,
input_dim=2,
activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=128,
activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=1,
activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
return model
def train_model(batch_size=32, verbose=2, validation_split=0.2, model=None):
data, labels = load_data()
train_x, train_y = data[: int(len(data) * 0.7), 0: 2], labels[: int(len(labels) * 0.7)]
print(train_x,train_y)
test_x, test_y = data[int(len(data) * 0.7): len(data), 0: 2], labels[int(len(labels) * 0.7): len(labels)]
print(test_x,test_y)
if model is None:
model = built_model()
history = model.fit(train_x, train_y,
batch_size=batch_size,
epochs=10,
verbose=verbose,
validation_split=validation_split)
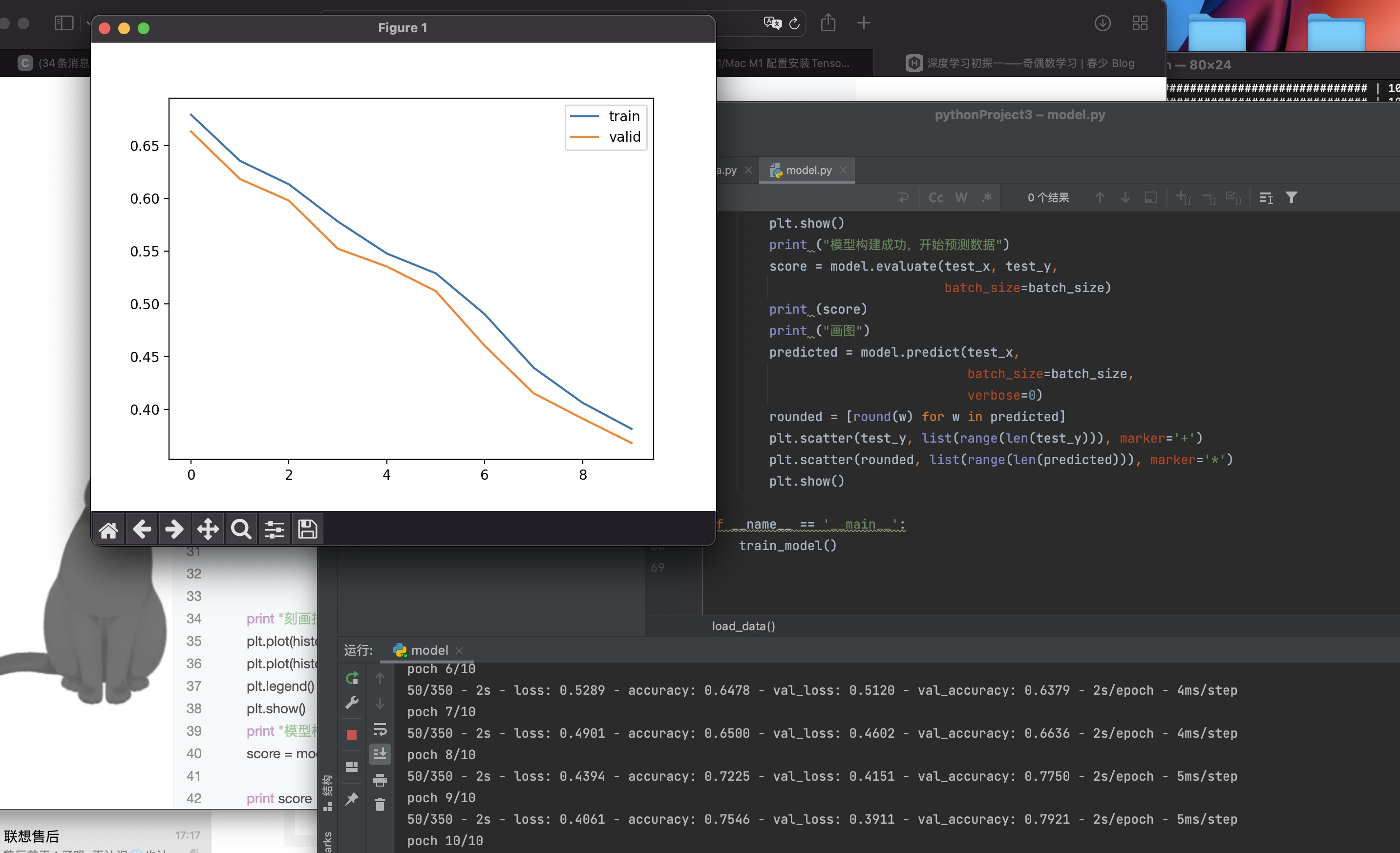
# print ("刻画损失函数的变化趋势")
#
# plt.figure('f1')
# plt.plot(history.history['loss'], label='train')
# plt.plot(history.history['val_loss'], label='valid')
# plt.legend()
# plt.show()
print ("模型构建成功,开始预测数据")
score = model.evaluate(test_x, test_y,
batch_size=batch_size)
print (score)
print ("画图")
predicted = model.predict(test_x,
batch_size=batch_size,
verbose=0)
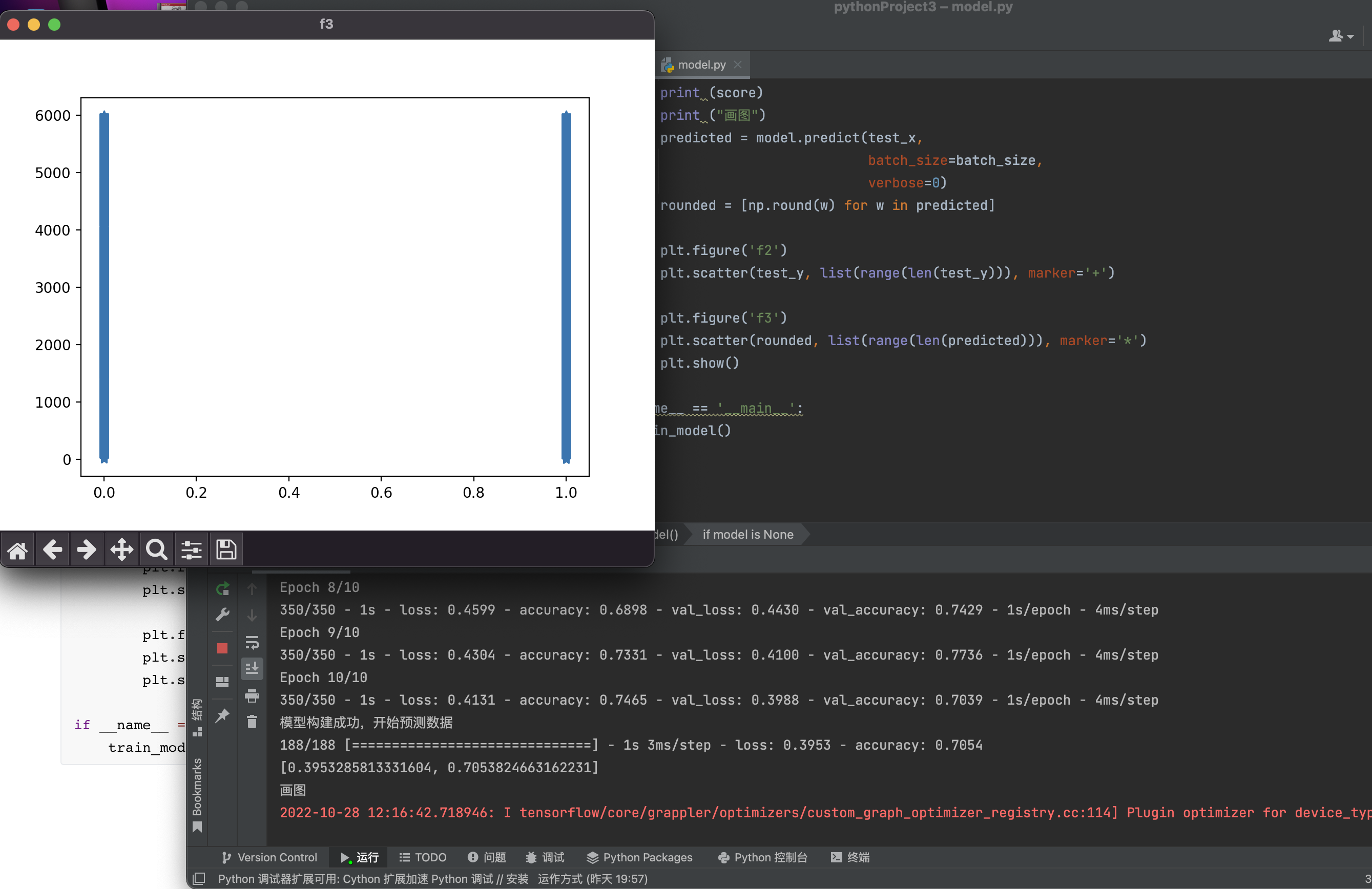
rounded = [np.round(w) for w in predicted]
plt.figure('f2')
plt.scatter(test_y, list(range(len(test_y))), marker='+')
plt.figure('f3')
plt.scatter(rounded, list(range(len(predicted))), marker='*')
plt.show()
if __name__ == '__main__':
train_model()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号