


分布式系统基础总结
一直在搞分布式系统,Hadoop, Spark, Kafka, ZooKeeper之类的都玩过,然而以前只是简单地用用各个开源组件实现,并没有系统地学习其中的原理和算法。最近在跟着MIT 6.824课程学习分布式系统的各种理论原理,这里就来简单总结下分布式系统中的一些基础内容吧~
CAP Theory
CAP Theory阐述了分布式系统中的一个事实:一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)不能同时保证。三个只能选择两个

假设有两台机器A、B,两者之间互相同步保持数据的一致性。现在B由于网络原因不能与A通信(Network Partition),假设某个client向A写入数据,现在有两种选择:
- A拒绝写入,这样能保证与B的一致性,但是牺牲了可用性
- A允许写入,但是这样就不能保证与B的一致性了
Network Partition是必然的,网络非常可能出现问题(断线、超时),因此CAP理论一般只能AP或CP,而CA一般较难实现。
- CP: 要实现一致性,则需要一定的一致性算法,一般是基于多数派表决的,如Paxos和Raft
- AP: 要实现可用性,则要有一定的策略决议到底用哪个数据,并且数据一般要进行冗余备份(replication)
当然,在上面的例子中,A可以先允许写入,等B的网络恢复以后再同步至B(根据CAP原理这样不能保证强一致性了,但是可以考虑实现最终一致性)。
一致性哈希
分布式Key-Value Store中的key映射问题。
- 传统
hash(x) % N算法的弊端:不利于架构的伸缩性 - 一致性哈希将哈希值映射到一个哈希环上,然后将数据进行哈希处理后映射到哈希环上,再把节点进行哈希处理映射到哈希环上,数据将选择最近的节点存储
- 伸缩性:节点删除时,原有的数据将会就近迁移,其他数据不用迁移;节点增加时也相似
- 保证负载均衡:虚拟节点
拜占庭将军问题
最复杂的情况:自己发的包被截;对方发的包自己收不到;内部有节点捣乱,造成不一致。
FLP Impossibility
Impossibility of Distributed Consensus with One Faulty Process 这篇论文提到:
No completely asynchronous consensus protocol can tolerate even a single unannounced process death.
假设节点只有崩溃这一种异常行为,网络是可靠的,并且不考虑异步通信下的时序差异。FLP Impossibility指出在异步网络环境中只要有一个故障节点, 任何Consensus算法都无法保证行为正确。
Lease机制
Lease(租约)机制应用非常广泛:
- 可用作授权来进行同步等操作(如Append)
- 可用作读锁/写锁(分布式锁)
租约的一个关键点就是有效期,过了有效期可以续约。如果不可用就收回租约,给另一台服务器权限。
实际应用:
- GFS: Master grant to ChunckServer
思考:Lease == Lock?
Quorum机制
多数表决机制在分布式系统中通常有两个应用场景:
- Leader Election
- Replication (NWR机制)
理论基础:鸽巢原理
Consensus问题
Consensus条件
- Termination: 最终必须决议出结果
- Validity:
- Integrity
- Agreement
2PC/3PC
2PC在proposer和某个voter都挂掉的时候会阻塞(原因:别的节点没有对应voter的消息,只能阻塞等待此voter恢复)
3PC添加了一个 prepare-commit 阶段用于准备提交工作,这里面可以实现事务的回滚。
缺点:效率貌似很低。。。分布式事务用2PC会特别蛋疼
Paxos
推演:
- First Accept/Last Accept都不可以(结合时序图)
- 一个阶段不行,自然想到两个阶段:发起决议以及提交决议
- One Proposer -> One Acceptor 挂了就gg了
- One Proposer -> Many Acceptors (规则:先到先投)
- Many Proposers -> Many Acceptors (很容易乱。。。)
Paxos引入了Log ID (num, value),共有三个角色,两个阶段。
- Proposer: 决议发起者,需要等待多数派表决
- Acceptor: 决议投票者,对收到的Propose进行表决并返回
- Learner: 最水的角色,学习到投票的结果即可
分布式一致性算法(Paxos, Raft, Chubby, Zab)待详细总结。。。
时序问题
Lamport Timestamp
一般我们不关心分布式系统中某个过程的绝对时间,而只关注两个事件之间的相对时间。
在一个系统的事件集合E上定义一种偏序关系->,满足:
- 如果a与b发生在同一个进程中,且a先于b发生,则有
a -> b - 进程间通信,a代表进程Pi发出消息m,b代表另一个进程Pj接收消息m,则有
a -> b - 传递性:若
a -> b, b -> c,则a -> c
定义并发:a -> b与b -> a均不成立则为并发情况
引入Lamport逻辑时钟。一个时钟本质上是一个事件到实数的映射(假设时间是连续的)。对于每一个进程Pi,都有其对应的时钟Ci。
分布式系统中的全局信息实际上是对各个实体信息的叠加(Q:重合怎么办?)
可以看到Lamport Timestamp必须要求两个事件有先后顺序关系,因而在时序图上不好表示concurrent。由此引入Vector Clock。
Vector Clock
Vector Clock是对Lamport Timestamp的演进。它不仅保存了自身的timestamp,而且还保留了根节点的timestamp。
Vector Clock(Version Vector)只能用于发现数据冲突,但是想要解决数据冲突还要留给用户去定夺(就好比git commit出现conflicts,需要手工解决一样),当然也可以设置某种策略来直接解决冲突(保留最新或集群内多数表决)。
结合时序图理解会更好(图来自维基百科):
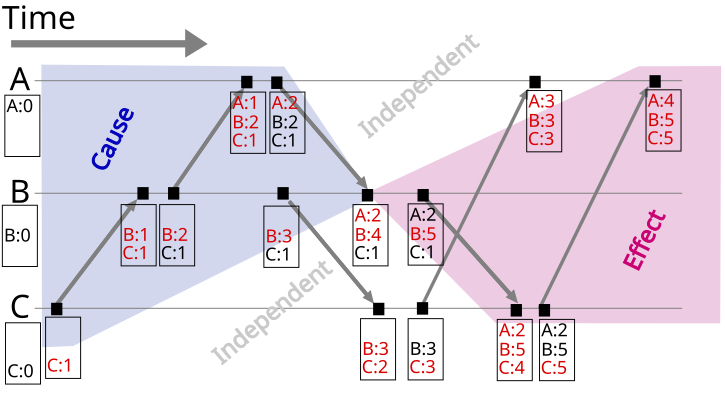
可能出现的问题:Vector Clock过多。解决方案:剪枝(如果超过某个阈值就把最初的那个给扔掉;要是现在还依赖最初的那个clock的话可能就会造成一些问题(思考:如何解决?)

