
工控安全入门(九)——工控协议逆向初探
在工控领域,我们会遇到许多协议,为了进行安全研究,经常需要对协议的具体内容进行探索,今天我们就来聊聊关于工控协议逆向的问题。
在接下来的几篇文章中,我会简单介绍一下常用的协议逆向方法并配合一些实战,当然,从未知到已知的探索过程不仅仅需要代码上的实践,还需要数学上的分析与建模,所以在这几篇文章中不仅会有工控、协议的知识,还有大量的数学内容,因为我本身不是搞学术研究的,所以一些东西也只是略微了解而已,如果大佬们发现有什么错误请在评论中指出,我一定仔细查看。还要感谢@bitpeach大佬的文章让我了解到了很多知识。
按照分类,工控协议一般可以分为以下两种:
- 公开协议,这里的公开主要是说它是公开发表并且无版权要求的,我们介绍的modbus就属于这一种。
- 私有协议,顾名思义就是厂家自有的,为正式公开的,我们介绍过的西门子S7comm就属于这一种。
但不论是公开协议还是私有协议往往都具有一定的未知性。像是modbus,虽说大部分信息我们都是了解的,但是还有很多function code是厂商自己偷偷用的,像是施耐德我们之前就提过,有自己的0x5a来实现一堆高权限操作;S7comm这类的私有协议就更不用说了,要不是前辈们的逆向工程,我们其实是对协议内容一无所知的。我们今天要聊的就是对于这类未知的逆向过程。
对于协议的逆向我们也是分成两类方法:
- 基于网络轨迹的逆向,即对抓取的流量包进行分析,利用各类数学分析、推理,对数据进行切分、关系预测、生成状态机等等,从而推断出协议的部分内容、进行fuzz等操作。
- 基于接收端程序的逆向,即对协议数据的接收端程序进行逆向分析,从而得到协议的内容,这也是现在常用的方法,像是最近S7commPlus的逆向就是借助分析上位机的OMSp_core_managed.dll组件来实现的。
当然,这两种逆向方式都需要结合相应的设备进行调试来完成,也完全可以两种方式结合,先基于网络轨迹大致判断协议格式、关系,再通过逆向程序加以完善。这篇文章我们就首先看看基于网络轨迹的逆向。
基于网络轨迹的逆向
考虑到我们为入门教程,所以我们选用的数据包并不是真正的”未知“协议,我们使用系列第一篇文章的modbus数据包来进行分析,我们将其TCP以上均视为未知部分
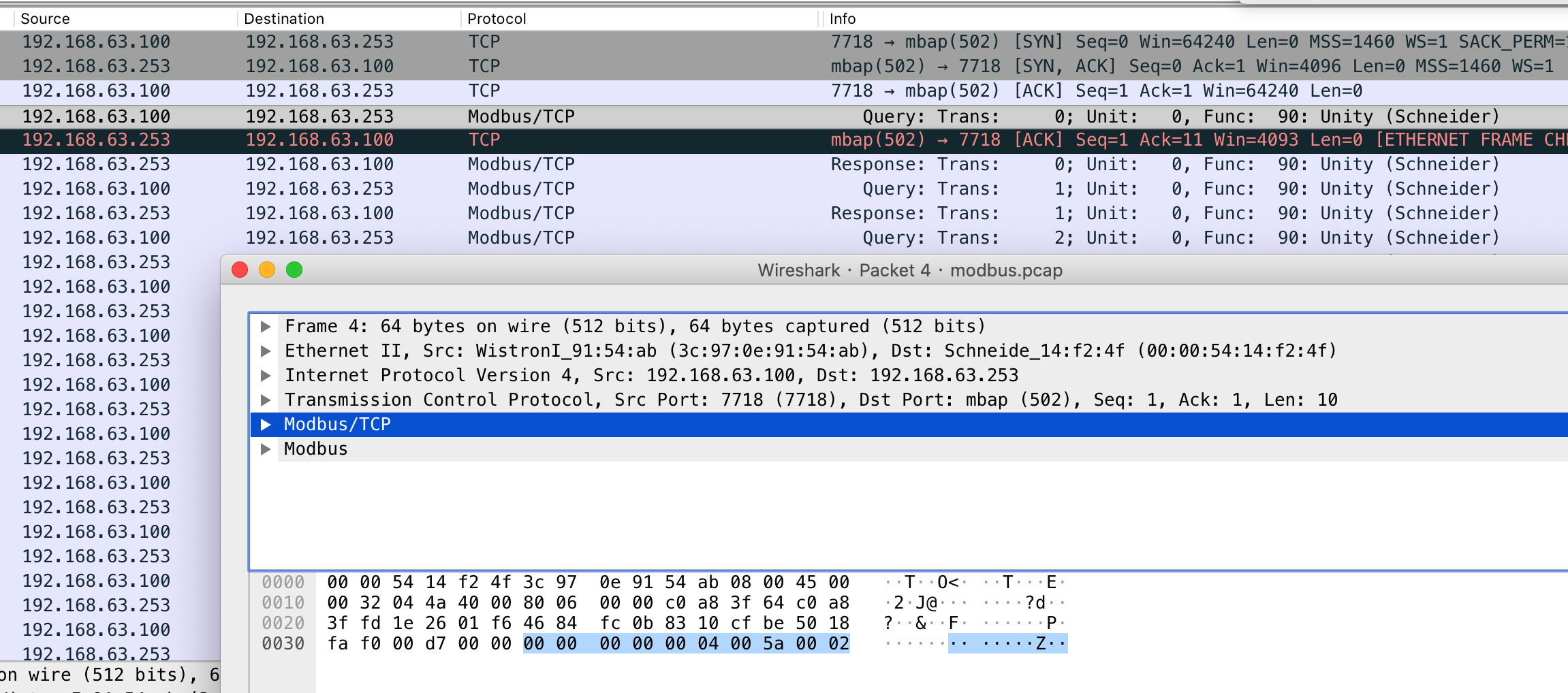
如图的包,我们将modbus部分的数据视作
x00x00x00x00x00x04x00Zx00x02
现在看上去还是毫无头绪?没关系,我们一点点来
确定协议字段的基本知识
确定协议字段说白了就是根据流量包中的大量流量对比,”猜“出来哪些数据应该是一个字段,这个过程中涉及到协议分析算法,而这些算法又是由一些重要的数学模型、算法构成的,我选取了《Network Protocol Analysis using Bioinformatics Algorithms》、《基于网络协议逆向分析的远程控制木马漏洞挖掘》两篇论文中的某些部分进行简要说明,来大致了解一下这部分理论知识(因为我们是要做实际分析,所以涉及到研究部分的算法等理论我就不再细化了)。
LD(LevenShtein Distance),假设我们有A、B两个字符串,A经过插入、删除、替换字符的最短过程变为B,经过的步骤表示两个字符串的差异。如:
A = "modbus"
B = "modicon"
显然我们需要把子串”bus“换为”ico“,然后添加字符”n“,所以LD(A,B)=4,python实现代码如下:
def normal_leven(str1, str2):
len_str1 = len(str1) + 1
len_str2 = len(str2) + 1
# 创建矩阵
matrix = [0 for n in range(len_str1 * len_str2)]
# init x轴
for i in range(len_str1):
matrix[i] = i
# init y轴
for j in range(0, len(matrix), len_str1):
if j % len_str1 == 0:
matrix[j] = j // len_str1
for i in range(1, len_str1):
for j in range(1, len_str2):
if str1[i - 1] == str2[j - 1]:
cost = 0
else:
cost = 1
# 若ai=bj,则LD(i,j)=LD(i-1,j-1) 取矩阵对角的值
# #若ai≠bj,则LD(i,j)=Min(LD(i-1,j-1),LD(i-1,j),LD(i,j-1))+1 在对角,左边,上边,取最小值+1
matrix[j * len_str1 + i] = min(matrix[(j - 1) * len_str1 + i] + 1, matrix[j * len_str1 + (i - 1)] + 1,matrix[(j - 1) * len_str1 + (i - 1)] + cost)
return matrix[-1]
str1 = ''
str2 = ''
a = normal_leven(str1, str2)
print(1-a/max(len(str1), len(str2)))
print(type(1-a/max(len(str1), len(str2)))
LCS(Longest common subsequence),这个和大家理解的两个字符串求最大子序列有些不同,这里的字符并不一定要连续出现。如:A与B的最长子序列为”mod“,所以LCS(A,B)=3,而我们将A变为”m o d b u s“,LCS(A,B)仍然为3,所以,如果LCS(X,Y)=0,那么立即推,X、Y没有任何一个字符相同。在论文中包括了GSA(全局序列对比)与LSA(局部序列对比),GSA用在对协议域的理解上,而LCS则是对相似序列进行聚类。编程中,我们可以使用Needleman/Wunsch算法来求解。我们还是以上面的两个字符串为例
| m | o | d | b | u | s | ||
|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| m | 0 | ||||||
| o | 0 | ||||||
| d | 0 | ||||||
| i | 0 | ||||||
| c | 0 | ||||||
| o | 0 | ||||||
| n | 0 |
首先我们将矩阵初始化,即上述表格,接着按照公式进行填充
若ai=bj,则LCS(i,j)=LCS(i-1,j-1)+1
若ai≠bj,则LCS(i,j)=Max(LCS(i-1,j-1),LCS(i-1,j),LCS(i,j-1))
该公式其实非常简单,如果行列字符一样,则填充的值为它左上角的值加1,如果不一样就是左上角、上边、左边的最大值。按照这个标准我们从第一行开始填,得到如下结果
| m | o | d | b | u | s | ||
|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| m | 0 | 1 | 1 | 1 | 1 | 1 | 1 |
| o | 0 | 1 | 2 | 2 | 2 | 2 | 2 |
| d | 0 | 1 | 2 | 3 | 3 | 3 | 3 |
| i | 0 | 1 | 2 | 3 | 3 | 3 | 3 |
| c | 0 | 1 | 2 | 3 | 3 | 3 | 3 |
| o | 0 | 1 | 2 | 3 | 3 | 3 | 3 |
| n | 0 | 1 | 2 | 3 | 3 | 3 | 3 |
然后从右下角进行回溯操作,若ai=bj,则走左上角;若ai≠bj,则到左上角、上边、左边中值最大的单元格,相同的话优先级按照左上角、上边、左边的顺序,直到左上角为止。最终按照如下规则写出表达式(_表示插入字符或者是删除字符操作)
- 若走左上角单元格,A+=ai,B+=bi
- 若走到上边单元格,A+=ai,B+=_
- 若走到左边单元格,A+=_,B+=bi
多序列对比,实际上是LCS的扩展,采用引导树、非加权成对群算术平均法等来进行,非加权成对群算术平均法即UPGMA算法,这是一种聚类算法,在我们前面已经得到的距离的基础上进行操作,将距离最小的两个节点进行聚合,然后再次计算新的节点间的距离,最终生成演化树。
演化树(Phylogenetic tree),在多序列对比中生成的树,其实就像是生物进化图那样,由根衍生出一个一个节点,如图所示为DNA系统的演化树,我们所要建立的演化树是关于协议的数据的,通过这种方式来寻找协议流量中的相似部分。
建树的方法主要有两大类,一类是基于距离的,一类的基于character的。我们上面提到的就是基于距离的建树方式,一般来讲,基于距离的方法将数据抽象为距离,从而有了较快的处理速度,但是其抽象过程中会有信息量的损失;而基于character的方法是在一个已有的模型上建立的,所以需要有一个靠谱的模型,但好处就是我们的信息不会丢失。
广义后缀树(Generalized Suffix Tree),用来实现求解最大公共子串、匹配字符串、找重复串等等,这里说的最大公共子串就是我们平时理解的:连续的、相同的字符串。比如”modbus“和”m od i c o n“,那么这俩的最大公共子串就是od而不是上面的”mod“。该技术常用于病毒的特征码提取。下面举个栗子来解释一下:
假设我们现在有modbus、modicon两个字符串,对于modbus,后缀有:
s
us
bus
dbus
obus
modbus
我们将其按字典序排序,然后建立树,根节为空,每个字母为一个节点,从根到叶子就对应了一个单词,如图所示
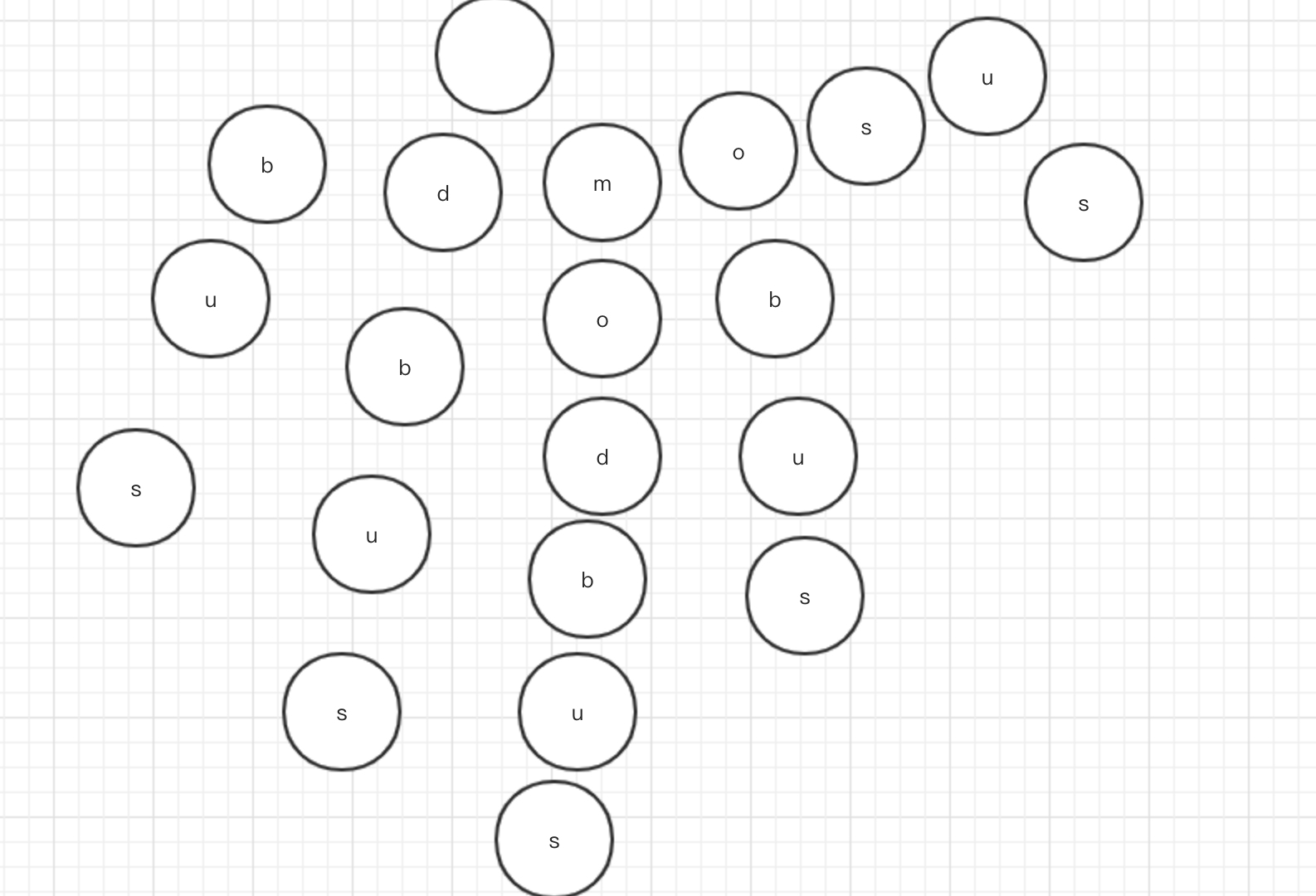
我们还可以对单节点链条进行压缩,当然这个单词所有的链条都是单节点的……然后我们将modicon也按后缀,然后插入到这个树中,重合的部分即为公共子串(因为我不知道怎么画图,所以你们就自行想象一下吧)。
聚类(cluster),大白话就是分类,一是用来对流量进行粗略分类,二是用来对提取的字符串进行分类。具体涉及的包括了k紧邻算法、关键词树算法等等
以上是一些基础性的问题,有了以上的基础,我们可以大致将流量包的分析归为以下几步:
- 粗略聚类,提取主要分析的流量,并将相似的流量首先分到一起
- 采用各类算法来对字段进行划分
- 根据某些字段再次进行聚类
- 对一类的流量进行关系分析
Netzob划分数据
netzob是一种基于网络轨迹的逆向工具,目的就是为了分析未知协议,当然还有其他的一些,比如PI等等,我们这里就以netzob为例进行操作。
首先当然是要安装,netzob需要大量的前置包,安装很麻烦,很有可能遇到各种错误,因为和实际环境有关,所以我也没法全部列举出来,大家安装时自行尝试吧
apt-get install python-dev #提前需要安装的库
apt-get install python-impacket
apt-get install python-setuptools
apt-get install libxml2-dev
apt-get install libxslt-dev
apt-get install gtk3
apt-get install graphviz
git clone https://github.com/netzob/netzob.git
cd netzob
python3 setup.py develop --user #开发者友好模式
以上步骤完成后我们就可以在python3中import了
from netzob.all import *
当然也可以python3 setup.py install来安装友好的图形化界面,使用./netzob即可打开,但是在我的机器上出现了问题,大家可以自行尝试。如果实在是安装不成功的同学,官方也给了docker镜像
docker pull netzob/netzob
docker run --rm -it -v $(pwd):/data netzob/netzob #pwd为当前位置,挂载到根目录下的data
搞定后我们就可以开始干活了
m = PCAPImporter.readFile("modbus.pcap").values()
该条语句用来导入我们的流量包,我们可以查看一下它的说明
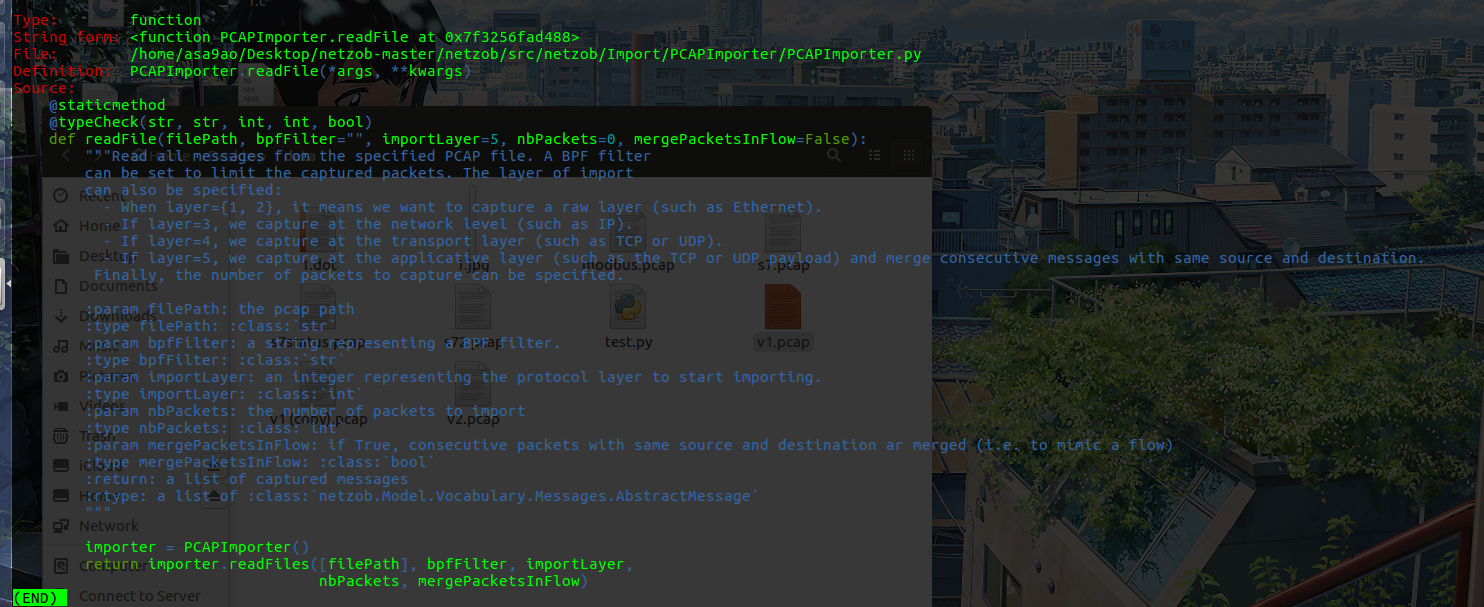
参数主要关注两个,一个是importLayer,这是指定我们要分析的data是在哪一层,以我们modbus来说,是基于tcp的,所以data就相当于是tcp往上一层,所以填5,如果是S7comm呢则要考虑你要分析哪一层再进行选择;另一个是bpfFilter(Berkeley Packet Filter),也即是伯克利包过滤的意思,这是一种语法,可以指定你要选择哪些流量,如下所示:
host 0.0.0.0 and (port 138) #筛选出ip为0.0.0.0且端口为138的流量包
接着我们进行符号化,即筛选出所有相似的流量,这里就涉及到了我们之前提到的数学知识
s = Symbol(messages = m)
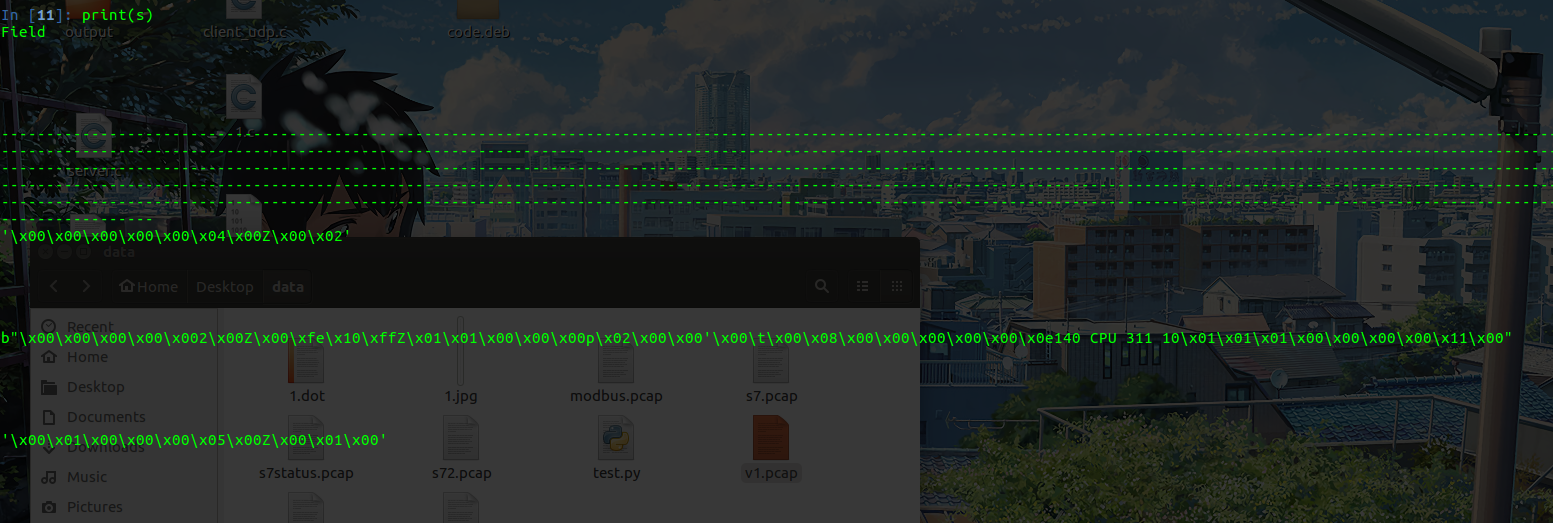
可以看到提取出来的就是相似的流量就是我们流量包中的modbus部分,这一步就相当于我们上面提到的粗略聚类,Netzob将modbus部分的流量提取了出来,并将这些流量放到了一起。但是现在我们还是啥也看不出来,我们希望能够对data再次进行分析,对比得到哪些字符应该是一块的,哪些是分开的。
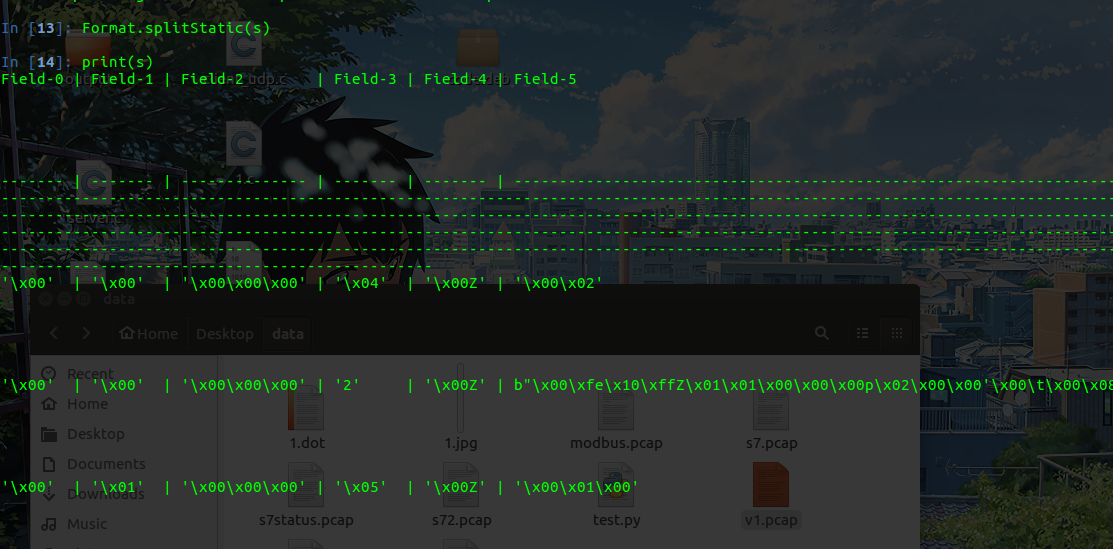
Format.splitStatic(s)
该方法用来将我们的data根据相似性与静态分布规律,划分为几个Field,当然,我们也可以通过“肉眼观察法”使用splitDelimiter(symbol,ASCII(“Z”)来进行人工的划分。这一步相当于“采用各类算法来对字段进行划分”,也是核心部分,如图即为划分Field后的symbol
我们就以第一组为例,打开wireshark来检查一下分析的结果
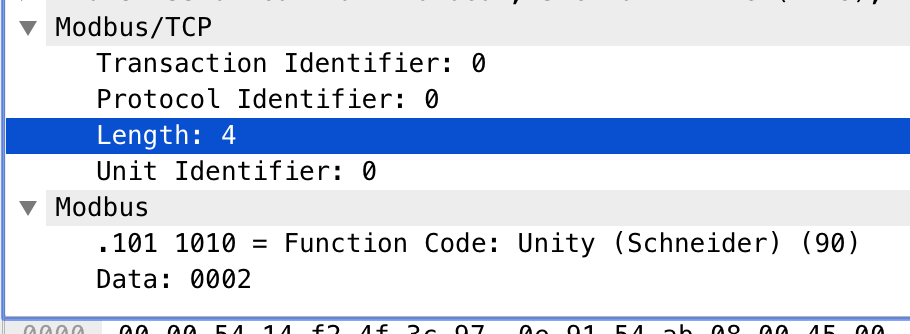
真正的划分如下:
'x00x00' | 'x00x00' | 'x00x04' | 'x00Z' | 'x00x02'
可以看到差距较大,观察流量包后发现,主要原因是因为modbus的前四个字段在该流量包中区分不太“明显“,以第一个字段举例,modbus用了两个字节表示事务标识符(即Transaction identifier ),但在这些流量中最多最多就是x00x01,根本就没有用到低字节,所以在划分时被认为是两个字段了。同理,长度字段也是如此,该流量包中的length也没有用到低字节,所以也被划为了两个字段。
知道了情况我们就可以对症下药了,一是我们引入新的流量包,选取一些数据量较大、情况足够全面的流量,可以稍加完善;二是我们通过不断的尝试和日常积累进行手动划分,比如每种协议基本都有的length字段、标识字段等等进行手动划分。但是由于协议本身的规定与限制(比如,虽然给了两个字节,但是实际上并没有使用低字节,厂商只是为了扩展或者对齐),我们只可能完善,但绝不可能完美划分字段,不过仅仅是这样对我们的帮助已经很大了。
之后我们要进行的步骤为“根据某些字段再次进行聚类”,但是这里由于我们对于哪个是关键字段并不清楚,所以暂时放弃这一步。
接下来我们要做的工作就是要猜测字段的含义,当然我们通过这种方式绝对不可能“猜”出来“Z”是施耐德专用的功能码,我们能做的是推理这些字段之间的关系。
for symbol in symbols.values():
rels = RelationFinder.findOnSymbol(symbol)
print("[+] Relations found: ")
for rel in rels:
print(" " + rel["relation_type"] + ", between '" + rel["x_attribute"] + "' of:")
print(" " + str('-'.join([f.name for f in rel["x_fields"]])))
p = [v.getValues()[:] for v in rel["x_fields"]]
print(" " + str(p))
print(" " + "and '" + rel["y_attribute"] + "' of:")
print(" " + str('-'.join([f.name for f in rel["y_fields"]])))
p = [v.getValues()[:] for v in rel["y_fields"]]
print(" " + str(p))
RelationFinder为我们提供了不同的关系分析方法,这里我们选择使用基于符号的分析方法,也就是对我们之前进行过Field划分的符号进行分析。
当然,这只能探索符号内部的关系,像是我们的数据包,我们只能发现length字段,但是已经是非常大的进步。为我们之后进行测试、逆向程序都省下了不少功夫。
总结
虽然说了不少东西,但大多还是以理论为主,实际上代码就撩撩几行,当然这也是我们协议分析的第一步,在之后的文章中我们将基于这部分内容,继续进行探索。

