[CVPR2021]Beyond Self-attention External Attention using Two Linear Layers for Visual Tasks
这篇论文已经不是推荐系统系列论文当中了,而是作为讨论注意力机制以及普通的全连接层之间的关系,也就是我们是否需要使用那么复杂的注意力机制来完成各种任务。
介绍
注意力机制,特别是自注意力机制,在视觉任务的深度特征表示中发挥着越来越重要的作用。自我注意机制通过计算特征的加权和来更新每个位置的特征,使用所有位置的成对亲和力来捕捉单个样本内的长程依赖性。然而,自我注意机制具有二次复杂性,并且忽略了不同样本之间的潜在相关性。本文提出了一种新的注意机制,我们称之为外部注意,它基于两个外部的、小的、可学习的和共享的记忆,可以通过简单地使用两个级联的线性层和两个归一化层来实现;
它可以方便地取代现有流行结构中的自我注意。外部注意力具有线性复杂性,并隐含地考虑了所有样本之间的相关性。在图像分类、语义分割、图像生成、点云分类和点云分割任务上的大量实验表明,我们的方法提供了与自我注意机制及其一些变体相当或更高的性能,而且计算和内存成本低得多。
自注意力机制的重点是通过聚合单个样本中所有其他位置的特征来完善每个位置的表示,这导致了样本中位置数量的二次计算复杂性。此外,自我关注集中在单个样本中不同位置之间的自我关联性,而忽略了与其他样本的潜在关联性。不难看出,不同样本之间的潜在关联性有助于促进更好的特征表示。
贡献
本文提出了一种新型的轻量级注意力机制,我们称之为外部注意力,如下图所示,为了计算自我注意力,我们首先通过计算自我查询(self-query)向量和自我键(self-key)向量之间的亲和力来计算一个注意力图,然后通过用这个注意力图对自我值向量加权来生成一个新的特征图。外部注意的工作方式不同。我们首先通过计算自我查询向量和外部可学习的键记忆(key-memory)之间的亲和力来计算注意图,然后通过将这个注意图乘以另一个外部可学习的值记忆(value-memory)来产生一个完善的特征图。
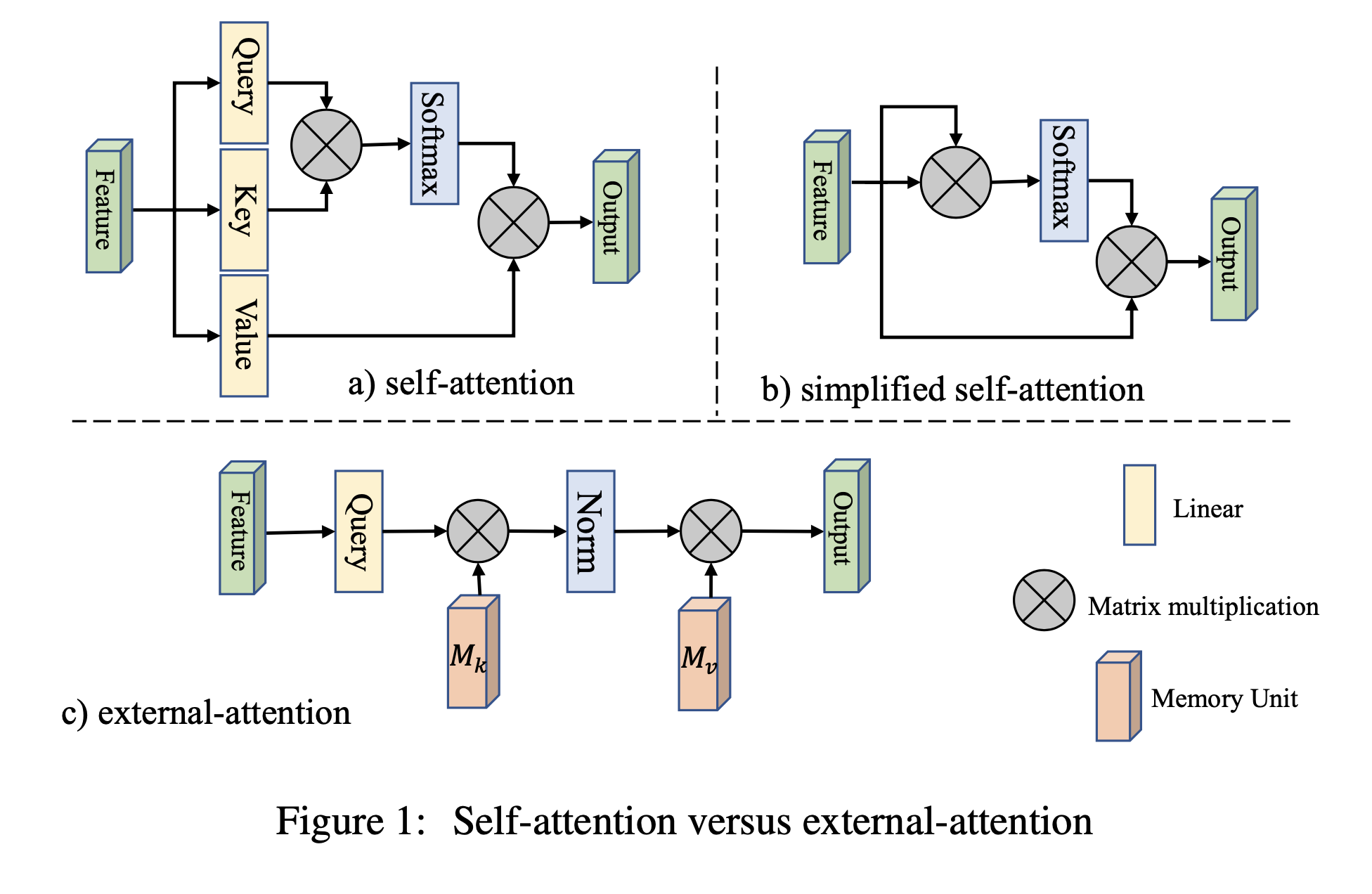
这两个记忆力单元都是通过线性层完成的,可以通过反向梯度传播进行优化。它们独立于单个样本,并在整个数据集中共享,这起到了强大的正则化作用,提高了注意力机制的泛化能力。
方法
图a 自注意力机制
我们首先观察自注意力机制,在自注意力机制当中,我们有一个特征图\(F=\mathbb{R}^{N\times d}\),在这里\(N\)是像素的数量,\(d\)是特征的维度。自注意力机制将输入映射到查询矩阵\(Q=\mathbb{R}^{N\times d'}\),键矩阵\(K=\mathbb{R}^{N\times d}\)以及值矩阵\(V=\mathbb{R}^{N\times d}\)。自注意力机制可以被公式化成如下形式:
\(A=\mathbb{R}^{N\times N}\)是注意力矩阵,\(\alpha_{i,j}\)是两个坐标点像素之间的相似度。
图b 简化自注意力机制
不像自注意力机制还需要QKV矩阵,我们直接对输入的特征进行计算,
在这里,注意力图是通过计算特征空间中的像素级相似度得到的,而输出是输入的精炼特征表示。
从上述的两种注意力机制当中,我们可以得到尽管被简化但是仍然是\(O(dN^2)\)的计算复杂度,这种复杂度使得注意力机制在视觉任务当中难以应用。
当可视化注意图时,我们发现大多数像素只与其他几个像素密切相关,一个N-N的注意矩阵可能是多余的。因此,细化的特征可以通过使用需要的值来实现。因此,我们提出了一个外部注意力模块作为替代方案,该模块计算输入像素和外部记忆单元的注意力,注意力机制单元\(M=\mathbb{R}^{S\times d}\),如:
在这里\(M\)是可学习的参数,独立于输入的特征,在全部训练集当中扮演着记忆力的角色。在实际的操作当中,我们用了两个记忆力单元,作为键和值记忆力,用来增加网络的容量,具体公式为
在归一化的时候使用了double-normalization,也就是分别对行和列进行归一化。
最终的实验结果表明,在图像分类,语义分割,图像生成,点云分类等等都取得了不错的结果。
总结
本文提出了外部注意力,这是一种新颖的轻量级但有效的注意力机制,对各种视觉任务都有用。在外部注意力中采用的两个外部记忆单元可以被看作是整个数据集的字典,并且能够为输入学习一个更有代表性的特征,同时权衡计算成本。我们希望外部注意力能激发其在其他领域的实际应用和研究,如NLP。
文章转载请注明出处,喜欢文章的话请我喝一杯咖啡吧!在右边赞助里面哦!谢谢! NoMornings.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号