
推荐系统实践 0x0f AutoRec
从这一篇开始,我们开始学习深度学习推荐模型,与传统的机器学习相比,深度学习模型的表达能力更强,并且更能够挖掘出数据中潜藏的模式。另外。深度学习模型结构也非常灵活,能够根据业务场景和数据结构进行调整。还是原来的样子,我会按照原理以及代码实现,再就是一些优缺点进行逐一介绍。
AutoRec
AutoRec可以说是最小的深度学习推荐系统了,它是一种单隐层神经网络推荐模型,将自编码器与协同过滤相结合。那么什么是自编码器呢?自编码器可以看做是一种压缩维度的工具,无论是图像、音频、还是文本,都能够通过自编码器转换成向量形式进行表达,假设我们的输入(无论是图像、音频等等)的数据向量是\(r\),那么希望通过自编码器的输出向量尽可能接近原来的数据输入\(r\)。
以下是论文原文
Our aim in this work is to design an item-based (user-based) autoencoder which can take as input each partially observed, project it into a low-dimensional latent (hidden) space, and then reconstruct in the output space to predict missing ratings for purposes of recommendation.
假设自编码器的重建函数是\(h(r;\theta)\),那么自编码器的目标函数是:
其中的\(S\)就是所有数据输入的向量结合。
一般来说,重建函数\(h(r;\theta)\)的参数量远远小于输入向量的维度,所以自编码器相当于完成了数据压缩和降维的工作。并且,通过自编码器生成的输出向量,使得自编码器的编码过程有一定的泛化能力,可以预测丢失的维度信息,这也是自编码器能够用于推荐系统的原因。
模型结构
在之前的文章中我们介绍了协同过滤的关键——共现矩阵。就是因为由\(m\)个用户以及\(n\)的物品形成的\(m\times n\)的共现矩阵维度太高,所以我们需要使用一个重建函数对共现矩阵里面的评分向量进行压缩,然后经过评分预估以及排序之后形成最终的排序列表。AutoRec使用了单隐层神经网络结构来实现自编码器的功能。如下图所示。
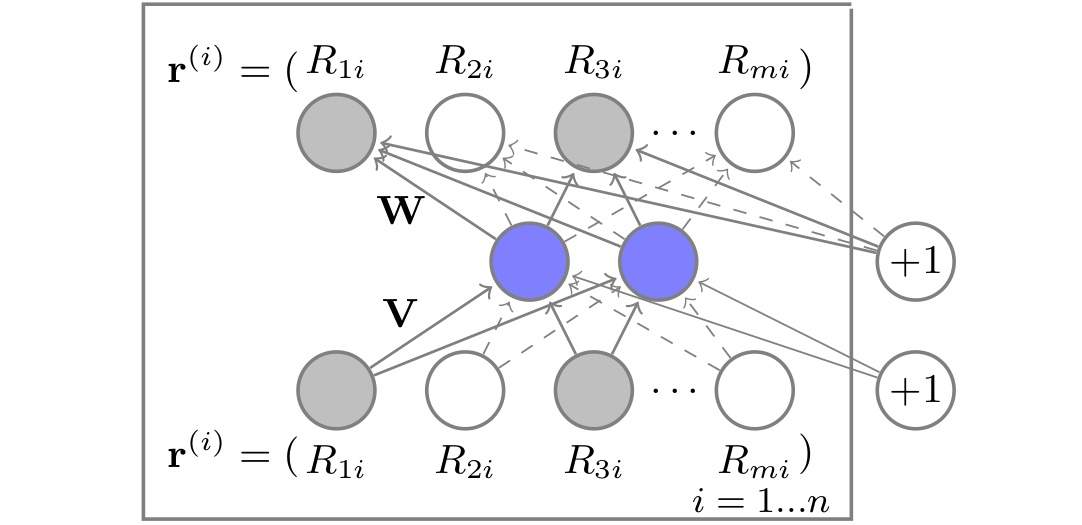
蓝色神经元代表模型的\(k\)维单隐层,也就是压缩之后的向量,\(V\)以及\(W\)代表从输入到隐层、从隐层到输出层的参数矩阵。那么写成重建函数的形式就是
\(f(\cdot)\)以及\(g(\cdot)\)为输出层和隐层神经元的激活函数。为了防止重构函数(单隐层神经网络、或者说三层神经网络)的过拟合,再加上\(L2\)正则化项,那么AutoRec的目标函数就是
\(||\cdot||_F\)为Frobenius范数.
推荐过程
当输入物品\(i\)的评分向量\(r^{(i)}\)时,得到的模型输出向量\(h(r;\theta)\)就是所有用户对物品\(i\)的评分预测。其中第\(u\)维就是用户\(u\)对物品\(i\)的预测评分\(\hat{R}_{ui}\)。那么再遍历一遍物品向量就可以得到该用户对所有物品的评分预测,然后进行排序就可以得到推荐列表。这种以物品评分向量作为输入的被称为I-AutoRec(Item based AutoRec),另外一种就是以用户评分向量作为输入的就是U-AutoRec(User based AutoRec)。U-Auto相比较于I-Auto优势是仅输入一次目标用户的用户向量就可以重建用户对所有物品的评分向量,也就是说仅需一次推断就可以得到用户的推荐列表,但是用户向量的稀疏性可能会影响模型推荐效果。
局限性
无法进行特征交叉,表达能力相对于后面更复杂的深度学习模型还是表达能力不足。由于AutoRec的简单明了,作为入门的深度学习推荐模型再合适不过了。
代码
## 模型部分
class Autorec(nn.Module):
def __init__(self,args, num_items):
super(Autorec, self).__init__()
self.args = args
#self.num_users = num_users
self.num_items = num_items
self.hidden_units = args.hidden_units
self.lambda_value = args.lambda_value
self.encoder = nn.Sequential(
nn.Linear(self.num_items, self.hidden_units),
nn.Sigmoid()
)
self.decoder = nn.Sequential(
nn.Linear(self.hidden_units, self.num_items),
)
def forward(self,torch_input):
encoder = self.encoder(torch_input)
decoder = self.decoder(encoder)
return decoder
## 损失函数部分
def loss(self, decoder, input, optimizer, mask_input):
cost = 0
temp2 = 0
cost += ((decoder - input) * mask_input).pow(2).sum()
rmse = cost
for i in optimizer.param_groups:
for j in i['params']:
# print(type(j.data), j.shape,j.data.dim())
if j.data.dim() == 2:
temp2 += torch.t(j.data).pow(2).sum()
cost += temp2 * self.lambda_value * 0.5
return cost, rmse
参考
深度学习推荐系统 王喆编著
AutoRec: Autoencoders Meet Collaborative Filtering
Github:NeWnIx5991/AutoRec-for-CF
文章转载请注明出处,喜欢文章的话请我喝一杯咖啡吧!在右边赞助里面哦!谢谢! NoMornings.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号