推荐系统实践 0x0d GBDT+LR
前一篇文章我们介绍了LR->FM->FFM的整个演化过程,我们也知道,效果最好的FFM,它的计算复杂度已经达到了令人发指的\(n^2k\)。其实就是这样,希望提高特征交叉的维度来弥补稀疏特征,不可避免的带来组合爆炸和计算复杂度过高的问题。这一篇,我们介绍一下Facebook提出的GBDT+LR的组合来解决特征组合和筛选的问题。
结构
整体的思路就是用GBDT构建特征工程,使用LR预估CTR这两步。由于这两步是独立的,所以不存在将LR的梯度回传到GBDT这类复杂问题。关于GBDT,就需要另外开一篇文章来讲解,这一部分网上也有很多小伙伴写了原理和实现,这里我推荐这篇文章,比较直观的介绍了GBDT的原理以及相应的代码实现,这里也简单介绍一下。
下图是Facebook论文中的模型示意图:
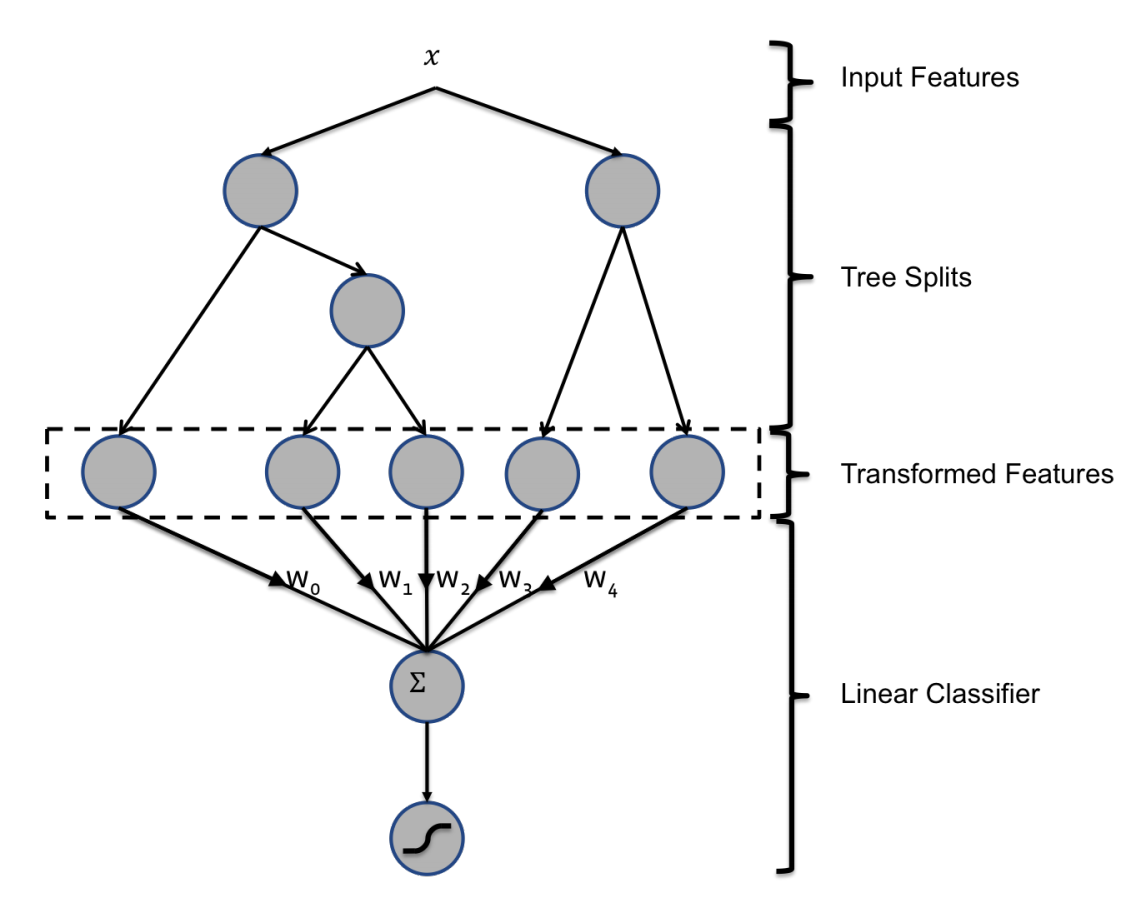
GBDT
GBDT是由多棵回归树组成的森林,后一棵树以前面森林的结果与真实结果的残差做为拟合目标。每棵树的生成都是一棵标准回归树的生成过程,因此回归树的节点分裂是自然的特征选择过程,多层节点的结构对特征进行了有效的组合,也高效的解决了特征选择以及特征组合的过程。通过GBDT可以完成从原始特征向量到离散型特征向量的转化。一般来说,训练样本进入某个子树之后,根据规则落入某个叶子节点将被设为1,其他叶子节点将被设为0.
举例来说,一棵典型的GBDT如下图所示:
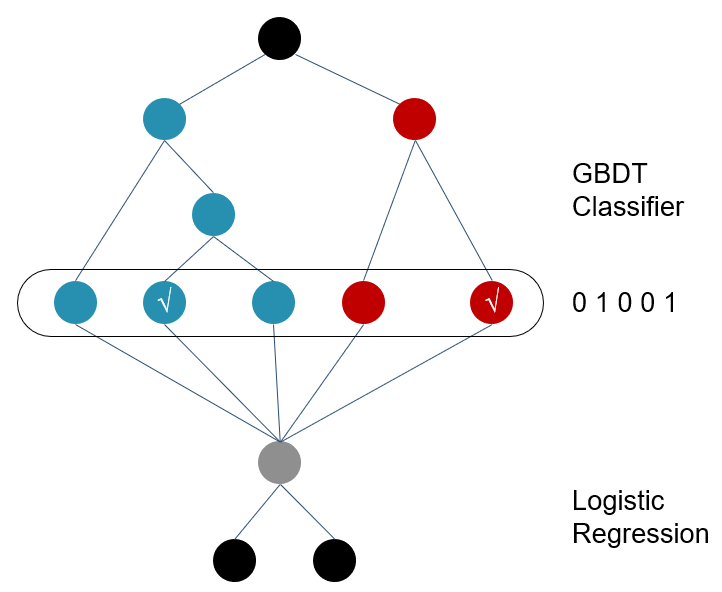
这颗GBDT由两棵子树构成,第一棵子树有三个叶子节点,第二棵子树有两个叶子节点。那么图中的第一棵子树的特征向量为[0,1,0],第二棵子树特征向量为[0,1],最终连接所有的特征向量得到的最终特征向量为[0,1,0,0,1]。
决策树的深度决定了特征交叉的阶数。这种特征组合能力要比FM系列的模型强得多,但是由于转换成离散特征向量导致丢失了大量特征的数值信息。
LR就不再介绍了,在上一篇文章中已经介绍过。GBDT的特征工程之后,数据不仅变得稀疏,而且由于弱分类器个数,叶子结点个数的影响,可能会导致新的训练数据特征维度过大的问题,因此,在LR这一层中,可使用正则化来减少过拟合的风险,在Facebook的论文中采用的是L1正则化。
GBDT+LR 代码
这里我们用的是Kaggle比赛数据集,Porto Seguro’s Safe Driver Prediction,也就是预测汽车保险保单持有人提出索赔的可能性。
以下代码就是我们用了lightgbm+LR的形式进行预测。
import lightgbm as lgb
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LogisticRegression
print('Load data...')
df_train = pd.read_csv('../dataset/DriverPrediction/train.csv')
df_test = pd.read_csv('../dataset/DriverPrediction/test.csv')
NUMERIC_COLS = [
"ps_reg_01",
"ps_reg_02",
"ps_reg_03",
"ps_car_12",
"ps_car_13",
"ps_car_14",
"ps_car_15",
]
print(df_test.head(10))
y_train = df_train['target'] # training label
# y_test = df_test['target'] # testing label
X_train = df_train[NUMERIC_COLS] # training dataset
X_test = df_test[NUMERIC_COLS] # testing dataset
# create dataset for lightgbm
lgb_train = lgb.Dataset(X_train, y_train)
# lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
lgb_eval = lgb.Dataset(X_test, reference=lgb_train)
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': {'binary_logloss'},
'num_leaves': 64,
'num_trees': 100,
'learning_rate': 0.01,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'verbose': 0
}
# number of leaves,will be used in feature transformation
num_leaf = 64
print('Start training...')
# train
gbm = lgb.train(params, lgb_train, num_boost_round=100, valid_sets=lgb_train)
print('Save model...')
# save model to file
gbm.save_model('model.txt')
print('Start predicting...')
# predict and get data on leaves, training data
y_pred = gbm.predict(X_train, pred_leaf=True)
print(np.array(y_pred).shape)
print(y_pred[:10])
print('Writing transformed training data')
transformed_training_matrix = np.zeros(
[len(y_pred), len(y_pred[0]) * num_leaf],
dtype=np.int64) # N * num_tress * num_leafs
for i in range(0, len(y_pred)):
temp = np.arange(len(y_pred[0])) * num_leaf + np.array(y_pred[i])
transformed_training_matrix[i][temp] += 1
y_pred = gbm.predict(X_test, pred_leaf=True)
print('Writing transformed testing data')
transformed_testing_matrix = np.zeros(
[len(y_pred), len(y_pred[0]) * num_leaf], dtype=np.int64)
for i in range(0, len(y_pred)):
temp = np.arange(len(y_pred[0])) * num_leaf + np.array(y_pred[i])
transformed_testing_matrix[i][temp] += 1
lm = LogisticRegression(penalty='l2', C=0.05) # logestic model construction
lm.fit(transformed_training_matrix, y_train) # fitting the data
y_pred_test = lm.predict_proba(
transformed_testing_matrix) # Give the probabilty on each label
print(y_pred_test)
# NE = (-1) / len(y_pred_test) * sum(
# ((1 + y_test) / 2 * np.log(y_pred_test[:, 1]) +
# (1 - y_test) / 2 * np.log(1 - y_pred_test[:, 1])))
# print("Normalized Cross Entropy " + str(NE))
小结
GBDT+LR的组合模型,意味着特征工程可以完全交给一个独立的模型来完成,模型的输入可以是原始的特征向量,而不必投入过多的人工筛选和模型设计能力,实现端到端训练。
参考
深度学习推荐系统 王喆编著
机器学习-一文理解GBDT的原理-20171001
GBDT分类的原理及Python实现
GBDT+LR算法解析及Python实现
推荐系统遇上深度学习(十)--GBDT+LR融合方案实战
文章转载请注明出处,喜欢文章的话请我喝一杯咖啡吧!在右边赞助里面哦!谢谢! NoMornings.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号