20192308王泽荣《python程序设计》实验四报告
20192308 王泽荣《python》实验四报告
课程:《python程序设计》
班级: 1923
姓名: 王泽荣
学号:20192308
实验教师:王志强
实验日期:2022年5月21日
必修/选修: 选修
1.实验内容和实验要求
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
(1)程序能运行,功能丰富。(需求提交源代码,并建议录制程序运行的视频)
(2)综合实践报告,要体现实验分析、设计、实现过程、结果等信息,格式规范,逻辑清晰,结构合理。
(3)在实践报告中,需要对全课进行总结,并写课程感想体会、意见和建议等。
(4)使用华为云服务器
2.实验选题和思路概括
- 实验选题:朴素贝叶斯分类器的实现
- 代码的大致思路:在计算前,先有一组由特征值和分类组成的训练集,而后通过计算先验概率,通过累加得到特征数有几个,进而得到一个保存条件概率的矩阵,然后就可以对样本进行分类了。
2. 实验过程及结果
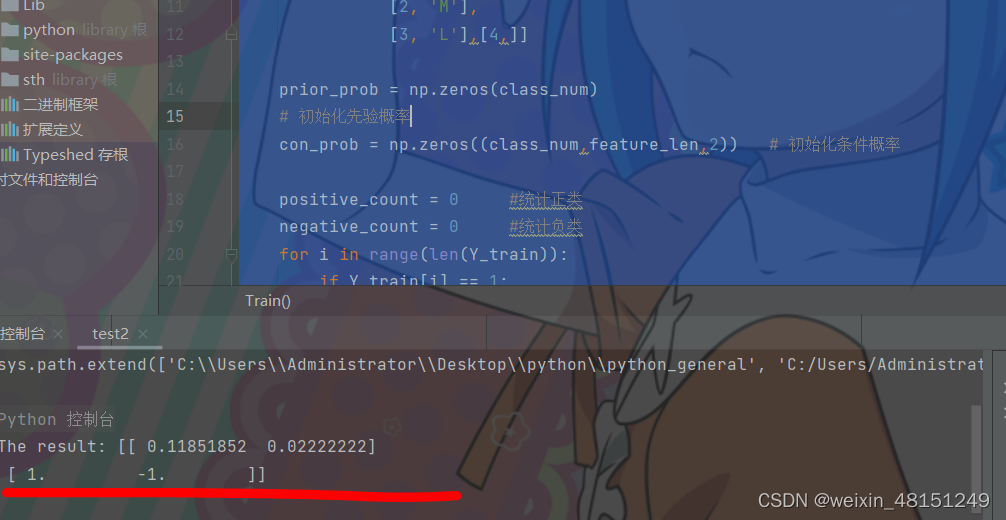
- 在pycharm上的运行结果(截图中result后的输出结果代表正类负类两个类别(+-1)和其对应的概率)
![。。。。]()
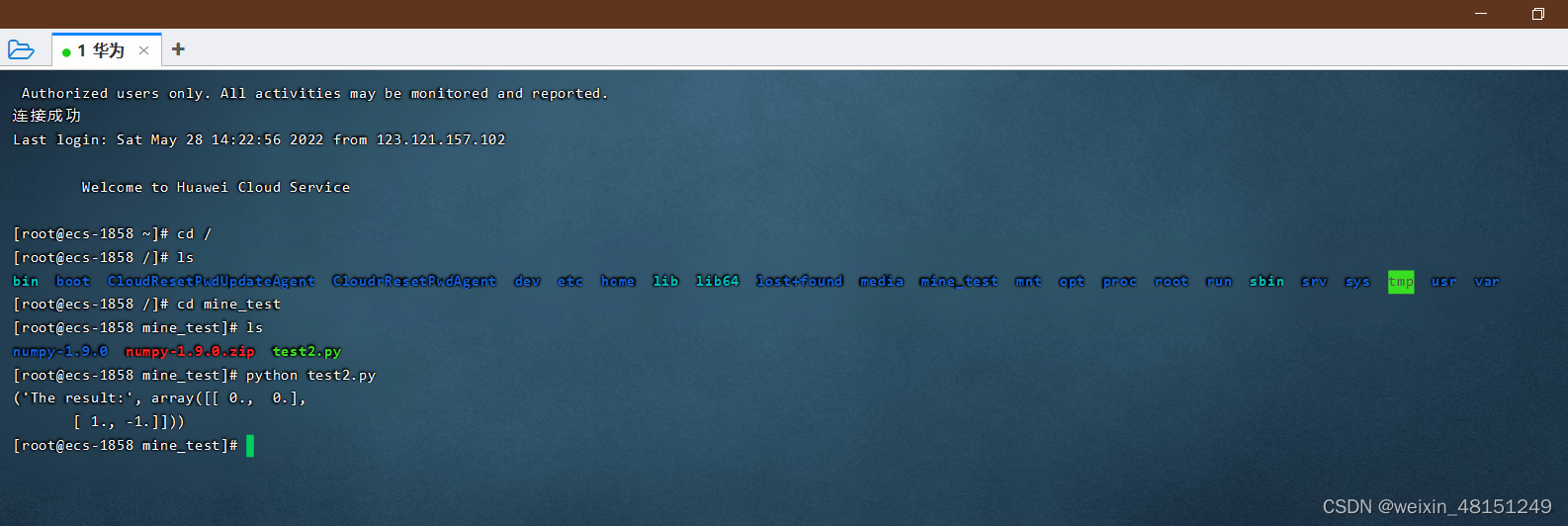
- 在华为云服务器上的运行结果
![在这里插入图片描述]()
点击展开代码
import numpy as np
#构造NB分类器
def Train(X_train, Y_train, feature):
global class_num,label
class_num = 2 #分类数目
label = [1, -1] #分类标签
feature_len = 3 #特征长度
#构造3×2的列表
feature = [[1, 'S'],
[2, 'M'],
[3, 'L'],[4,]]
prior_prob = np.zeros(class_num)
con_prob = np.zeros((class_num,feature_len,2)) # 初始化条件概率
positive_count = 0 #统计正类
negative_count = 0 #统计负类
for i in range(len(Y_train)):
if Y_train[i] == 1:
positive_count += 1
else:
negative_count += 1
prior_prob[0] = positive_count / len(Y_train) #求得正类的先验概率
prior_prob[1] = negative_count / len(Y_train) #求得负类的先验概率
'''
con_prob是一个2*3*2的三维列表,第一维是类别分类(class即+-1),第二维和第三维是一个3*2的特征分类,第三维的是哪一个特征,第二维是特征值
'''
#分为两个类别
for i in range(class_num):
#对特征按行遍历
for j in range(feature_len):
#遍历数据集,并依次做判断
for k in range(len(Y_train)):
if Y_train[k] == label[i]: #相同类别
if X_train[k][0] == feature[j][0]:#第几个(0号或1号特征值)的值相等,计数加个一
con_prob[i][j][0] += 1
if X_train[k][1] == feature[j][1]:
con_prob[i][j][1] += 1
class_label_num = [positive_count, negative_count] #存放各类型的数目
for i in range(class_num):
for j in range(feature_len):
'''
此处把原先存数量的位置转而存概率,con_prob。
'''
con_prob[i][j][0] = con_prob[i][j][0] / class_label_num[i] #求得i类j行第一个特征的条件概率
con_prob[i][j][1] = con_prob[i][j][1] / class_label_num[i] #求得i类j行第二个特征的条件概率
return prior_prob,con_prob
#给定数据进行分类
def Predict(testset, prior_prob, con_prob, feature):#测试,先验概率,条件概率,特征
result = np.zeros(len(label))
for i in range(class_num):
for j in range(len(feature)):
if feature[j][0] == testset[0]:#第一个(0号)特征值的概率
conA = con_prob[i][j][0]
if feature[j][1] == testset[1]:#第二个(1号)特征值的概率
conB = con_prob[i][j][1]
result[i] = conA * conB * prior_prob[i]#result0是正类别的概率,result1是负的概率
result = np.vstack([result,label])#拼接
return result
def main():
X_train = [[1, 'S'], [1, 'M'], [1, 'M'], [1, 'S'], [1, 'S'],
[2, 'S'], [2, 'M'], [2, 'M'], [2, 'L'], [2, 'L'],
[3, 'L'], [3, 'M'], [3, 'M'], [3, 'L'], [3, 'L']]
Y_train = [-1, -1, 1, 1, -1, -1, -1, 1, 1, 1, 1, 1, 1, 1, -1]
#构造3×2的列表
feature = [[1, 'S'],
[2, 'M'],
[3, 'L']]
testset = [3, 'M']
prior_prob, con_prob= Train(X_train, Y_train, feature)
result = Predict(testset, prior_prob, con_prob, feature)
print('The result:',result)
main()
3. 实验过程中遇到的问题和解决过程
- 朴素贝叶斯思想的学习花费了一定时间,涉及到了概率论和数据统计的知识需要重新了解
- 在项目部署到云服务器的过程中需要导numpy包图中又遇到了一些问题,需要另外下载一些依赖。
- 指令了解不多,本次使用的华为euler系统是基于centos,命令与ubuntu有所不同,之前一直不明白get apt为什么不能用
课程总结和个人感想
-
python是一门非常有潜力的高级语言,历经多年的发展,其在编程上发挥着越来越大的作用。在这学期中,通过选修python课上的基础知识学习,我对python也有了一定的认识。而且,在字符串上的处理,python相对于c语言也是给程序员极大的便利。而python不仅如此,它的库也很多,正因为它强大的库,让编程变得不再艰难。但是,我认为python虽然在许多方面相对于c语言比较方便,但也有其相对于弱一点的方面,比如说for循环等方面。虽然一学期下来,我对python的学习也仅仅只是它的基础方面,但python的强大,也是足足地吸引着我,希望自己能够在不断地学习中,将python学习的更加好。 python是一门非常有潜力的高级语言,历经多年的发展,其在编程上发挥着越来越大的作用。在这学期中,通过选修python课上的基础知识学习,我对python也有了一定的认识。
-
在学习python的第一节课上,其对我的最初的印象就是,它更加的简洁。所有的变量都不需要提前去定义,这样给了编程者很大的自由空间与方便。。而python不仅如此,它的库也很多,正因为它强大的库,让编程变得不再艰难。我们只需要调用库中的函数,而对于函数的具体实现,也没有特殊的需求。
-
还有非常关键的一点,就是相较于java的学习,python的报错真的很少,网络上的资源利用率很高,不会像java在借鉴试运行代码后跳出一大堆感叹号,另外python的软件包真的非常好用,在此前的java学习中,尤其是在使用java的过程中经常出现jar包import不了的情况,至少在python粗浅的学习过程中还没有遇到此类情况
-
总的来说,本学期的python课程学习使我收获颇丰,不同的编程语言的学习让我有了更多的比较和对变成更多的认识,也感谢老师一学期以来耐心的授课和讲解,在今后我将不断努力不断进步。
参考资料
- 《统计学方法》李航
- bing搜索[http://www.bing.com/]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号