
理论
仅仅使用基本的线性代数知识,就可以推导出一种简单的机器学习算法,主成分分析(Principal Components Analysis, PCA)。
假设有 $m$ 个点的集合:$\left\{\boldsymbol{x}^{(1)}, \ldots, \boldsymbol{x}^{(m)}\right\}$ in $\mathbb{R}^{n}$,我们希望对这些点进行有损压缩(lossy compression)。有损压缩是指,失去一些精度作为代价,用更少的存储空间来存储这些点。我们当然希望损失的精度尽可能少。
一种方法是,我们对这些点进行编码:以低维的方式,来表示这些点。
那就是说,对于任意点:$\boldsymbol{x}^{(i)} \in \mathbb{R}^{n}$,我们会计算相应的码向量(code vector):$\boldsymbol{c}^{(i)} \in \mathbb{R}^{l}$。
如果 $l$ 小于 $m$,那么我们就是用一个低维向量来表示一个高维向量。需要的存储空间变小,当然同时可能会有精度损失。
我们希望知道某个编码函数(encoding function),根据输入,计算编码(code),即满足:
\begin{equation}
f(\boldsymbol{x})=\boldsymbol{c}
\end{equation}
并且还希望知道某个解码函数(decoding function),根据编码,计算重构的输入(reconstructed input),即满足:
\begin{equation}
\boldsymbol{x} \approx g(f(\boldsymbol{x}))
\end{equation}
PCA 就是选择特定的解码函数。具体说来,我们选择矩阵乘法,作为从编码空间到 $\mathbb{R}^{n}$ 的映射。令 $g(\boldsymbol{c})=\boldsymbol{D} \boldsymbol{c}$,其中 $\boldsymbol{D} \in \mathbb{R}^{n \times l}$ 就是解码函数的矩阵定义。
PCA 还限制了 $\boldsymbol{D}$ 的每一列互为正交(注意:除非 $l=n$,否则 $\boldsymbol{D}$ 不是严格意义上的正交矩阵)。
此外,为了不受尺度的影响,我们还限定了 $\boldsymbol{D}$ 的每一列都是单位向量。
为了把基本思想转换为可实现的算法,首先我们需要知道:如何生成每个输入点 $\boldsymbol{x}$ 的最优编码点 $C^{*}$。其中一个方法就是,最小化输入点 $\boldsymbol{x}$ 和重构点 $g\left(\boldsymbol{c}^{*}\right)$ 的距离。在主成分算法中,我们使用 $L^{2}$ 范数:
\begin{equation}
\boldsymbol{c}^{*}=\underset{\boldsymbol{c}}{\arg \min }\|\boldsymbol{x}-g(\boldsymbol{c})\|_{2}
\end{equation}
我们可以切换为计算平方的 $L^{2}$ 范数,它们优化的 $\boldsymbol{c}$ 值相同:
\begin{equation}
\boldsymbol{c}^{*}=\underset{\boldsymbol{c}}{\arg \min }\|\boldsymbol{x}-g(\boldsymbol{c})\|_{2}^{2}
\end{equation}
该函数可以化简为:
\begin{equation}
\begin{array}{l}
(\boldsymbol{x}-g(\boldsymbol{c}))^{\top}(\boldsymbol{x}-g(\boldsymbol{c})) \\
=\boldsymbol{x}^{\top} \boldsymbol{x}-\boldsymbol{x}^{\top} g(\boldsymbol{c})-g(\boldsymbol{c})^{\top} \boldsymbol{x}+g(\boldsymbol{c})^{\top} g(\boldsymbol{c}) \\
=\boldsymbol{x}^{\top} \boldsymbol{x}-2 \boldsymbol{x}^{\top} g(\boldsymbol{c})+g(\boldsymbol{c})^{\top} g(\boldsymbol{c})
\end{array}
\end{equation}
我们可以删除第一项,因为它和 $\boldsymbol{x}$ 无关,于是方程最终可以化简为:
\begin{equation}
\boldsymbol{c}^{*}=\underset{\boldsymbol{c}}{\arg \min }-2 \boldsymbol{x}^{\top} g(\boldsymbol{c})+g(\boldsymbol{c})^{\top} g(\boldsymbol{c})
\end{equation}
根据 $g(\boldsymbol{c})$ 的定义,代入可得:
\begin{equation}
\begin{aligned}
\boldsymbol{c}^{*} &=\underset{\boldsymbol{c}}{\arg \min }-2 \boldsymbol{x}^{\top} \boldsymbol{D} \boldsymbol{c}+\boldsymbol{c}^{\top} \boldsymbol{D}^{\top} \boldsymbol{D} \boldsymbol{c} \\
&=\arg \min -2 \boldsymbol{x}^{\top} \boldsymbol{D} \boldsymbol{c}+\boldsymbol{c}^{\top} \boldsymbol{I}_{l} \boldsymbol{c} \\
&=\arg \min -2 \boldsymbol{x}^{\top} \boldsymbol{D} \boldsymbol{c}+\boldsymbol{c}^{\top} \boldsymbol{c}
\end{aligned}
\end{equation}
使用向量积分,我们可以求解这个优化问题:
\begin{equation}
\begin{array}{c}
\nabla_{\boldsymbol{c}}\left(-2 \boldsymbol{x}^{\top} \boldsymbol{D} \boldsymbol{c}+\boldsymbol{c}^{\top} \boldsymbol{c}\right)=\mathbf{0} \\
-2 \boldsymbol{D}^{\top} \boldsymbol{x}+2 \boldsymbol{c}=\mathbf{0} \\
\boldsymbol{c}=\boldsymbol{D}^{\top} \boldsymbol{x}
\end{array}
\end{equation}
这使得该算法很高效,我们可以用矩阵-向量运算,来最优地对 $\boldsymbol{x}$ 进行编码。要对一个向量进行编码,我们使用编码函数:
\begin{equation}
f(\boldsymbol{x})=\boldsymbol{D}^{\top} \boldsymbol{x}
\end{equation}
我们同样可以定义 PCA 的重构运算:
\begin{equation}
r(\boldsymbol{x})=g(f(\boldsymbol{x}))=\boldsymbol{D} \boldsymbol{D}^{\top} \boldsymbol{x}
\end{equation}
下一步,我们需要选择解码矩阵 $\boldsymbol{D}$,与前面最小化一个点上的重构误差不同,由于我们需要对所有点都使用相同的矩阵 $\boldsymbol{D}$,因此我们必须针对所有点,最小化误差矩阵的 Frobenius 范数(又称 F-范数):
\begin{equation}
\boldsymbol{D}^{*}=\underset{\boldsymbol{D}}{\arg \min } \sqrt{\sum_{i, j}\left(x_{j}^{(i)}-r\left(\boldsymbol{x}^{(i)}\right)_{j}\right)^{2}} \text { subject to } \boldsymbol{D}^{\top} \boldsymbol{D}=\boldsymbol{I}_{l}
\end{equation}
为了推导计算 $\boldsymbol{D}^{*}$ 的算法,我们首先考虑 $l=1$ 的情况。此时,$\boldsymbol{D}^{*}$ 就是一个向量:$d$。将式(10)代入到式(11),可得:
\begin{equation}
\boldsymbol{d}^{*}=\underset{\boldsymbol{d}}{\arg \min } \sum_{i}\left\|\boldsymbol{x}^{(i)}-\boldsymbol{d} \boldsymbol{d}^{\top} \boldsymbol{x}^{(i)}\right\|_{2}^{2} \text { subject to }\|\boldsymbol{d}\|_{2}=1
\end{equation}
$\boldsymbol{d}^{\top} \boldsymbol{x}^{(i)}$ 是一个标量,移动到式子左边,可得:
\begin{equation}
\boldsymbol{d}^{*}=\underset{\boldsymbol{d}}{\arg \min } \sum_{i}\left\|\boldsymbol{x}^{(i)}-\boldsymbol{d}^{\top} \boldsymbol{x}^{(i)} \boldsymbol{d}\right\|_{2}^{2} \text { subject to }\|\boldsymbol{d}\|_{2}=1
\end{equation}
标量的转置等于标量本身,可得:
\begin{equation}
\boldsymbol{d}^{*}=\underset{\boldsymbol{d}}{\arg \min } \sum_{i}\left\|\boldsymbol{x}^{(i)}-\boldsymbol{x}^{(i) \top} \boldsymbol{d} \boldsymbol{d}\right\|_{2}^{2} \text { subject to }\|\boldsymbol{d}\|_{2}=1
\end{equation}
令 $\boldsymbol{X} \in \mathbb{R}^{m \times n}$,其中 $\boldsymbol{X}_{i,:}=\boldsymbol{x}^{(i)^{\top}}$,方程整理为:
\begin{equation}
\boldsymbol{d}^{*}=\underset{\boldsymbol{d}}{\arg \min }\left\|\boldsymbol{X}-\boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right\|_{F}^{2} \text { subject to } \boldsymbol{d}^{\top} \boldsymbol{d}=1
\end{equation}
先不考虑约束条件,我们可以简化 Frobenius 范数:
\begin{equation}
\begin{array}{l}
\underset{\boldsymbol{d}}{\arg \min }\left\|\boldsymbol{X}-\boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right\|_{F}^{2} \\
=\underset{\boldsymbol{d}}{\arg \min } \operatorname{Tr}\left(\left(\boldsymbol{X}-\boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right)^{\top}\left(\boldsymbol{X}-\boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right)\right) \\
=\underset{\boldsymbol{d}}{\arg \min } \operatorname{Tr}\left(\boldsymbol{X}^{\top} \boldsymbol{X}-\boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}-\boldsymbol{d} \boldsymbol{d}^{\top} \boldsymbol{X}^{\top} \boldsymbol{X}+\boldsymbol{d} \boldsymbol{d}^{\top} \boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right) \\
=\underset{\boldsymbol{d}}{\arg \min } \operatorname{Tr}\left(\boldsymbol{X}^{\top} \boldsymbol{X}\right)-\operatorname{Tr}\left(\boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right)-\operatorname{Tr}\left(\boldsymbol{d} \boldsymbol{d}^{\top} \boldsymbol{X}^{\top} \boldsymbol{X}\right)+\operatorname{Tr}\left(\boldsymbol{d} \boldsymbol{d}^{\top} \boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right) \\
=\underset{\boldsymbol{d}}{\arg \min }-\operatorname{Tr}\left(\boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right)-\operatorname{Tr}\left(\boldsymbol{d} \boldsymbol{d}^{\top} \boldsymbol{X}^{\top} \boldsymbol{X}\right)+\operatorname{Tr}\left(\boldsymbol{d} \boldsymbol{d}^{\top} \boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right) \\
=\underset{\boldsymbol{d}}{\arg \min }-2 \operatorname{Tr}\left(\boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right)+\operatorname{Tr}\left(\boldsymbol{d} \boldsymbol{d}^{\top} \boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right) \\
=\underset{\boldsymbol{d}}{\arg \min }-2 \operatorname{Tr}\left(\boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right)+\operatorname{Tr}\left(\boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top} \boldsymbol{d} \boldsymbol{d}^{\top}\right)
\end{array}
\end{equation}
现在,我们重新引入约束:
\begin{equation}
\begin{array}{l}
\underset{\boldsymbol{d}}{\arg \min }-2 \operatorname{Tr}\left(\boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right)+\operatorname{Tr}\left(\boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top} \boldsymbol{d} \boldsymbol{d}^{\top}\right) \text { subject to } \boldsymbol{d}^{\top} \boldsymbol{d}=1 \\
=\underset{\boldsymbol{d}}{\arg \min }-2 \operatorname{Tr}\left(\boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right)+\operatorname{Tr}\left(\boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right) \text { subject to } \boldsymbol{d}^{\top} \boldsymbol{d}=1 \\
=\underset{\boldsymbol{d}}{\arg \min }-\operatorname{Tr}\left(\boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right) \text { subject to } \boldsymbol{d}^{\top} \boldsymbol{d}=1 \\
=\underset{\boldsymbol{d}}{\arg \max } \operatorname{Tr}\left(\boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d} \boldsymbol{d}^{\top}\right) \text { subject to } \boldsymbol{d}^{\top} \boldsymbol{d}=1 \\
=\underset{\boldsymbol{d}}{\arg \max } \operatorname{Tr}\left(\boldsymbol{d}^{\top} \boldsymbol{X}^{\top} \boldsymbol{X} \boldsymbol{d}\right) \text { subject to } \boldsymbol{d}^{\top} \boldsymbol{d}=1
\end{array}
\end{equation}
我们可以使用特征值分解,来求解这个优化问题。具体地说,通过计算 $\boldsymbol{X}^{\top} \boldsymbol{X}$ 最大特征值的特征向量,可以求出最优值 $d$ 。
这个推导式针对 $l=1$ 的情况而言的,它只能够求出第一个主成分。在更一般的情况,如果我们想要求出主成分的基,矩阵 $\boldsymbol{D}$ 由最大特征值的 $l$ 个特征向量确定。这个可以通过归纳法证明。
实践
PCA 通过数据降维,常见的应用有加速机器学习算法和数据可视化。
数据可视化
加载 Iris 数据集
1 import pandas as pd 2 3 url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data" 4 # load dataset into Pandas DataFrame 5 df = pd.read_csv(url, names=['sepal length', 'sepal width', 'petal length', 'petal width', 'target']) 6 print(df.head())
输出:
sepal length sepal width petal length petal width target 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa
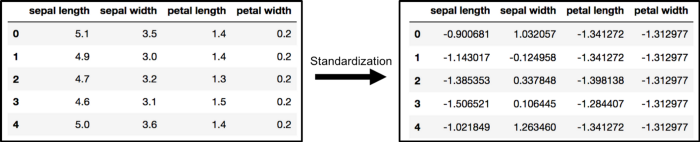
数据标准化
PCA 会受到数据尺度的影响,因此在使用 PCA 之前最好进行标准化。使用 StandardScaler 可以标准化数据集特征到一个单位尺度(均值为 0,方差为 1):这是很多机器学习算法性能优化的条件。
1 from sklearn.preprocessing import StandardScaler 2 3 features = ['sepal length', 'sepal width', 'petal length', 'petal width'] 4 # Separating out the features 5 x = df.loc[:, features].values 6 # Separating out the target 7 y = df.loc[:, ['target']].values 8 # Standardizing the features 9 x = StandardScaler().fit_transform(x)
使用 PCA 投影到 2D
下面代码将原始数据从 4 维投影到 2 维。降维后的每个主成分通常不会有特定的语义。
1 from sklearn.decomposition import PCA 2 3 pca = PCA(n_components=2) 4 principalComponents = pca.fit_transform(x) 5 principalDf = pd.DataFrame(data=principalComponents, 6 columns=['principal component 1', 'principal component 2'])

最后把特征和标签放在一起:
finalDf = pd.concat([principalDf, df[['target']]], axis=1)

2D 投影的可视化
下面代码绘制二维数据:
1 import matplotlib.pyplot as plt 2 3 fig = plt.figure(figsize=(8, 8)) 4 ax = fig.add_subplot(1, 1, 1) 5 ax.set_xlabel('Principal Component 1', fontsize=15) 6 ax.set_ylabel('Principal Component 2', fontsize=15) 7 ax.set_title('2 component PCA', fontsize=20) 8 targets = ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'] 9 colors = ['r', 'g', 'b'] 10 for target, color in zip(targets, colors): 11 indicesToKeep = finalDf['target'] == target 12 ax.scatter(finalDf.loc[indicesToKeep, 'principal component 1'] 13 , finalDf.loc[indicesToKeep, 'principal component 2'] 14 , c=color 15 , s=50) 16 ax.legend(targets) 17 ax.grid() 18 plt.show()
输出:

可解释方差
可解释方差(explained variance)可以体现出:有多少信息(方差)来自每个主成分。当你把 4 维降为 2 维时,你损失了一些信息。通过 explained_variance_ratio_,你可以看到主成分包含了多少信息。
print(pca.explained_variance_ratio_)
输出:
[0.72770452 0.23030523]
加速机器学习算法
如果你的学习算法,由于输入维度太高的原因,变得很慢,那么使用 PCA 来加速可能是一个不错的选择。
这里我们使用 MNIST 数据集。
下载并加载数据
1 from sklearn.datasets import fetch_openml 2 3 mnist = fetch_openml('mnist_784')
这里有 70000 张图像,每张图像维度是 784。
将数据划分为训练集和测试集
1 from sklearn.model_selection import train_test_split 2 3 # test_size: what proportion of original data is used for test set 4 train_img, test_img, train_lbl, test_lbl = train_test_split(mnist.data, mnist.target, test_size=1 / 7.0, random_state=0)
数据标准化
1 from sklearn.preprocessing import StandardScaler 2 3 scaler = StandardScaler() 4 # Fit on training set only. 5 scaler.fit(train_img) 6 # Apply transform to both the training set and the test set. 7 train_img = scaler.transform(train_img) 8 test_img = scaler.transform(test_img)
导入并使用 PCA
与硬编码选择多少主成分不同,下面代码选择刚好可以保留 95% 以上信息的主成分个数,因此主成分个数是可变的。
1 from sklearn.decomposition import PCA 2 3 # Make an instance of the Model 4 pca = PCA(0.95)
再训练集进行 PCA 拟合:
pca.fit(train_img)
查看有多少个主成分:
print(pca.n_components_)
输出:
327
对训练集和测试集使用 transform
train_img = pca.transform(train_img)
test_img = pca.transform(test_img)
对变换后的数据使用逻辑回归
1 import time 2 from sklearn.linear_model import LogisticRegression 3 4 # lbfgs 很快但是可能警报不能收敛 5 logisticRegr = LogisticRegression(solver='lbfgs') 6 t0 = time.time() 7 logisticRegr.fit(train_img, train_lbl) 8 print(f'time elapsed: {time.time() - t0}') 9 10 print(logisticRegr.score(test_img, test_lbl))
注:如果使用 lbfgs 报错:
AttributeError: 'str' object has no attribute 'decode'
scikit-learn 需要升级到 0.24 以上。
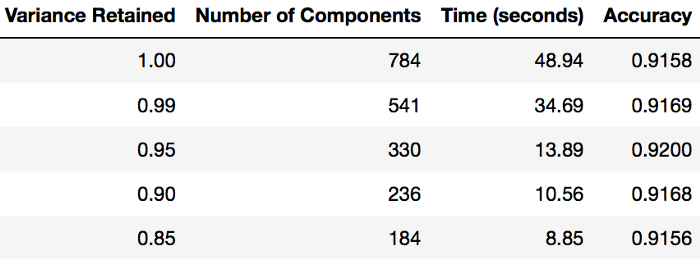
使用 PCA 后的拟合时间
以下是某一组测试性能图表,可以作为参考:
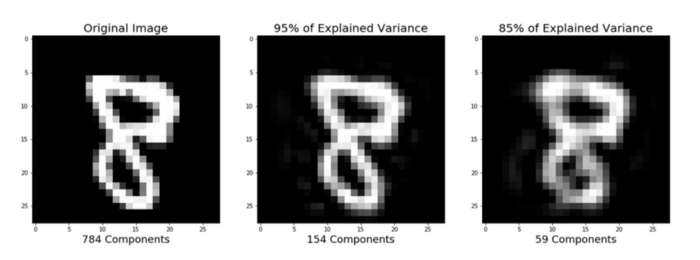
压缩表征后的图像重构
PCA 当然也可以对图像进行压缩:
如果对这段代码感兴趣,可以参考:github。
参考
- Goodfellow I, Bengio Y, Courville A, et al. Deep learning[M]. Cambridge: MIT press, 2016.
- PCA using Python (scikit-learn)
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号