贝叶斯分类器
首先在贝叶斯分类器之前先说贝叶斯理论
(1)贝叶斯分类器
假设有N种可能的分类标记,即为y={c1,c2,...,cN} λij 是将一个真实的标记cj的样本误分类为ci发损失,后验概率P(ci|x)可获得样本x分类为ci的期望,则在样本x上的“条件风险”是

我们需要最小化这个风险,也就是在每个样本上选择那个能使条件风险R(c|x)最小的类别标记,即

如果λij的取值为

则此时的条件风险为

此时的最小化分类错误率的贝叶斯分类器为:

即对每个样本x,选择能够使后验概率p(c|x)最大的类别标记。
通过上边的转化,只需求得P(c|x)的最大值即可,这是利用的是贝叶斯定理,可得以下公式
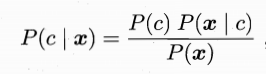
其中,p(c)表示某个记录所有类标记的概率,也就是说,随机一个记录,属于某一个类的概率,这个值可以根据大数定理来求得。
而P(x|c)表示的是样本x相对于类标记C的条件概率。
而p(x)对于每一个x的值都是一样的,因此这个问题,最终转化为求p(c)*p(x|c)最大的值。值得注意的是,p(x|c)它涉及到了关于x的所有属性的联合概率。
一直觉得先验后验概率觉得挺乱的,下面试百度的这两个概念
(2)贝叶斯的先验后验概率

(3)朴素贝叶斯分类器
通过(1)中的推到,可以得最终的问题即为求的最大值,但是这时候P(x|c)是所有属性的联合概率,在朴素贝叶斯分类器中,假设所有的属性都是互相独立的,因此最最后的问题,可以转化为,
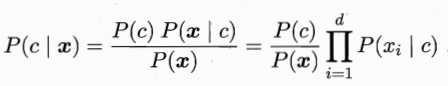
其中d表示属性的数目,xi表示在第i个属性上x的取值。
因此可以得到朴素贝叶斯分类器的表达式:

从上式可以得到,朴素贝叶斯分类器的训练过程就是基于训练集D来估计类的先验概率p(c),并为每个属性估计条件概率p(xi|c)
令DC表示训练集D中第c类样本组成的集合,若有充足的独立同分布的样本,怎容易估计出类的先验概率

对于离散的属性,Dc,xi表示Dc中的第i个属性上取值为xi的样本组成的集合,则p(xi|c)可估计为

对于连续的属性,μc,i 表示的是连续属性的均值,另一个表示的是方差

拉普拉斯平滑:若某个属性的值在训练集中与某个类没有同时出现过,用上边的方法估计是,连乘会使得到的概率为零,因此修正为一下式子:

N表示训练集D中可能的类别,Ni表示第i个属性的可能的取值数。
由于上边的方法是假设属性之间是独立的,但是这在现实生活中是很少的,大多数情况下属性之间都不是独立的。因此提出的半朴素贝叶斯分类器
(4)半朴素贝叶斯分类器
半朴素贝叶斯分类器就是考虑一部分属性间的相互依赖信息,从而不需要进行完全联合概率计算,又不至于彻底忽略了比较强的属性依赖关系。“独依赖估计”是一种常用的方式,独依赖就是假设每个属性在类别之外最多依赖于其他一个属性,即

pai是xi依赖的属性,称为xi的父属性。
建立属性间依赖的关系的方法:条件互信息,刻画了属性xi和xj在已知类别情况下的相关性。

此时问题转化为求下式的最大值。

其中

其中,Ni是第i个属性上可能的取值数,Dcxi是类别为c且在第i个属性值上取值为xi的样本集合,Dc,xi,xj 是类别c且在第i和第j个属性上取值分别为xi,xj的样本的集合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号