决策树
别人的决策树笔记:http://blog.csdn.net/sb19931201/article/details/52491430
决策树是一种最常见的分类模型,决策树是基于树结构来进行决策的,一个决策树的图如下所示

决策过程的最终结论对应了我们希望的判定结果。
决策树的基本学习算法如下:

构建树的终止条件:(1)分支后所有的Yn都一样,纯度为零(2)所有的Xn一样,没法再分
决策树的划分条件
①信息增益-----ID3算法
信息增益采用信息熵来度量样本集合纯度的指标,如果当前样本集合D中k类向本所占的比例为pk(k=0,1,2,...,|y|),则D的信息熵定义为

Ent(D)的值越小,则D的纯度越高。然后计算条件熵
最后利用经验熵和经验条件熵的差值即为信息增益:表示得知特征X的信息而使得类Y的信息不确定减少的程度,
其中属性a对样本D进行划分所获得的“信息增益”为

选择的属性a为最大的信息增益的值,即

一般熵与条件熵的差值称为互信息,决策树学习中的信息增益等价于训练集中类与特征的互信息。
例:数据集如下:

先根据正负数据的比例求信息熵,求得的信息熵的结果如下:


然后分别求得每个属性的信息增益,信息增益的结果如下:


选择信息增益最大的值,其中纹理的信息增益最大,因此选择纹理。
②信息增益率-----C4.5算法
如果对于上图中的数据集,编号也作为一个候选划分属性,则信息增益为0.998,远大于其他属性,但是这样划分是无效的。因此引入的信息增益率,其定义如下:


其中:

例:其中上图中如果采用信息增益率来计算,触感的信息增益率计算如下:


③基尼指数---CRET算法(会在后边相信分析这个算法)
数据集的纯度可以用基尼值来度量:

属性a的基尼指数定义为:

Gini(D)反应了从数据集D中随机抽取两个样本,其类别标记不一致的概率。因此Gini(D)越小,数据集D的纯度
例:
若体温为恒温时包含哺乳动物类5个,鸟类2个,则Gini=1-((5/7)2+(2/7)2)=20/49
若非恒温爬行类3个,鸟类2个,两栖类2个则Gini=1-((3/8)2+(3/8)2+(2/8)2)=42/64
因此若按恒温和非恒温来划分,则可得Gini的增益:Gini_Gain=(7/15)*(20/49)+(8/15)*(42/64)
CART算法
CART即分类与回归树,指一棵树既可以用作分类也可以用作回归,比如利用原始数据,可以得到以下两棵树,分类树和回归树,即预测婚姻情况决策树 ,预测年龄的决策树

图1表示一棵分类树,其叶子节点的输出结果为一个实际的类别,在这个例子里是婚姻的情况(已婚或者未婚),选择叶子节点中数量占比最大的类别作为输出的类别;
图2是一棵回归树,预测用户的实际年龄,是一个具体的输出值。怎样得到这个输出值?一般情况下选择使用中值、平均值或者众数进行表示,图2使用节点年龄数据的平均值作为输出值。
原始数据:
看电视时间
|
婚姻情况 |
职业 |
年龄 |
|
|
3 |
未婚 |
学生 |
12 |
|
4 |
未婚 |
学生 |
18 |
|
2 |
已婚 |
老师 |
26 |
|
5 |
已婚 |
上班族 |
47 |
|
2.5 |
已婚 |
上班族 |
36 |
|
3.5 |
未婚 |
老师 |
29 |
|
4 |
已婚 |
学生 |
21 |
CART如何选择分裂的属性
分裂的目的是为了能够让数据变纯,使决策树输出的结果更接近真实值。那么CART是如何评价节点的纯度呢?如果是分类树,CART采用GINI值衡量节点纯度;如果是回归树,采用样本方差衡量节点纯度。节点越不纯,节点分类或者预测的效果就越差。
GINI值的计算公式:
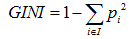
节点越不纯,GINI值越大。以二分类为例,如果节点的所有数据只有一个类别,则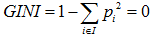 ,如果两类数量相同,则
,如果两类数量相同,则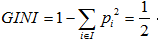 。
。
回归方差计算公式:
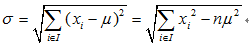
方差越大,表示该节点的数据越分散,预测的效果就越差。如果一个节点的所有数据都相同,那么方差就为0,此时可以很肯定得认为该节点的输出值;如果节点的数据相差很大,那么输出的值有很大的可能与实际值相差较大。
因此,无论是分类树还是回归树,CART都要选择使子节点的GINI值或者回归方差最小的属性作为分裂的方案。即最小化(分类树):
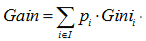
或者(回归树):

树剪枝处理剪枝是决策树学习算法对付过拟合的主要手段,主要包括预剪枝和后剪枝。
预剪枝
预剪枝是在决策树生成过程中,对每个结点在划分前进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前节点标记为叶节点。
数据集如下图所示,其中上边的部分为训练集,下边的部分为测试集,

如果不存在剪枝处理,以信息增益准则进行划分(在本博客之后的内容,都采用信息增益的方式进行划分)则最终的决策树如下图所示

首先根据信息增益选择第一个划分结点,为脐部,如果不划分,根据训练集中好瓜的数目最多,则把该类别标记为好瓜,此时验证集的精度为3/7*100%=42.9%,如果以脐部进行划分,则验证精度为5/7*100%=71.4%,因为划分后的精度比划分前要高,所以要对数据进行划分。然后从上到下依次考察结点,进行判断,
判断的准则是:如果划分前精度为Q,划分后的精度为Q1,当Q≥Q1时,不划分;Q<Q1时,划分
经过上边的过程,划分的树的最终结果为:

后剪枝
后剪枝则是从训练集生成一棵完整的决策树,然后自底向上地对非叶节点进行考察,若该节点对应的子树替换为叶节点能带来决策树泛化性能提成,则将该子树替换为叶节点。后剪枝就是先训练一棵完整的决策树,然后从下到上逐个考察各个点,假设如果该点不划分,测试集的精度为Q,如果对改点划分则测试的精度为Q1,比较Q和Q1如果,Q>Q1则去掉下边的分支点,是该分支点变成一个叶节点,然后依次向上逐个考察各个分支点。
后剪枝后的树为

解决决策树的过拟合
- 剪枝
- 前置剪枝:在分裂节点的时候设计比较苛刻的条件,如不满足则直接停止分裂(这样干决策树无法到最优,也无法得到比较好的效果)
- 后置剪枝:在树建立完之后,用单个节点代替子树,节点的分类采用子树中主要的分类(这种方法比较浪费前面的建立过程)
- 交叉验证
- 随机森林
面试中遇到的问题:
(1)使用使用信息增益率比使用信息增益的优点在哪里?
因为使用信息增益分类越多,占的优势多大,
(2)预剪枝和后剪枝使用的场景是什么。(好像每次面试都会问我预剪枝和后剪枝的区别*****)
后剪枝的计算量代价比预剪枝方法大得多,特别是在大样本集中,不过对于小样本的情况,后剪枝方法还是优于预剪枝方法的(自己理解,欢迎赐教!!)
剪枝理论 http://blog.sina.com.cn/s/blog_4e4dec6c0101fdz6.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号