spark 1.3.0下的问题
1.在spark SQL的一个test中
无论是registerAsTable还是registerTempTable 都会有问题,经过查找各种资料,采用如下的方式:
val sqlCon=new org.apache.spark.sql.SQLContext(sc)
import sqlContext._
val data=sc.textFile("hdfs://spark-master.dragon.org:8020/user/a.csv")
case class Person(cname:String,age:Int )
val people=data.map(_.split(",")).map(p=>Person(p(0),p(1).toInt))
people.toDF.registerTempTable("people")
sql("select * from people").collect
2.有一个问题待解决下边的程序中,如果我在ide里边打包,然后用spark-submit运行,会运行的很正确,如果放在ide里边直接运行,会报错,但是改成local模式怎没有问题报错内容在最下边展示着,这个问题还一直没有解决,待续
package com.san.spark.basic
import org.apache.spark.{SparkContext, SparkConf}
/**
- Created by hadoop on 3/23/16.
*/
object aaa {
def main(args: Array[String]) {
val logFile = "hdfs://spark-master:8020/user/sparkS/a.csv" // Should be some file on your system
val conf = new SparkConf().setAppName("aa") //
.setMaster("spark://spark-master:7077")
//.setJars(List("/opt/data01/myTes/aaa.jar"))
// .setMaster("local")
val sc = new SparkContext(conf)
//sc.addJar("/opt/data01/myTes/aaa.jar")
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
sc.stop()
}
}
报错提示:
/opt/data02/modules/jdk1.7.0_25/bin/java -Didea.launcher.port=7532 -Didea.launcher.bin.path=/opt/data01/idea1411/bin -Dfile.encoding=UTF-8 -classpath /opt/data02/modules/jdk1.7.0_25/jre/lib/jfr.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/rt.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/plugin.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/resources.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/jfxrt.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/deploy.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/charsets.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/jce.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/javaws.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/jsse.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/management-agent.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/ext/sunjce_provider.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/ext/zipfs.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/ext/localedata.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/ext/sunec.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/ext/dnsns.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/ext/sunpkcs11.jar:/opt/data01/myTest/out/production/myTest:/opt/data02/modules/scala-2.10.4/lib/scala-swing.jar:/opt/data02/modules/scala-2.10.4/lib/scala-reflect.jar:/opt/data02/modules/scala-2.10.4/lib/scala-library.jar:/opt/data02/modules/scala-2.10.4/lib/scala-actors-migration.jar:/opt/data02/modules/scala-2.10.4/lib/scala-actors.jar:/opt/data02/modules/spark-1.3.0-bin-2.6.0-cdh5.4.0/lib/datanucleus-api-jdo-3.2.6.jar:/opt/data02/modules/spark-1.3.0-bin-2.6.0-cdh5.4.0/lib/datanucleus-core-3.2.10.jar:/opt/data02/modules/spark-1.3.0-bin-2.6.0-cdh5.4.0/lib/datanucleus-rdbms-3.2.9.jar:/opt/data02/modules/spark-1.3.0-bin-2.6.0-cdh5.4.0/lib/spark-1.3.0-yarn-shuffle.jar:/opt/data02/modules/spark-1.3.0-bin-2.6.0-cdh5.4.0/lib/spark-assembly-1.3.0-hadoop2.6.0-cdh5.4.0.jar:/opt/data01/idea1411/lib/idea_rt.jar com.intellij.rt.execution.application.AppMain com.san.spark.basic.aaa
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
16/03/23 20:34:23 INFO SparkContext: Running Spark version 1.3.0
16/03/23 20:34:32 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/03/23 20:34:34 INFO SecurityManager: Changing view acls to: hadoop
16/03/23 20:34:34 INFO SecurityManager: Changing modify acls to: hadoop
16/03/23 20:34:34 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
16/03/23 20:34:42 INFO Slf4jLogger: Slf4jLogger started
16/03/23 20:34:43 INFO Remoting: Starting remoting
16/03/23 20:34:45 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@spark-master.dragon.org:42809]
16/03/23 20:34:45 INFO Utils: Successfully started service 'sparkDriver' on port 42809.
16/03/23 20:34:45 INFO SparkEnv: Registering MapOutputTracker
16/03/23 20:34:45 INFO SparkEnv: Registering BlockManagerMaster
16/03/23 20:34:46 INFO DiskBlockManager: Created local directory at /tmp/spark-a5f85f13-60ff-4c6b-b304-6c4875c2050c/blockmgr-f4419025-ba24-4954-ad41-bcde60f2e30f
16/03/23 20:34:46 INFO MemoryStore: MemoryStore started with capacity 243.3 MB
16/03/23 20:34:47 INFO HttpFileServer: HTTP File server directory is /tmp/spark-3fa0b690-a8b2-4325-87db-15c1194d8edf/httpd-97b84871-cd63-4a64-ba36-b7ffdc6aecf7
16/03/23 20:34:47 INFO HttpServer: Starting HTTP Server
16/03/23 20:34:48 INFO Server: jetty-8.y.z-SNAPSHOT
16/03/23 20:34:48 INFO AbstractConnector: Started SocketConnector@0.0.0.0:46460
16/03/23 20:34:48 INFO Utils: Successfully started service 'HTTP file server' on port 46460.
16/03/23 20:34:48 INFO SparkEnv: Registering OutputCommitCoordinator
16/03/23 20:34:49 INFO Server: jetty-8.y.z-SNAPSHOT
16/03/23 20:34:49 INFO AbstractConnector: Started SelectChannelConnector@0.0.0.0:4040
16/03/23 20:34:49 INFO Utils: Successfully started service 'SparkUI' on port 4040.
16/03/23 20:34:49 INFO SparkUI: Started SparkUI at http://spark-master.dragon.org:4040
16/03/23 20:34:50 INFO AppClient$ClientActor: Connecting to master akka.tcp://sparkMaster@spark-master.dragon.org:7077/user/Master...
16/03/23 20:34:53 INFO SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app-20160323203453-0006
16/03/23 20:34:53 INFO AppClient$ClientActor: Executor added: app-20160323203453-0006/0 on worker-20160323192033-spark-master.dragon.org-7078 (spark-master.dragon.org:7078) with 1 cores
16/03/23 20:34:53 INFO SparkDeploySchedulerBackend: Granted executor ID app-20160323203453-0006/0 on hostPort spark-master.dragon.org:7078 with 1 cores, 512.0 MB RAM
16/03/23 20:34:53 INFO AppClient$ClientActor: Executor updated: app-20160323203453-0006/0 is now RUNNING
16/03/23 20:34:54 INFO AppClient$ClientActor: Executor updated: app-20160323203453-0006/0 is now LOADING
16/03/23 20:34:56 INFO NettyBlockTransferService: Server created on 42339
16/03/23 20:34:56 INFO BlockManagerMaster: Trying to register BlockManager
16/03/23 20:34:56 INFO BlockManagerMasterActor: Registering block manager spark-master.dragon.org:42339 with 243.3 MB RAM, BlockManagerId(
16/03/23 20:34:56 INFO BlockManagerMaster: Registered BlockManager
16/03/23 20:35:00 INFO SparkDeploySchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
16/03/23 20:35:04 INFO MemoryStore: ensureFreeSpace(188959) called with curMem=0, maxMem=255087083
16/03/23 20:35:04 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 184.5 KB, free 243.1 MB)
16/03/23 20:35:05 INFO MemoryStore: ensureFreeSpace(26111) called with curMem=188959, maxMem=255087083
16/03/23 20:35:05 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 25.5 KB, free 243.1 MB)
16/03/23 20:35:05 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on spark-master.dragon.org:42339 (size: 25.5 KB, free: 243.2 MB)
16/03/23 20:35:05 INFO BlockManagerMaster: Updated info of block broadcast_0_piece0
16/03/23 20:35:05 INFO SparkContext: Created broadcast 0 from textFile at aaa.scala:15
16/03/23 20:35:23 INFO FileInputFormat: Total input paths to process : 1
16/03/23 20:35:25 INFO SparkContext: Starting job: count at aaa.scala:16
16/03/23 20:35:26 INFO DAGScheduler: Got job 0 (count at aaa.scala:16) with 2 output partitions (allowLocal=false)
16/03/23 20:35:26 INFO DAGScheduler: Final stage: Stage 0(count at aaa.scala:16)
16/03/23 20:35:26 INFO DAGScheduler: Parents of final stage: List()
16/03/23 20:35:27 INFO DAGScheduler: Missing parents: List()
16/03/23 20:35:27 INFO DAGScheduler: Submitting Stage 0 (MapPartitionsRDD[2] at filter at aaa.scala:16), which has no missing parents
16/03/23 20:35:28 INFO MemoryStore: ensureFreeSpace(2856) called with curMem=215070, maxMem=255087083
16/03/23 20:35:28 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 2.8 KB, free 243.1 MB)
16/03/23 20:35:29 INFO MemoryStore: ensureFreeSpace(2068) called with curMem=217926, maxMem=255087083
16/03/23 20:35:29 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.0 KB, free 243.1 MB)
16/03/23 20:35:29 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on spark-master.dragon.org:42339 (size: 2.0 KB, free: 243.2 MB)
16/03/23 20:35:29 INFO BlockManagerMaster: Updated info of block broadcast_1_piece0
16/03/23 20:35:29 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:839
16/03/23 20:35:29 INFO DAGScheduler: Submitting 2 missing tasks from Stage 0 (MapPartitionsRDD[2] at filter at aaa.scala:16)
16/03/23 20:35:29 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
16/03/23 20:35:44 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
16/03/23 20:35:53 INFO SparkDeploySchedulerBackend: Registered executor: Actor[akka.tcp://sparkExecutor@spark-master.dragon.org:52843/user/Executor#-985631278] with ID 0
16/03/23 20:35:54 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, spark-master.dragon.org, NODE_LOCAL, 1317 bytes)
16/03/23 20:35:57 INFO BlockManagerMasterActor: Registering block manager spark-master.dragon.org:40898 with 267.3 MB RAM, BlockManagerId(0, spark-master.dragon.org, 40898)
16/03/23 20:36:06 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on spark-master.dragon.org:40898 (size: 2.0 KB, free: 267.3 MB)
16/03/23 20:36:09 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, spark-master.dragon.org, NODE_LOCAL, 1317 bytes)
16/03/23 20:36:09 WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, spark-master.dragon.org): java.lang.ClassNotFoundException: com.san.spark.basic.aaa$$anonfun$1
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:270)
at org.apache.spark.serializer.JavaDeserializationStream$$anon$1.resolveClass(JavaSerializer.scala:65)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1610)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1515)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1769)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1348)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1989)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1913)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1796)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1348)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1989)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1913)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1796)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1348)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1989)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1913)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1796)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1348)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:370)
at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:68)
at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:94)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:57)
at org.apache.spark.scheduler.Task.run(Task.scala:64)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:203)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:724)
16/03/23 20:36:09 INFO TaskSetManager: Starting task 0.1 in stage 0.0 (TID 2, spark-master.dragon.org, NODE_LOCAL, 1317 bytes)
16/03/23 20:36:10 INFO TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1) on executor spark-master.dragon.org: java.lang.ClassNotFoundException (com.san.spark.basic.aaa$$anonfun$1) [duplicate 1]
16/03/23 20:36:10 INFO TaskSetManager: Starting task 1.1 in stage 0.0 (TID 3, spark-master.dragon.org, NODE_LOCAL, 1317 bytes)
16/03/23 20:36:10 INFO TaskSetManager: Lost task 0.1 in stage 0.0 (TID 2) on executor spark-master.dragon.org: java.lang.ClassNotFoundException (com.san.spark.basic.aaa$$anonfun$1) [duplicate 2]
16/03/23 20:36:10 INFO TaskSetManager: Starting task 0.2 in stage 0.0 (TID 4, spark-master.dragon.org, NODE_LOCAL, 1317 bytes)
16/03/23 20:36:10 INFO TaskSetManager: Lost task 1.1 in stage 0.0 (TID 3) on executor spark-master.dragon.org: java.lang.ClassNotFoundException (com.san.spark.basic.aaa$$anonfun$1) [duplicate 3]
16/03/23 20:36:10 INFO TaskSetManager: Starting task 1.2 in stage 0.0 (TID 5, spark-master.dragon.org, NODE_LOCAL, 1317 bytes)
16/03/23 20:36:10 INFO TaskSetManager: Lost task 0.2 in stage 0.0 (TID 4) on executor spark-master.dragon.org: java.lang.ClassNotFoundException (com.san.spark.basic.aaa$$anonfun$1) [duplicate 4]
16/03/23 20:36:10 INFO TaskSetManager: Starting task 0.3 in stage 0.0 (TID 6, spark-master.dragon.org, NODE_LOCAL, 1317 bytes)
16/03/23 20:36:10 INFO TaskSetManager: Lost task 1.2 in stage 0.0 (TID 5) on executor spark-master.dragon.org: java.lang.ClassNotFoundException (com.san.spark.basic.aaa$$anonfun$1) [duplicate 5]
16/03/23 20:36:11 INFO TaskSetManager: Starting task 1.3 in stage 0.0 (TID 7, spark-master.dragon.org, NODE_LOCAL, 1317 bytes)
16/03/23 20:36:11 INFO TaskSetManager: Lost task 0.3 in stage 0.0 (TID 6) on executor spark-master.dragon.org: java.lang.ClassNotFoundException (com.san.spark.basic.aaa$$anonfun$1) [duplicate 6]
16/03/23 20:36:11 ERROR TaskSetManager: Task 0 in stage 0.0 failed 4 times; aborting job
16/03/23 20:36:11 INFO TaskSetManager: Lost task 1.3 in stage 0.0 (TID 7) on executor spark-master.dragon.org: java.lang.ClassNotFoundException (com.san.spark.basic.aaa$$anonfun$1) [duplicate 7]
16/03/23 20:36:11 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
16/03/23 20:36:11 INFO TaskSchedulerImpl: Cancelling stage 0
16/03/23 20:36:11 INFO DAGScheduler: Job 0 failed: count at aaa.scala:16, took 45.782447 s
Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 6, spark-master.dragon.org): java.lang.ClassNotFoundException: com.san.spark.basic.aaa$$anonfun$1
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:270)
at org.apache.spark.serializer.JavaDeserializationStream$$anon$1.resolveClass(JavaSerializer.scala:65)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1610)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1515)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1769)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1348)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1989)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1913)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1796)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1348)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1989)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1913)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1796)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1348)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1989)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1913)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1796)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1348)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:370)
at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:68)
at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:94)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:57)
at org.apache.spark.scheduler.Task.run(Task.scala:64)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:203)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:724)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1203)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1192)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1191)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1191)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:693)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:693)
at scala.Option.foreach(Option.scala:236)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:693)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1393)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1354)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48)
Process finished with exit code 1
问题3:在IDEA中运行一个scala程序的时候出现了如下错误:
/opt/data02/modules/jdk1.7.0_25/bin/java -Didea.launcher.port=7535 -Didea.launcher.bin.path=/opt/data01/idea1411/bin -Dfile.encoding=UTF-8 -classpath /opt/data02/modules/jdk1.7.0_25/jre/lib/jfr.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/rt.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/plugin.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/resources.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/jfxrt.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/deploy.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/charsets.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/jce.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/javaws.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/jsse.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/management-agent.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/ext/sunjce_provider.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/ext/zipfs.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/ext/localedata.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/ext/sunec.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/ext/dnsns.jar:/opt/data02/modules/jdk1.7.0_25/jre/lib/ext/sunpkcs11.jar:/opt/data01/myTest/out/production/myTest:/opt/data02/modules/scala-2.10.4/lib/scala-swing.jar:/opt/data02/modules/scala-2.10.4/lib/scala-reflect.jar:/opt/data02/modules/scala-2.10.4/lib/scala-library.jar:/opt/data02/modules/scala-2.10.4/lib/scala-actors-migration.jar:/opt/data02/modules/scala-2.10.4/lib/scala-actors.jar:/opt/data02/modules/spark-1.3.0-bin-2.6.0-cdh5.4.0/lib/datanucleus-api-jdo-3.2.6.jar:/opt/data02/modules/spark-1.3.0-bin-2.6.0-cdh5.4.0/lib/datanucleus-core-3.2.10.jar:/opt/data02/modules/spark-1.3.0-bin-2.6.0-cdh5.4.0/lib/datanucleus-rdbms-3.2.9.jar:/opt/data02/modules/spark-1.3.0-bin-2.6.0-cdh5.4.0/lib/spark-1.3.0-yarn-shuffle.jar:/opt/data02/modules/spark-1.3.0-bin-2.6.0-cdh5.4.0/lib/spark-assembly-1.3.0-hadoop2.6.0-cdh5.4.0.jar:/opt/data01/idea1411/lib/idea_rt.jar com.intellij.rt.execution.application.AppMain com.github.GroupByTest
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
16/03/27 02:18:09 INFO SparkContext: Running Spark version 1.3.0
Exception in thread "main" org.apache.spark.SparkException: A master URL must be set in your configuration
at org.apache.spark.SparkContext.
at com.github.GroupByTest$.main(GroupByTest.scala:18)
at com.github.GroupByTest.main(GroupByTest.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:140)
Process finished with exit code 1
我运行的程序很简单:
package com.github
import java.util.Random
import org.apache.spark.{SparkConf, SparkContext}
/**
-
Created by hadoop on 3/27/16.
*/
object GroupByTest {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("GroupBy Test")
var numMappers = if (args.length > 0) args(0).toInt else 2
var numKVPairs = if (args.length > 1) args(1).toInt else 1000
var valSize = if (args.length > 2) args(2).toInt else 1000
var numReducers = if (args.length > 3) args(3).toInt else numMappersval sc = new SparkContext(sparkConf)
val pairs1 = sc.parallelize(0 until numMappers, numMappers).flatMap { p =>
val ranGen = new Random
var arr1 = new Array(Int, Array[Byte])
for (i <- 0 until numKVPairs) {
val byteArr = new ArrayByte
ranGen.nextBytes(byteArr)
arr1(i) = (ranGen.nextInt(Int.MaxValue), byteArr)
}
arr1
}.cache()
// Enforce that everything has been calculated and in cache
pairs1.count()println(pairs1.groupByKey(numReducers).count())
sc.stop()
}
}
原因很简单,我没有设置VM Options ,因此我只需点击 run---run configurations---配置参数即可,截图如下:
![]() 即可
即可
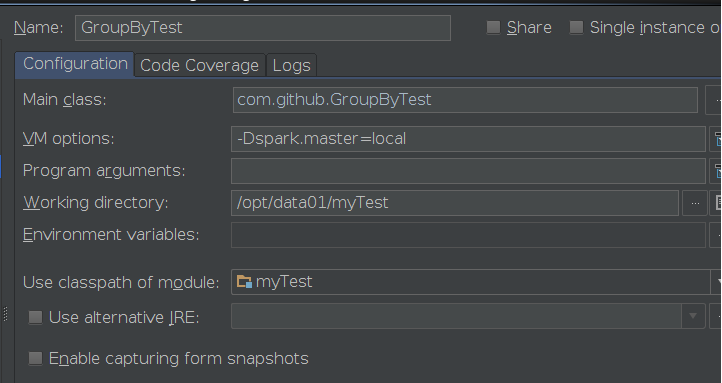 即可
即可4.在终端下运行我的第一个spark streaming的时候,提示:

原因是我的9999端口没有打开,
查看端口:netstat -an | grep 9999
打开端口:nc -lp 9999 &

 浙公网安备 33010602011771号
浙公网安备 33010602011771号