pdf无障碍化,为纯图片pdf识别文字并隐式上字(方便搜索且不影响原图片),pdf转pdf/A,转可编辑式pdf
这篇文章已过时,最新推荐: https://github.com/hiroi-sora/Umi-OCR
https://github.com/paperless-ngx/paperless-ngx/discussions/5128
需求:很多zlib下的电子书都是图片扫描版的,不是真正的、具有良好排版的原版电子书(如.mobi),对于文科查询关键字很不方便。
弊端:数学公式无法识别
1.安装ocrmypdf及其依赖
https://github.com/ocrmypdf/OCRmyPDF
https://github.com/dahuoyzs/javapdf/blob/master/OCRmyPDF使用教程.md
安装choco:https://chocolatey.org/
choco install python3
choco install --pre tesseract
choco install ghostscript
pip install ocrmypdf
pip install img2pdf
pip install pdf2image
下载poppler,解压:https://blog.alivate.com.au/poppler-windows/
原官网需要自行编译:https://poppler.freedesktop.org/
tesseract OCR自带英文OCR,否则需额外下载OCR识别数据包(如中文):https://github.com/tesseract-ocr/tessdata
之后.traineddata放入Tesseract-OCR\tessdata目录下。
2.ps中预处理图像
1)先pdf导出png
from pdf2image import convert_from_path
# 把pdf文件转换成图片列表,每一页是一个PIL Image对象
# 可以指定dpi参数来调整分辨率,越高越清晰,但是文件也越大
pages = convert_from_path("d:\\Downloads\\学术英语 (理工)_1.pdf",poppler_path = r"D:\\Program Files\\Python311\\Scripts\\poppler-0.68.0\\bin", dpi=300)
# 遍历图片列表,保存为jpg格式
# 可以用其他格式,比如png
for i, page in enumerate(pages):
# 用页码作为文件名
filename = f"page_{i+1}.png"
# 保存图片
page.save(filename, "PNG")
2)openCV2局部阈值
import cv2 as cv
import os
# 图片文件的路径
img_path = "D:/Documents/Code/Python/tmp/"
# 保存的PDF文件的路径
save_path = r"./tmp/tmp2/"
# 获取图片文件的路径列表
# img_files = [os.path.join(img_path, f) for f in os.listdir(img_path) if f.endswith(".jpg") and f.startswith("page_")]
img_files = [os.path.join(img_path, f) for f in os.listdir(img_path) if f.endswith(".png")]
print(img_files)
for i,v in enumerate(img_files):
print(i,end=' ')
image = cv.imread(v, cv.IMREAD_GRAYSCALE)
guass = cv.adaptiveThreshold(image, 255, cv.ADAPTIVE_THRESH_GAUSSIAN_C, cv.THRESH_BINARY, 55, 18)
saveFN='page_'+str(i)+'.png'
cv.imwrite(saveFN,guass)
# ret, dst = cv.threshold(image, 127, 255, cv.THRESH_BINARY)
# mean = cv.adaptiveThreshold(image, 255, cv.ADAPTIVE_THRESH_MEAN_C, cv.THRESH_BINARY, 5, 3)
# cv.imshow("image", image)
# cv.imshow("threshold", dst)
# cv.imshow("mean", mean)
# cv.imshow("guass", guass)
# cv.waitKey()
# cv.destroyAllWindows()
已弃用 2)ps中用魔棒工具抠图(同时能先去噪点),后 批量色调分离(黑白)滤镜
因为实测unpaper效果并不太好,望懂参数的大佬能留言帮助我(要手动处理1000页就不好了)
之后导出所有图层即可
3)jpg/png封装回pdf
注意:1~9要改为01~09
import img2pdf
import os
# 图片文件的路径
img_path = "D:/Documents/Code/Python"
# 保存的PDF文件的路径
save_pdf_file = "input.pdf"
# 获取图片文件的路径列表
# img_files = [os.path.join(img_path, f) for f in os.listdir(img_path) if f.endswith(".jpg") and f.startswith("page_")]
img_files = [os.path.join(img_path, f) for f in os.listdir(img_path) if f.endswith(".jpg")]
# 调用img2pdf.convert函数,把图片转换成PDF格式
pdf_bytes = img2pdf.convert(img_files)
# 打开一个PDF文件,把转换后的结果写入
with open(save_pdf_file, "wb") as f:
f.write(pdf_bytes)
4)开始转换为pdf/A
如果是目标是英语,建议就不识别chi_sim了,保证全英文,不会出现英文字符识别成中文而无法搜索。
ocrmypdf -l eng+chi_sim --deskew --clean --rotate-pages --optimize 3 input.pdf output.pdf
3.安装Adobe Acrobat Reader DC,完全免费
打开后选择启用编辑,转换原格式pdf/A为可编辑格式
现在可以愉快地在此pdf上自由做笔记了!
此文原创,花了我一天的时间,转载请著名出处!!!
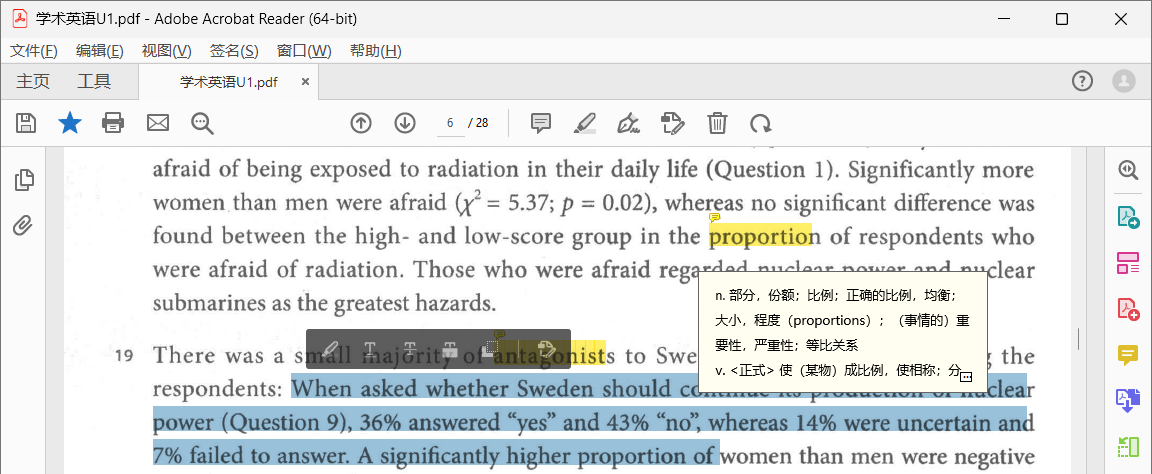
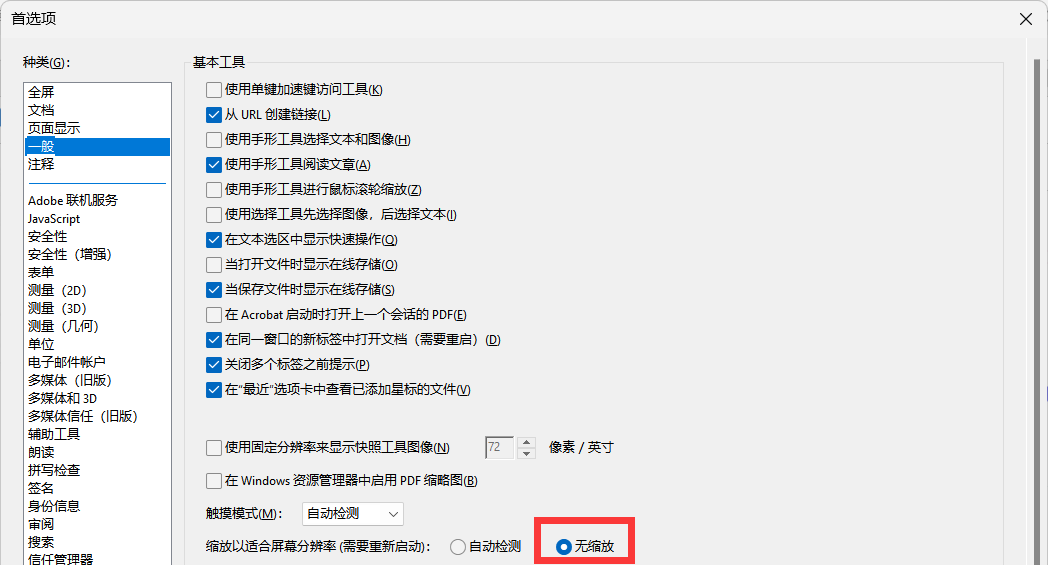
ps: 取消高dpi显示,界面太肥太大
4.中文复制有空格和换行
说是Tesseract打包pdf/A的问题,无解
安装AHKv1.1老版:https://www.autohotkey.com/
按鼠标侧键即可粘贴无空格与换行
XButton1::
Clipboard := RegExReplace(Clipboard, "\s|\n|\r")
SendInput ^v
return

 浙公网安备 33010602011771号
浙公网安备 33010602011771号