打破国外垄断,开发中国人自己的编程语言(2):使用监听器实现计算器
上一篇:实现可以解析表达式的计算器
本文已经同步到公众号「极客起源」,输入379404开始学习!
本文是《打破国外垄断,开发中国人自己的编程语言》系列文章的第2篇。本系列文章的主要目的是教大家学会如何从零开始设计一种编程语言(marvel语言),并使用marvel语言开发一些真实的项目,如移动App、Web应用等。marvel语言可以通过下面3种方式运行:
1. 解释执行
2. 编译成Java Bytecode,利用JVM执行
3. 编译成二进制文件,本地执行(基于LLVM)
本文详细讲解如何用Listener方式实现一个可以计算表达式的程序,该程序不仅可以计算表达式,也可以识别表达式的错误,如果某一个表达式出错,那么该表达式不会输出任何结果。
1. Visitor与Listener
在上一篇文章中使用Antlr和Visitor实现了一个可以计算表达式的程序MarvelCalc。这个程序非常简单,相当于Antlr的HelloWorld。不过Antlr除了Visitor方式外,还支持Listener方式,也就是监听器方式。不管是哪种方式,其目的都是遍历AST(抽象语法树),只是Visitor方式需要显式访问子节点(通过visit方法访问),例如,下面的代码访问了MulDiv的两个子节点,也就是MulDiv的左右操作数(ctx.expr(0)和ctx.expr(1))。
// expr op=('*'|'/') expr # MulDiv public Integer visitMulDiv(CalcParser.MulDivContext ctx) { int left = visit(ctx.expr(0)); // 访问MulDiv的左操作数 int right = visit(ctx.expr(1)); // 访问MulDiv的右操作数 if ( ctx.op.getType() == CalcParser.MUL ) return left * right; return left / right; } }
而Listener方式是由系统自动访问当前节点的子节点的,并不需要显式访问子节点。而且Listener可以拦截当前节点的开始处理和结束处理动作。开始处理动作的事件方法以enter开头,结束处理动作的事件方法以exit开头。例如,处理MulDiv动作时,会生成两个事件方法:enterMulDiv和exitMulDiv,分别表示开始处理MulDiv和结束处理MulDiv,这两个方法的代码如下:
@Override public void enterMulDiv(CalcParser.MulDivContext ctx) { } @Override public void exitMulDiv(CalcParser.MulDivContext ctx) { }
那么开始处理动作和结束处理动作有什么区别呢?如果是原子表达式(内部不包含其他表达式的表达式),如id、数值等,这两个事件方法没什么不同的(用哪一个处理表达式都可以)。但如果是非原子表达式,就要考虑下使用enter还是exit了。例如,下面的表达式:
3 * (20 / x * 43)
这个表达式明显是非原子的。编译器会从左向右扫描整个表达式,当扫描到第一个乘号(*)时,会将右侧的所有内容(20 / x * 43)当做一个整体处理,这就会第一次调用enterMulDiv方法和exitMulDiv方法。只不过在调用enterMulDiv方法后,还会做很多其他的工作,最后才会调用exitMulDiv方法。那么中间要做什么工作呢?当然是处理表达式(20 / x * 43)了。由于这个表达式中有一个变量x,所以在扫描到x时,需要搜索该变量是否存在,如果存在,需要提取该变量的值。也就是说,在第一次调用enterMulDiv方法时还没有处理这个变量x,如果在enterMulDiv方法中要计算整个表达式的值显然是不可能的(因为x的值还没有确定),所以正确的做法应该是在exitMulDiv方法中计算整个表达式的值,因为在该方法被调用时,整个表达式的每一个子表达式的值都已经计算完了。
enterXxx和exitXxx方法也经常被用于处理作用域,例如,在扫描到下面的函数时, 在该函数对应的enterXxx方法中会将当前作用域切换到myfun函数(通常用Stack处理),而在exitXxx方法中,会恢复myfun函数的parent作用域。类、条件语句、循环语句也同样涉及到作用域的问题。关于作用域的问题,在后面的文章中会详细介绍作用域的实现方法。
void myfun() { }
从前面的介绍可知,Listener比Visitor更灵活,Listener也是我推荐的遍历AST的方式,后面的文章也基本上使用Listener的方式实现编译器。
2. Listener对应的接口和基类
现在回到本文的主题上来,本文的目的是使用Listener的方式取代Visitor的方式实现计算器。在编译Calc.g4时,除了生成CalcVisitor.java和CalcBaseVisitor.java,还生成了另外两个文件:CalcListener.java和CalcBaseListener.java。其中CalcListener.java文件是Listener的接口文件,接口中的方法会根据Calc.g4文件中的产生式生成,该文件的代码如下:
import org.antlr.v4.runtime.tree.ParseTreeListener; public interface CalcListener extends ParseTreeListener { void enterProg(CalcParser.ProgContext ctx); void exitProg(CalcParser.ProgContext ctx); void enterPrintExpr(CalcParser.PrintExprContext ctx); void exitPrintExpr(CalcParser.PrintExprContext ctx); void enterAssign(CalcParser.AssignContext ctx); void exitAssign(CalcParser.AssignContext ctx); void enterBlank(CalcParser.BlankContext ctx); void exitBlank(CalcParser.BlankContext ctx); void enterParens(CalcParser.ParensContext ctx); void exitParens(CalcParser.ParensContext ctx); void enterMulDiv(CalcParser.MulDivContext ctx); void exitMulDiv(CalcParser.MulDivContext ctx); void enterAddSub(CalcParser.AddSubContext ctx); void exitAddSub(CalcParser.AddSubContext ctx); void enterId(CalcParser.IdContext ctx); void exitId(CalcParser.IdContext ctx); void enterInt(CalcParser.IntContext ctx); void exitInt(CalcParser.IntContext ctx); }
通常来讲,并不需要实现CalcListener接口中的所有方法,所以antlr还为我们生成了一个默认实现类CalcBaseListener,该类位于CalcBaseListener.java文件中。CalcListener接口的每一个方法都在CalcBaseListener类中提供了一个空实现,所以使用Listener方式遍历AST,只需要从CalcBaseListener类继承,并且覆盖必要的方法即可。
3. 用Listener方式实现可计算器
现在创建一个MyCalcParser.java文件,并在该文件中编写一个名为MyCalcParser的空类,代码如下:
public class MyCalcParser extends CalcBaseListener{ ... ... }
现在的问题是,在MyCalcParser类中到底要覆盖CalcBaseListener中的哪一个方法,而且如何实现这些方法呢?
要回答这个问题,就要先分析一下上一篇文章中编写的EvalVisitor类的代码了。其实在EvalVisitor中覆盖了哪一个动作对应的方法,在MyCalcParser类中也同样需要覆盖该动作对应的方法,区别只是使用enterXxx,还是使用exitXxx,或是都使用。
现在将EvalVisitor类的关键点提出来:
(1) 在EvalVisitor类中有一个名为memory的Map对象,用来保存变量的值,这在Listener中同样需要;
(2)在EvalVisitor类中有一个error变量,用来标识分析的过程中是否有错误,在Listener中同样需要;
(3)每一个visitXxx方法都有返回值,其实这个返回值是向上一层节点传递的值。而Listener中的方法并没有返回值,但仍然需要将值向上一层节点传递,所以需要想其他的方式实现向上传值;
那么为什么要向上传值呢?先来举一个例子,看下面的表达式:
4 * 5
这是一个乘法表达式,编译器对这个表达式扫描时,会先识别两个整数(4和5),这两个整数是两个原子表达式。如果使用Listener的方式,需要在这两个整数对应的enterInt方法(exitInt方法也可以)中将'4'和'5'转换为整数,这是因为不管值是什么类型,编译器读上来的都是字符串,所以需要进行类型转换。
包含4和5的表达式是MulDiv,对应的动作方法是exitMulDiv(不能用enterMulDiv,因为这时4和5还没有扫描到)。在exitMulDiv方法中要获取乘号(*)左右两个操作数的值(ctx.expr(0)和ctx.expr(1))。而这两个操作数的值在enterInt方法中已经获取了,我们要做的只是将获取的值传递给上一层表达式,也就是MulDiv表达式。向上一层传值的方法很多,这里采用一个我非常推荐的方式,通过用一个Map对象保存所有需要传递的值,key就是上一层节点的ParseTree对象(每一个enterXxx和exitXxx方法的ctx参数的类型都实现了ParseTree接口),而value则是待传递的值,可以使用下面的方式定义这个Map对象。
private Map<ParseTree,Integer> values = new HashMap<>();
同时还需要两个方法来设置和获取值,分别是setValue和getValue,代码如下:
public void setValue(ParseTree node, int value) { values.put(node,value); } public int getValue(ParseTree node) { try { return values.get(node); } catch (Exception e) { return 0; } }
下面给出MyCalcParser类的完整代码:
import org.antlr.v4.runtime.tree.ParseTree; import java.util.HashMap; import java.util.Map; public class MyCalcParser extends CalcBaseListener{ private Map<ParseTree,Integer> values = new HashMap<>(); // 用于保存向上一层节点传递的值 Map<String, Integer> memory = new HashMap<String, Integer>(); // 用于保存变量的值 boolean error = false; // 用于标识分析的过程是否出错 // 设置值 public void setValue(ParseTree node, int value) { values.put(node,value); } // 获取值 public int getValue(ParseTree node) { try { return values.get(node); } catch (Exception e) { return 0; } } @Override public void enterPrintExpr(CalcParser.PrintExprContext ctx) { // 当开始处理表达式时,默认没有错误 error = false; } @Override public void exitPrintExpr(CalcParser.PrintExprContext ctx) { if(!error) { // 只有在没有错误的情况下,才会输出表达式的值 System.out.println(getValue(ctx.expr())); } } // 必须要放在exitAssign里 @Override public void exitAssign(CalcParser.AssignContext ctx) { String id = ctx.ID().getText(); // 获取变量名 int value = getValue(ctx.expr()); // 获取右侧表达式的值 memory.put(id, value); // 保存变量 } // 必须在exitParens中完成 @Override public void exitParens(CalcParser.ParensContext ctx) { setValue(ctx,getValue(ctx.expr())); } // 计算乘法和除法(必须在exitMulDiv中完成) @Override public void exitMulDiv(CalcParser.MulDivContext ctx) { int left = getValue(ctx.expr(0)); // 获取左操作数的值 int right = getValue(ctx.expr(1)); // 获取右操作数的值 if ( ctx.op.getType() == CalcParser.MUL ) setValue(ctx,left * right); // 向上传递值 else setValue(ctx,left / right); // 向上传递值 } // 计算加法和减法(必须在exitAddSub中完成) @Override public void exitAddSub(CalcParser.AddSubContext ctx) { int left = getValue(ctx.expr(0)); // 获取左操作数的值 int right = getValue(ctx.expr(1)); // 获取右操作数的值 if ( ctx.op.getType() == CalcParser.ADD ) setValue(ctx,left + right); else setValue(ctx,left - right); } // 在enterId方法中也可以 @Override public void exitId(CalcParser.IdContext ctx) { String id = ctx.ID().getText(); if ( memory.containsKey(id) ) { setValue(ctx,memory.get(id)); // 将变量的值向上传递 } else { // 变量不存在,输出错误信息(包括行和列), System.err.println(String.format("行:%d, 列:%d, 变量<%s> 不存在!",ctx.getStart().getLine(),ctx.getStart().getCharPositionInLine() + 1, id)); error = true; } } // 处理int类型的值 @Override public void enterInt(CalcParser.IntContext ctx) { int value = Integer.valueOf(ctx.getText()); setValue(ctx, value); // 将整数值向上传递 } }
现在编写用于遍历AST和计算结果的MarvelListenerCalc类,代码如下:
import org.antlr.v4.runtime.CharStream; import org.antlr.v4.runtime.CharStreams; import org.antlr.v4.runtime.CommonTokenStream; import org.antlr.v4.runtime.tree.ParseTree; import org.antlr.v4.runtime.tree.ParseTreeWalker; import java.io.FileInputStream; import java.io.InputStream; public class MarvelListenerCalc { public static void main(String[] args) throws Exception { String inputFile = null; if ( args.length>0 ) { inputFile = args[0]; } else { System.out.println("语法格式:MarvelCalc inputfile"); return; } InputStream is = System.in; if ( inputFile!=null ) is = new FileInputStream(inputFile); CharStream input = CharStreams.fromStream(is); // 创建词法分析器 CalcLexer lexer = new CalcLexer(input); CommonTokenStream tokens = new CommonTokenStream(lexer); // CalcParser parser = new CalcParser(tokens); ParseTree tree = parser.prog(); MyCalcParser calc = new MyCalcParser(); ParseTreeWalker walker = new ParseTreeWalker(); // 开始遍历AST walker.walk(calc, tree); } }
我们仍然使用上一篇文章使用的测试用例:
1+3 * 4 - 12 /6; x = 40; y = 13; x * y + 20 - 42/6; z = 12; 4; x + 41 * z - y;
运行MarvelListenerCalc的执行结果如下图所示:
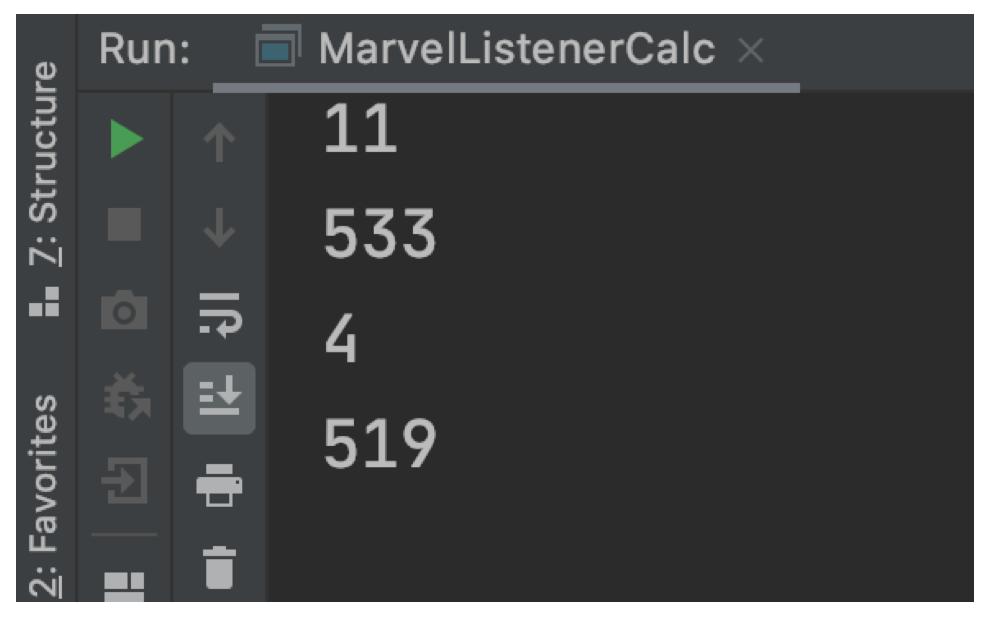
本文实现的程序还支持错误捕捉,例如,将最后一个表达式的变量x改成xx,再执行程序,就会抛出异常,出错的表达式没有输出任何值,异常会指示出错的位置(行和列),如下图所示:

请关注微信公众号「极客起源」,更多精彩内容期待您的光临!



 浙公网安备 33010602011771号
浙公网安备 33010602011771号