Python大神必须掌握的技能:多继承、super与MRO算法
本文主要以Python3.x为例讲解Python多继承、super以及MRO算法。
1. Python中的继承
任何面向对象编程语言都会支持继承,Python也不例外。但Python语言却是少数几个支持多继承的面向对象编程语言(另一个著名的支持多继承的编程语言是C++)。本文将深入阐述Python多继承中经常用到的super,并且会展示一个你所不知道的super。
相信继承的概念大家一定不会陌生。当类B从类A继承后,B类就会继承A类的所有非私有成员(由于Python没有私有成员的概念,所以B类就会继承A类的所有成员)。但有时需要在B类中直接访问A类的成员,也就是子类需要调用父类的成员,在这种情况下,有如下两种方法可以解决:
1. 在子类中直接通过父类名访问父类中的成员
2. 在子类中通过super访问父类中的成员
现在先说第一种方法。
inhert.py
class A: def __init__(self): print('Start A') print('End A') def greet(self, name): return f'hello {name}' class B(A): def __init__(self): print('Start B') # 直接通过父类名调用父类的构造方法 A.__init__(self) # 调用父类的greet方法 print(A.greet(self,'Bill')) # 调用当前类的greet方法 print(self.greet('Bill')) print('End B') # 覆盖父类的greet方法 def greet(self,name): return f'你好 {name}' B() # 创建B类的实例
这段代码的运行结果如图1所示。
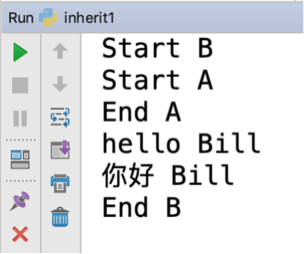
图1
在B类中,通过A. __init__(self)和A.greet(self,'Bill')调用了父类(A类)的成员。在Python2.2之前,Python类只支持这种访问父类成员的方式。尽管这种方式非常直接,但缺点是如果父类名改变,这就意味着所有使用父类名的子类都需要改变,如果某个类的子类非常多,就可能会增加非常多的代码维护工作量。所以从Python2.2开始,又增加了一种新的访问父类的方式,这就是本文主要介绍的super。当然,旧的方式也同样支持。
2.引入super
为了尽可能避免在子类中直接使用父类的名字,从Python2.2开始支持super。super并不是一个函数或方法,而是一个类。super类的构造方法需要两个参数:type和instance。其中type就是类型,例如,A、B等,instance就是B类或其子类的实例。至于为什么要传递这个实例。后面会详细介绍,总之,该实例与本文的另外一个重点MRO算法有关。
先看下面的代码:
super1.py
class A: def __init__(self): print('Start A') print('End A') def greet(self, name): return f'hello {name}' class B(A): def __init__(self): print('Start B') # 通过super调用父类的构造方法 super(B, self).__init__() # 通过super调用父类的成员方法 print(super(B, self).greet('Bill')) print(self.greet('Bill')) print('End B') def greet(self,name): return f'你好 {name}' B()
执行这段代码,会输出与图1完全相同的效果。在B类中并没有直接使用A类的名字,而是使用了super。如果A类的名字变化了,只需要修改B类的父类即可,并不需要修改B类内部的代码,这样将大大减少维护B类的工作量。
可能有的同学会问,super的第2个参数的值为什么是self呢?我们都知道,在Python中,self表示类本身的实例,那么为什么不是B()或是A()呢?首先这个实例要求必须是B或B的子类的实例,所以A()以及其他不相关类的实例自然就排除在外,那么B()为什么不行呢?其实从语义上来说,B()没问题,但问题是这样将产生无限递归的后果。也就是在B类的构造方法又调用了B的构造方法(B()表示调用B类的构造方法),而且没有终止条件。所以这么做的后果就是栈溢出。
尽管不能在B类构造方法内部直接创建B类的实例,但却可以在外部创建好B类的实例或B类子类的实例,然后通过B类构造方法将该实例传入,看下面的代码。
super2.py
class A: def __init__(self): print('Start A') print('End A') class B(A): def __init__(self,c): print('Start B') # 将外部创建的C类的实例传入super类的构造方法 super(B, c).__init__() print('End B') class C(B): def __init__(self, c): super(C,self).__init__(c) c = C(None) b = B(None) B(b) B(c)
这段代码在创建B实例之前,先创建了一个C类的实例以及一个传入None的B实例。而在B类的构造方法中多了一个参数,用于传入这个外部实例,并将这个外部实例作为super类构造方法的第2个参数传入。由于在创建C类和B类实例时传入了None,所以super类构造方法的第2个参数值也是None。这样回就会导致super(B,c)无法调用父类(A类)的构造方法,这就相当于一个空操作(什么都不会做),至于为什么会这样,后面讲MRO算法时就会一清二楚。
3. 多继承,找到亲爹好难啊
其实如果Python不支持多继承,一切都好说,一切都好理解。但问题是,Python支持多继承,这就使得继承的问题变得扑朔迷离,尤其是对初学者,更是一头雾水。对于多继承来说,一个重要的问题就是:在多个父类拥有同名成员的情况下,在子类中访问该成员,到底是调用哪一个父类的成员呢? 毫无疑问,只有一个父类会为子类提供这个成员,也就是子类的亲爹。至于其他拥有同名成员的父类,与该子类毫无关系,尽管名义上都拥有该成员。
现在用一个最简单的多继承程序来说明问题:
super3.py
class X1: def __init__(self): print('Start X1') print('End X1') class X2: def __init__(self,c): print('Start X2') print('End X2') class A(X1,X2): def __init__(self): print('Start A') super(A,self).__init__() print('End A') A()
在这段代码中,X1和X2都是A的父类,而在A类的构造方法中使用super(A,self).__init__()调用了父类的构造方法。任何Python类的构造方法可能都是同名的,都是__init__。如果A类只有一个父类,一切都好说。但如果A类有2个或2个以上的父类,那么到底调用哪一个父类的构造方法呢?
读者可以先运行这段代码,会看到输出如下的内容:
Start A
Start X1
End X1
End A
很明显,A调用了X1的构造方法。读者可以再做一个实验,将X1和X2的顺序调换一下,变成A(X2,X1),这时会输出如下的内容:
Start A
Start X2
End X2
End A
很明显,这时A调用了X2的构造方法。从观察运行结果可以找出一点规律,就是使用super(A,self),会调用A类的父类列表中第1个父类的成员(本例是X1)。那么结果真是这样吗?
下面再看一个更复杂的多继承案例:
super4.py
class X1: def __init__(self): print('Start X1') print('End X1') class X2: def __init__(self): print('Start X2') print('End X2') class A(X1,X2): def __init__(self): print('Start A') super(A,self).__init__() print('End A') class B: def __init__(self): print('Start B') print('End B') class C: def __init__(self): print('Start C') print('End C') class D: def __init__(self): print('Start D') print('End D') class MyClass1(B,A,C): def __init__(self): print('Start MyClass1') super(MyClass1,self).__init__() print('End MyClass1') class MyClass2(MyClass1,D): def __init__(self): print('Start MyClass2') super(MyClass2,self).__init__() print('End MyClass2') MyClass2()
这段代码的继承关系比较复杂,可以用图2来表示。
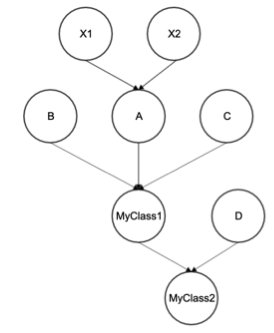
图2
运行这段代码,会输出如下内容:
Start MyClass2
Start MyClass1
Start B
End B
End MyClass1
End MyClass2
从输出结果也可以再次验证前面的推论,也就是super会调用父类列表中第一个父类的成员。如MyClass1是MyClass2的第1个父类,所以MyClass2类会调用MyClass1类的构造方法,而B类是MyClass1类的第一个父类,所以MyClass1类会调用B类的构造方法。
但这里有一个问题,如果在MyClass2类中想调用D类的构造方法,在MyClass1类中想调用A类的构造方法,该怎么办呢?当然,可以直接使用父类名进行调用,那么使用super应该如何调用。
其实Python编译器在解析类时,会将当前类的所有父类(包括直接和间接父类)按一定的规则进行排序,然后会根据super类构造方法的第一个参数的值决定使用哪一个父类。那么这个顺序是怎样的呢?
现在先不用管这个顺序,先将图2的继承关系图倒过来,变成图3的多叉树。
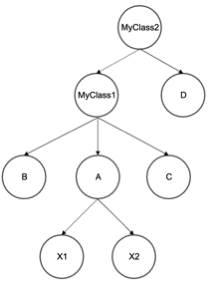
图3
现在按深度优先遍历这颗多叉树,得到的遍历结果如下:
MyClass2 > MyClass1 > B > A > X1 > X2 > C > D
假设在MyClass2中要调用B类的构造方法,那么可以使用下面的代码。
super(MyClass1, self).__init__()
假设在MyClass2中要调用X2类的构造方法,那么可以使用下面的代码。
super(X1, self).__init__()
从这个规律可以看出,选择父类的规则是super类构造方法的第1个参数值在前面深度优先遍历序列中对应类的下一个类。例如,super(X1,self)就会去寻找X1的下一个类,也就是X2。如果super类构造方法的第1个参数值正好是深度优先遍历序列的最后一个类,本例是D,那么super将不会选择MyClass2的任何父类,也就是super什么都不会做(相当于一条空语句)。到现在为止,我们好像已经清楚了前面提到的一些疑问的答案。例如,super类构造方法的第1个参数值其实是对继承树深度优先遍历列表搜索的key,而第2个参数值其实是用来得到这个列表的。但真相真的是这样吗?
4. MRO算法
好像通过多叉树的深度优先遍历就可以解决父类的顺序问题,但很多时候,类的继承关系并不是传统的树,例如下面这段代码的继承关系就是一个菱形。
super5.py
class Base: def __init__(self): print('Start Base') print('End Base') class A(Base): def __init__(self): print('Start A') super(A,self).__init__() print('End A') class B(Base): def __init__(self): print('Start B') super(B, self).__init__() print('End B') class C(A,B): def __init__(self): print('Start C') super(C, self).__init__() print('End C') C()
运行结果如下:
Start C
Start A
Start B
Start Base
End Base
End B
End A
End C
这段代码的继承关系如图4所示。
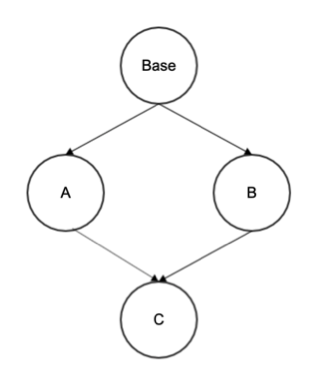
图4
你就算把图倒过来,样子仍然不会变,如图5所示。
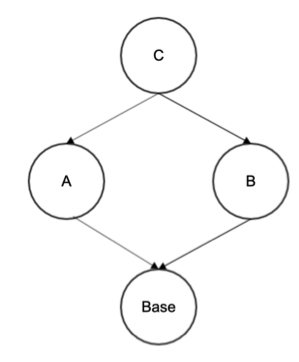
图5
这压根不是一颗多叉树,有点像一个图。对于图6所示的继承关系,是无法用深度优先遍历得到父类的顺序的,所以为了弥补深度优先遍历的缺陷,有人提出了MRO算法,MRO是Method Resolution Order三个单词的缩写。
那么什么是MRO算法呢?
MRO算法:
MRO算法是一个典型的递归操作,现在假设有如下两个函数:
1. mro:用于得到指定类的父类MRO列表。接收一个type参数,表示指定的类,如mro(C)
2. merge:用于合并多个父类列表,合并的规则如下:
如果一个父类列表的第一个元素,在其他父类列表中也是第一个元素,或不在其他父类列表中出现,则从所有待合并父类列表中删除这个元素(不存在的不需要删除),合并到当前的mro父类列表中。 现在拿前面的菱形继承关系为例说明如何得到MRO序列。这个序列的第一个元素就是C。有如下公式:
mro(C) = [C] + merge(mro(A), mro(B) ,[A,B])
其中merge函数有3个参数,分别是mro(A)、mro(B)和[A,B],也就是要将A和B的序列和[A,B]合并。根据前面的规则,有如下推导过程
mro(C) = [C] + merge(mro(A), mro(B) ,[A,B])
= [C] + merge([A,Base],[B,Base] ,[A,B])
= [C,A] + merge([Base],[B,Base],[B])
= [C,A,B] + merge([Base],[Base])
= [C,A,B,Base]
所以最终C类对应的mro序列为[C,A,B,Base],读者可以运行前面的代码,会得到如下的结果:
Start C
Start A
Start B
Start Base
End Base
End B
End A
End C
这也就是为什么会依次调用A、B和Base类构造方法的原因,因为MRO序列就是按这个顺序排列的。如果想调用B类的构造方法,需要使用super(A,self).__init()__,系统会在MRO序列中搜索A,然后会调用A的下一个类(也就是B)的构造方法。对于更复杂的继承关系,使用MRO算法自己计算MRO序列非常麻烦,所以可以使用mro方法直接输出MRO序列,代码如下:
print(C.mro())执行这行代码,会输出如下内容:
[<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class '__main__.Base'>, <class 'object'>]
下载本文完整源代码,请关注“极客起源”公众号,并输入235254获得下载地址。更多精彩技术文章,请关注“极客起源”公众号



 浙公网安备 33010602011771号
浙公网安备 33010602011771号