


《kubernetes + .net core 》dev ops部分
- 1.kubernetes 预备知识
- 2.kubernetes node 组件
- 3.集群的高可用
- 4 认证/授权
- 5.服务
- 6.配置和存储
- 7.调度
- 8.pod配置
- 9. helm
- 10.把.net core web app部署到集群并附加调试
1.kubernetes 预备知识
kubernetes是一个用go语言写的容器编排框架,常与docker搭配使用。
kubernetes是谷歌内部的容器编排框架的开源实现。可以用来方便的管理容器集群。具有很多 优点,要了解这些优点,需要先来了解一下kubernetes中的集群资源。这里指的是kubernetes里的原生的资源,kubernetes也支持自定义的资源。
1.1 集群资源
不区分名称空间
- cluster role
- namespace
- node
- persistent volume
- storage class
1.1.1 role
- 普通角色 role
- 集群角色 culster role
群集默认采用RBAC(role base access control)进行集群资源的访问控制,可以将角色作用于用户user或服务service,限制它们访问群集资源的权限范围。
其中角色又区分为 集群角色 cluster role 和普通的角色 role ,他们的区别是可以作用的范围不一致。
普通角色必有名称空间限制,只能作用于与它同名称空间的用户或服务。
集群角色没有名称空间限制,可以用于所有名称空间的用户或服务。下面的目录中会详细介绍。先在这里提一下
1.1.2 namespace
不指定时默认作用default名称空间,服务在跨名称空间访问其他服务时 域名需要加上名称空间后辍才能访问
1.1.3 node
- 主节点 master
- 工作节点 none
- 边缘节点 none
是一个包含操作系统的机器,操作系统可以是Linux也可以是windwos,可以是实体机也可以是虚拟机,其中的区别下面的其他目录会详细说明
1.1.4 persistent volume
持久卷 ,支持的类型很多,包括谷歌 亚马逊 阿里云云服务提供商的各种存储.
由于我们的项目一般是用于局域网内的,所以这里我着重介绍nfs(network file system)
1.1.5 storage class
存储类,用于根据pvc 自动创建/自动挂载/自动回收 对应的nfs目录前
1.2 工作量资源 (消耗cpu ram)
- pod
- job
- cron job
- replica set
- deployment
- daemon set
- statefull set
1.2.1 pod
工作量的最小单位是pod 其他的类型的工作量都是控制Pod的。
pod相当于docker 中的docker composite,可以由单个或多个容器组成,每个pod有自己的docker网络,pod里的container处于同个局域网中。
其他的控制器都有一个pod template,用于创建Pod
1.2.2 job
工作,一但应用到集群将会创建一个pod做一些工作,具体的工作内容由Pod的实现决定,工作完成后Pod自动终结。
1.2.3 cron job
定时工作任务,一但应用到集群,集群将会定时创建pod 做一些工作,工作完成后pod自动终结
1.2.4 replica set
复制集或称为副本集,一但应用到集群,会创建相n个相同的 pod,并且会维护这个pod的数量,如果有pod异常终结,replica set会创建一个新的Pod 以维护用户指定的数量
1.2.5 deplyoment
deplyoment常用来创建无状态的应用集群。
部署,deplyoment依赖于replicaset ,它支持滚动更新,滚动更新的原理是,在原有的一个replica set的基础上创建一个新版本的replica set ,
旧版本的replicaset 逐个减少 ,新版本的replicaset逐个新增, 可以设置一个参数指定滚动更新时要保持的最小可用pod数量。
1.2.6 daemon set
守护进程集 ,顾名思义,他的作用就是维护某个操作系统(node)的某个进程(pod)始终工作。当一个dameon set被应用到k8s集群,所有它指定的节点上都会创建某个pod
比如日志采集器 一个节点上有一个,用daemon set就十分应景。
1.2.7 stateful set
stateful set常用于创建有状态的服务集群,它具有以下特点
- 稳定的唯一网络标识符
- 稳定,持久的存储
- 有序,顺畅的部署和扩展
- 有序的自动滚动更新
举个例子,你有一个容器需要存数据,比如mysql容器,这时你用deplyoment就不合适,因为多个mysql实例各自应该有自己的存储,DNS名称。
这个时候就应该使用statefull set。它原理是创建无头服务(没有集群ip的服务)和有序号的Pod,并把这个无头服务的域名+有序号的主机名(pod名称),获得唯一的DNS名称
比如设置stateful set的名称为web,redplica=2,则会有序的创建两个Pod:web-0 web-1,当web-0就绪后才会创建web-1,如果是扩容时也是这样的,而收容的时候顺序而是反过来的,会从序号大的Pod开始删除多余的Pod
如果把一个名称为nginx的无头服务指向这个statufulset,则web-0的dns名称应该为 web-0.nginx
并且 stateful set会为这两个Pod创建各自的pvc,由于pod的名称是唯一的,所以故障重建Pod时,可以把新的Pod关联到原有的存储卷上
1.3 存储和配置资源 (消耗存储)
- config map
- secret map
- persistent volume claim
1.3.1 config map
ConfigMap 允许你将配置文件与镜像文件分离,以使容器化的应用程序具有可移植性。
- 如何创建
- 如何使用
创建:
# 从文件夹创建(文件夹里的文本文件将会被创建成config map
kubectl create configmap my-config --from-file=path/to/bar
# 从文件创建
kubectl create configmap my-config --from-file=key1=/path/to/bar/file1.txt --from-file=key2=/path/to/bar/file2.txt
# 从字符串创建
kubectl create configmap my-config --from-literal=key1=config1 --from-literal=key2=config2
# 从键值文本创建
kubectl create configmap my-config --from-file=path/to/bar
# 从env文件创建
kubectl create configmap my-config --from-env-file=path/to/bar.env
使用:
- 作为pod的环境变量
- 作为存储卷挂载到Pod
1.3.2 secrets
Secret 是一种包含少量敏感信息例如密码、令牌或密钥的对象。 这样的信息可能会被放在 Pod 规约中或者镜像中。 用户可以创建 Secret,同时系统也创建了一些 Secret。
1.3.3 pvc
- 由集群管理员管理
- 由storage class管理
如果由集群管理员管理,由开发人员应向集群管理员申请Pv ,集群管理员要手动的创建Pv,pvc,把pvc给开发人员,开发人员手动挂载pvc到pod
如果由storage class管理,则集群管理员只要创建一个provider, 之后provider会自动监视集群中的Pvc 和pod ,自动创建pv和挂载
2.kubernetes node 组件
kubernetes集群中,至少要有一个主节点,主节点应该有以下组件
- kubelet
- kuber-proxy
- cni网络插件
- etcd
- kube-apiserver
- coreDNS
- kube-controller-manager
- kube-schedule
普通节点的组件
-
kubelet
-
kube-proxy
-
cni网络插件
2.1 kubectl
kubernetes节点代理组件,每个node上都需要有,他不是Kubernetes创建的容器,所以在集群中查不到。
他的主要做的工作是
1.向kube api以hostname为名注册节点
2.监视pod运行参数,使Pod以参数预期的状态运行,所以Pod有异常通常都能查询Kubelet的日志来排查错误
2.2 kube-proxy
kubernetes 的服务相关的组件,每个Node上都需要有,除了无头服务,其他所有服务都由他处理流量
k8s集群在初始化的时候,会指定服务网段和pod网段,其中服务网段的ip都是虚拟Ip
他主要做的工作是:
监视集群的服务,如果服务满足某些条件,则通过ipvs 把这个服务的流量转发到各个后端Pod (cluster ip)
2.3 cni网络插件
cni: container network interface
k8s称之为窗口编排集群,他的核心思想是把不同的容器网络联合起来,使所有的pod都在一个扁平的网络里,可以互换访问
为达这个目的就需要容器网络插件,下面介绍一下主流的cni插件,并大致说明一下优劣
- flannel
- calico
- 其他
2.3.1 flannel

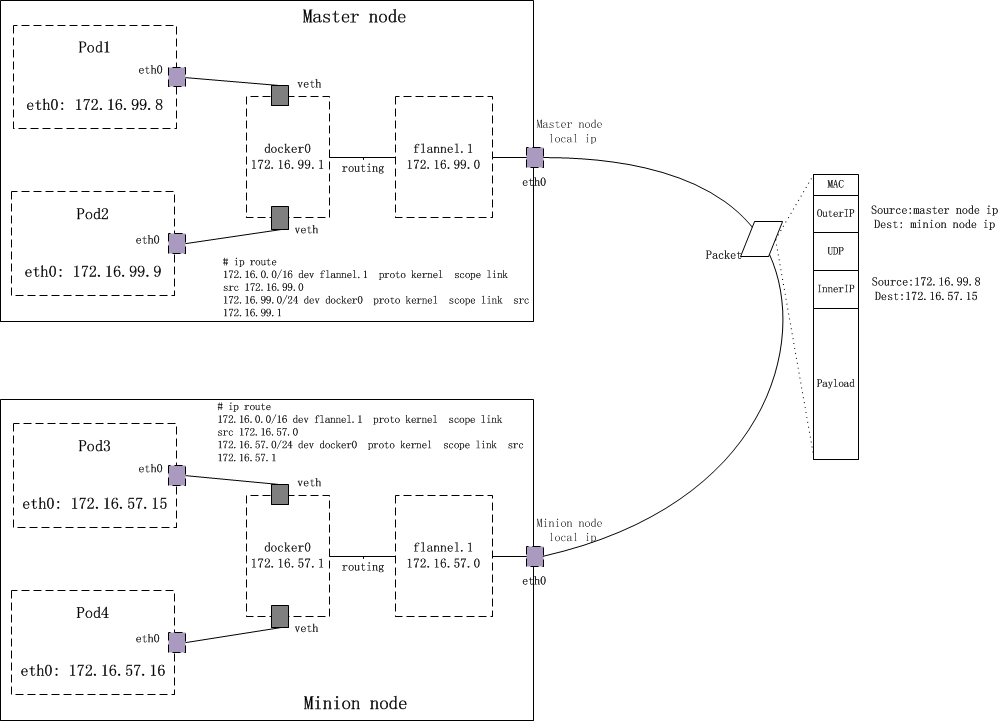
flanel是桥接模式的代表插件,
他的工作原理是用daemonset在每个节点上部署flannel插件,插件设置容器网络并把容器网络信息通过 kube api存储到etcd中 。
这样就确保不会重复注册网段了,与不同node上的Pod通过 kube-proxy打包 发给其他Node的kuber proxy,kuber proxy再拆包,发给pod
以达到跨node的扁平网络访问. 这种方式也称vxlan 或overlay
优点:
- 网络协议简单,容易分析。
- 社区规模比较大,成功案例比较多,资料比较全面,入门比较简单
缺点:
- 由于有打包 拆包, 所以通讯效率比较低下
- 不支持网络策略
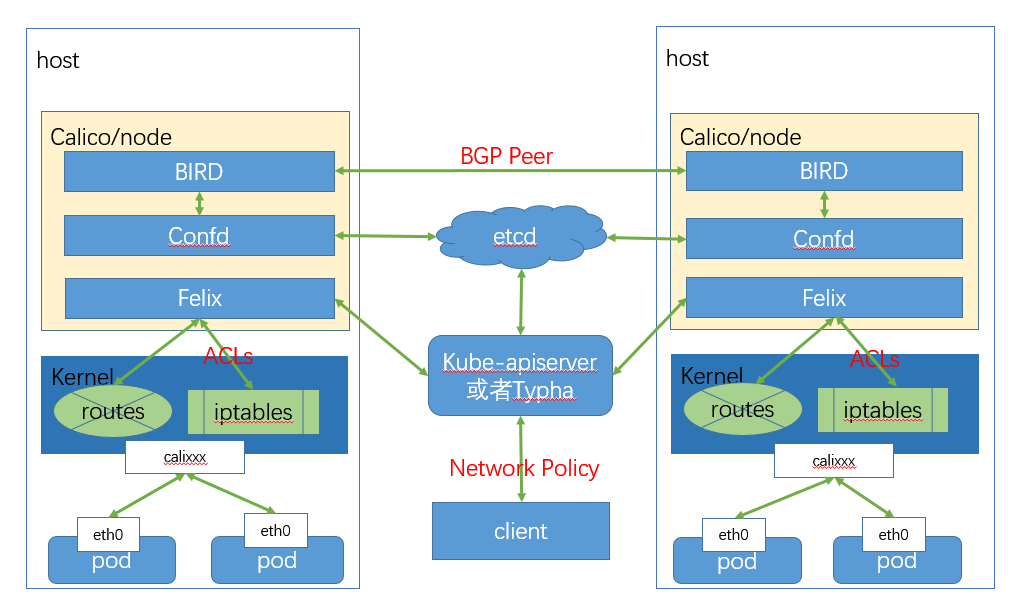
2.3.2 calico
calico 是网关模式的代表插件。 它主要由以下几部分构成
它基于边界网关协议 BGP(border gateway protocol)
他的工作原理是用daemonset在每个节点上部署calico node, 来构成扁平化容器网络
calico node由以下几个组件
- felix
- confid
- BIRD(BGP Internet route daemon)
felix 负责编写路由和访问控制列表
confid 用于把 felix生成的数据记录到etcd,用于持久化规则
BIRD 用于广播felix写到系统内核的路由规则和访问控制列表acl和calico的网络
当集群规模比较大的时候还可以可选的安装 BGP Rotue Reflector(BIRD) 和 Typha
前者用于快速广播协议,后者用于直接与ETCD通讯,减小 kubeapi的压力
优点:
- pod跨node的网络流量 直接进系统内核 走路由表,效率极高
- 支持网络策略
缺点:
- 跨node的数据包经过DNAT和SNAT后,分析网络封包会比较复杂
- 部署也比较复杂

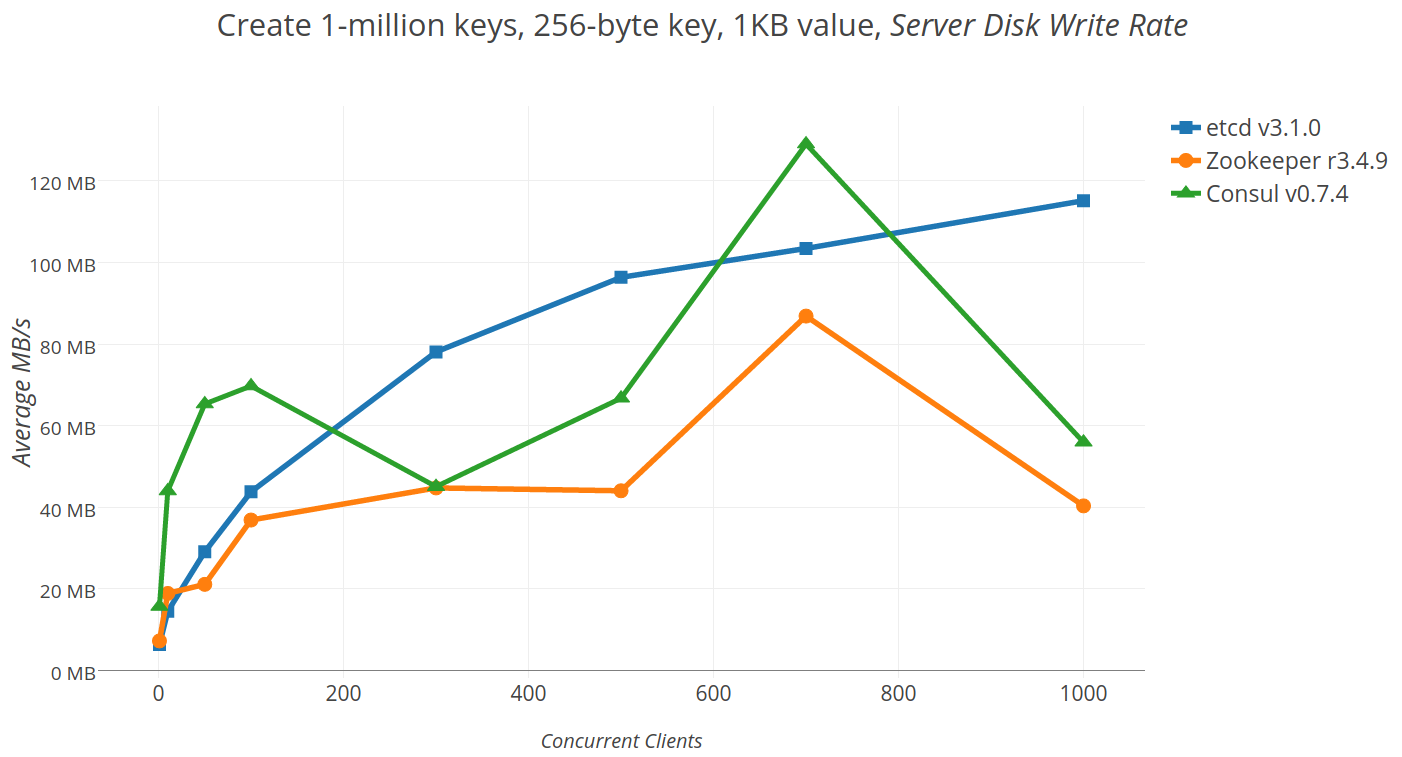
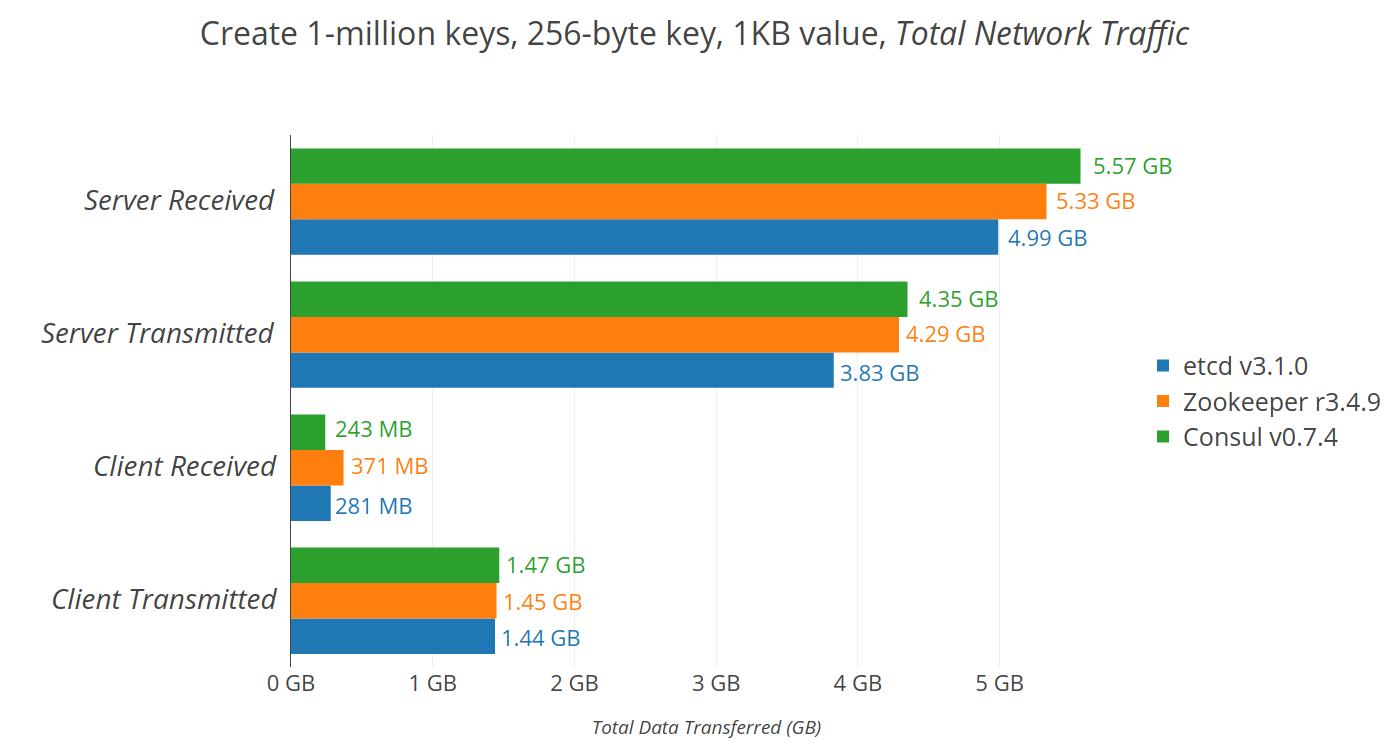
2.4 etcd
etc distributed ,一款使用go语言编写的基于raft共识算法的分布式KV缓存框架 ,
不像redis重性能,而像zookeeper 一样重数据一致性
特点是有较高的写入性能



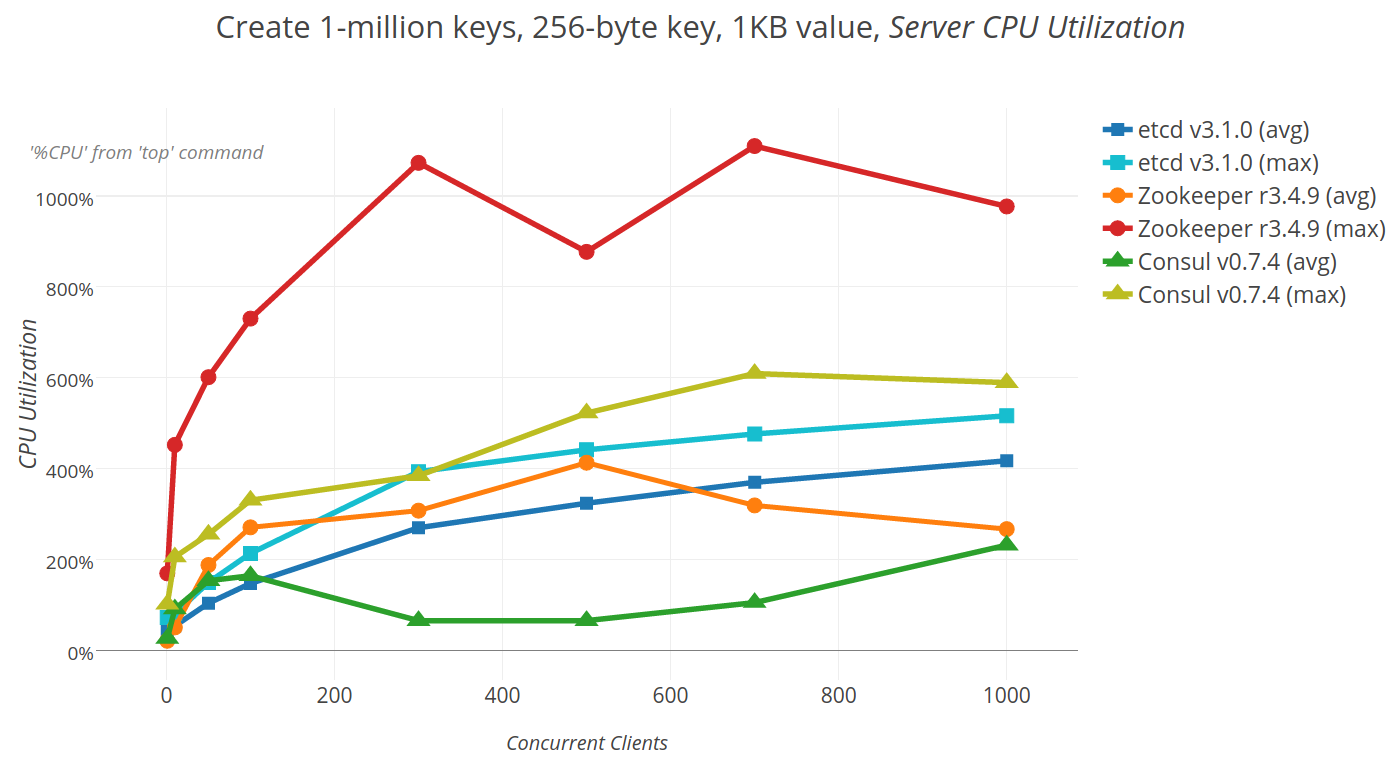

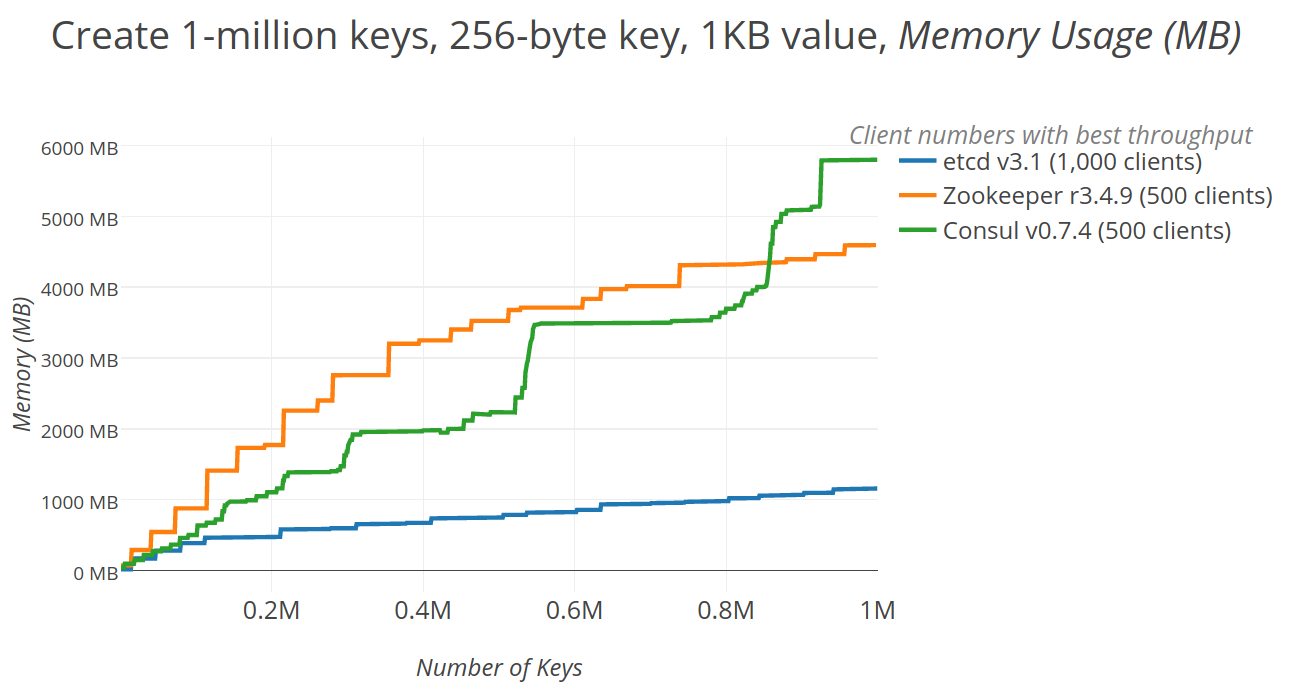

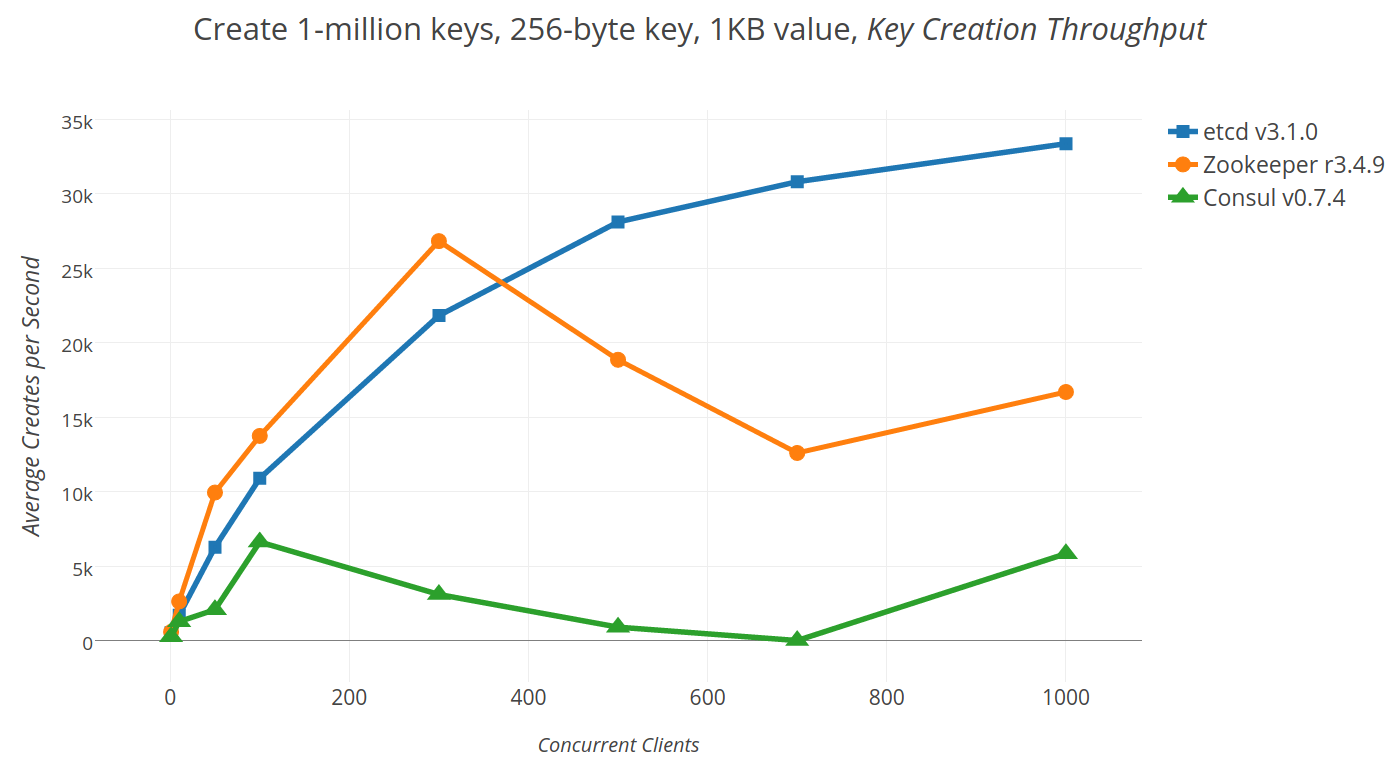

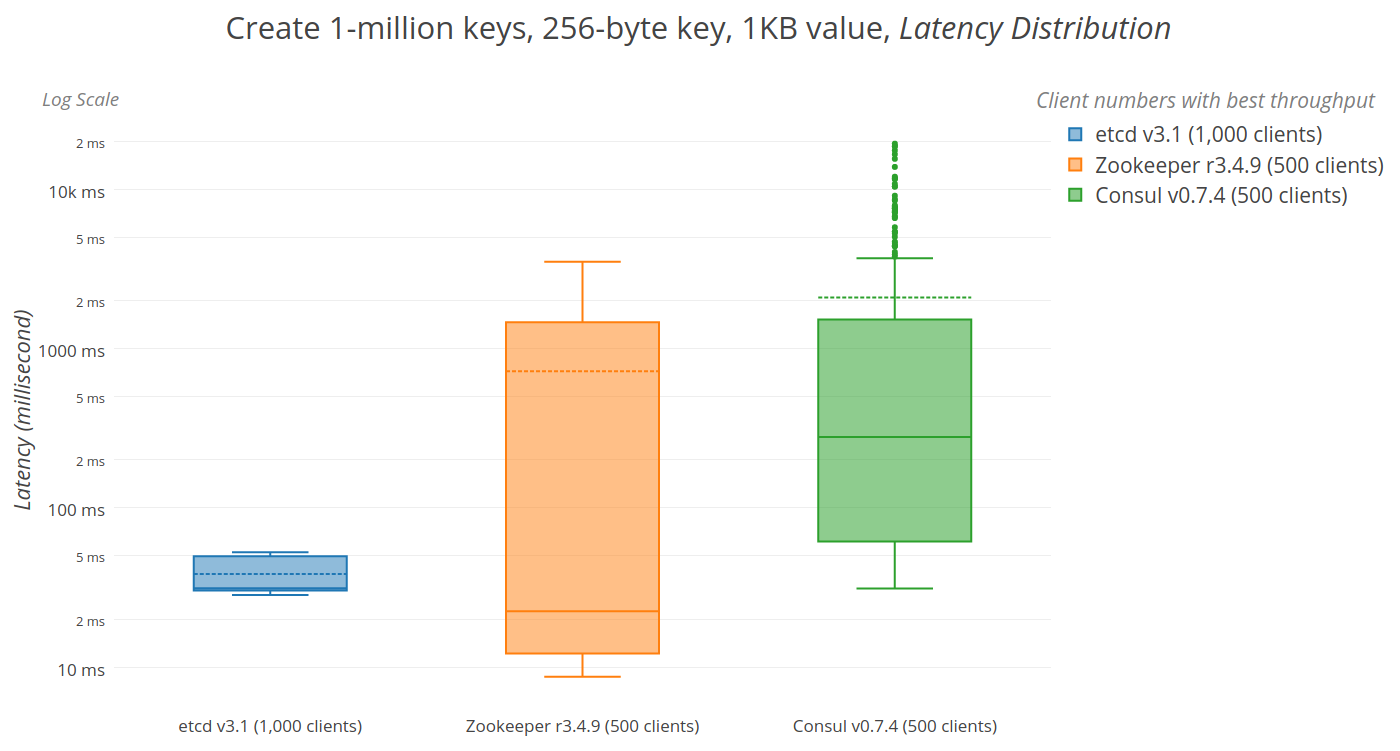
2.5 kube-apiserver
k8s 暴露给外部的web api,用于集群的交互 有各种语言的api client开源项目 ,程序员也可以在程序中引用,监视一些集群资源
2.6 coreDNS
用于集群中的service 和 pod的域名解析,
也可以配置对集群外的域名应该用哪个DNS解析
2.7 kube-controller-manager
用于 各种控制器(消耗cpu ram)的管理
2.8 kube-schedule
用于 管理控制 Pod调度相关
3.集群的高可用
- 分布式共识算法 Raft
- keepalived
- haproxy

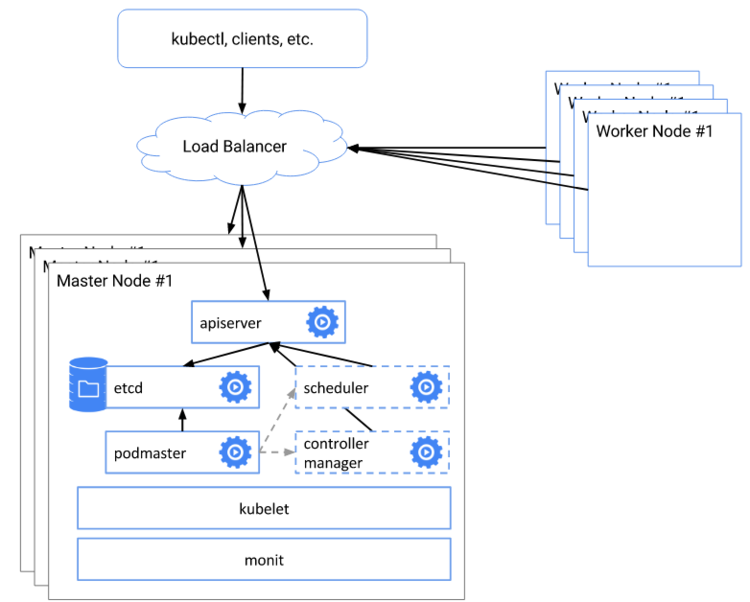
3.1 etcd的raft算法
raft是etcd的共识算法,kubernetes用etcd来存储集群的配置。config map /secret都是基于etcd。
理解raft共识算法可以知道
- 为什么高可用集群主节点是3个 5个 7个 而不是 2个 4个 6个
- kubernetes的主节点发生单点故障的时候, 存储的行为会有什么改变
3.2 keepalived
在高可用环境, keepalived用于虚拟ip的选举,一旦持有虚拟Ip的节点发生故障,其他的主节点会选择出新的主节点持有虚拟ip。并且可以配置smtp信息,当节点故障的时候发邮件通知相关的责任人
onfiguration File for keepalived
global_defs {
notification_email {
kok.bing@qq.com
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_1
}
vrrp_instance VI_1 {
state MASTER
interface eth0
lvs_sync_daemon_inteface eth0
virtual_router_id 79
advert_int 1
priority 100 #权重 m1 100 m2 90 m3 80
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.44.200/24 dev eth0
}
}
3.3 haproxy
每个主节点都部署了haproxy代理kube api端口, 所以当它持有虚拟ip的时候,会把所有对kube api的请求负载均衡到所有的主节点上。
global
chroot /var/lib/haproxy
daemon
group haproxy
user haproxy
log 127.0.0.1:514 local0 warning
pidfile /var/lib/haproxy.pid
maxconn 20000
spread-checks 3
nbproc 8
defaults
log global
mode tcp
retries 3
option redispatch
listen https-apiserver
bind *:8443
mode tcp
balance roundrobin
timeout server 900s
timeout connect 15s
server m1 192.168.44.201:6443 check port 6443 inter 5000 fall 5
server m2 192.168.44.202:6443 check port 6443 inter 5000 fall 5
server m3 192.168.44.203:6443 check port 6443 inter 5000 fall 5
4 认证/授权
4.1 authentication
kubernetes集群中的认证对象分为
- 用户
- 服务
除此之外,还有一些其他的非kubernetes集群管理的服务会需要访问集群资源的情况
但是这个暂时不实践,因为haoyun目前不会使用到这种情况
4.1.1 用户
用户不是kuebrnetes 的资源,所以单独拎出来讲。
4.1.1.1 查看用户
master node在加入集群时,会提示我们手动复制默认的管理员用户到 $HOME/.kube 文件夹
所以查看 $HOME/.kube/config文件可以知道集群 用户 认证上下文
[root@www .kube]# cat config
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZ...#略
server: https://www.haoyun.vip:8443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubernetes-admin
name: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: LS0tLS1CRUdJTiBDR...#略
client-key-data: LS0tLS1CRUdJTiBS..#.略
4.1.1.2 新增用户
创建1用户,并进入用户文件夹
[root@www .kube]# useradd hbb && cd /home/hbb
创建私钥
[root@www hbb]# openssl genrsa -out hbb_privateKey.key 2048
Generating RSA private key, 2048 bit long modulus
............................................................+++
.............................................................................................................................................................+++
e is 65537 (0x10001)
创建x.509证书签名请求 (CSR) ,CN会被识别为用户名 O会被识别为组
openssl req -new -key hbb_privateKey.key \
-out hbb.csr \
-subj "/CN=hbb/O=hbbGroup1/O=hbbGroup2"
#O可以省略也可以写多个
为CSR签入kubernetes 的证书和证书公钥,生成证书
openssl x509 -req -in hbb.csr \
-CA /etc/kubernetes/pki/ca.crt \
-CAkey /etc/kubernetes/pki/ca.key \
-CAcreateserial \
-out hbb.crt -days 50000
#证书有效天数 50000天
创建证书目录 ,存入把公钥(hbb.crt)和私钥(hbb_private.key) 放进去
[root@www hbb]# mkdir .certs
[root@www hbb]# cd .certs/
[root@www .certs]# mv ../hbb_privateKey.key ../hbb.crt .
[root@www .certs]# ll
total 8
-rw-r--r--. 1 root root 940 Sep 5 15:41 hbb.csr
-rw-r--r--. 1 root root 1679 Sep 5 15:29 hbb_privateKey.key
创建集群用户
kubectl config set-credentials hbb \
--client-certificate=/home/hbb/.certs/hbb.crt \
--client-key=/home/hbb/.certs/jean_privatekey.key
创建用户上下文
kubectl config set-context hbb-context \
--cluster=kubernetes --user=hbb
这时原有的config文件里就多了Hbb这个用户了
users:
- name: hbb
user:
client-certificate: /home/hbb/.certs/hbb.crt
client-key: /home/hbb/.certs/hbb_privatekey.key
复制 原有的.kube/config文件到hbb用户文件夹 ,在副本上删除kubernetes-admin的上下文和用户信息。
[root@www .kube]# mkdir /home/hbb/.kube
[root@www .kube]# cp config /home/hbb/.kube/
[root@www .kube]# cd /home/hbb/.kube
[root@www .kube]# vim config
[root@www .kube]# cat config
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTiBDRVJU...#略
server: https://www.haoyun.vip:8443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: hbb
name: hbb-context
current-context: hbb-context
kind: Config
preferences: {}
users:
- name: hbb
user:
client-certificate: /home/hbb/.certs/hbb.crt
client-key: /home/hbb/.certs/hbb_privateKey.key
之后把hbb用户文件夹授权给hbb用户
[root@www .kube]# chown -R hbb: /home/hbb/
#-R 递归文件夹
#hbb: 只设置了用户没有设置组
这样就创建一个用户了,此时退出root用户,使用hbb用户登上去,默认就是使用Hbb的user去访问集群
但是这时还没有给hbb授权,所以基本上什么操作都执行不了,因为没有权限
[hbb@www .certs]$ kubectl get pod -A
Error from server (Forbidden): pods is forbidden: User "hbb" cannot list resource "pods" in API group "" at the cluster scope
4.2 authorization (RBAC)
相关的kubernetes 资源
- namespace
- roles/clusterRoles
- rolebindings/clusterRolebindings
4.2.1 namespace
roles和rolebindings 如果要建立关联,他们必须是同一个名称空间内。
clusterRoles和clusterRolebindings 没有名称空间的限制,它们的规则作用于集群范围
4.2.2 roles/clusterRoles
在 RBAC API 中,一个角色包含一组相关权限的规则。权限是纯粹累加的(不存在拒绝某操作的规则)。 角色可以用 Role 来定义到某个命名空间上, 或者用 ClusterRole 来定义到整个集群作用域。
一个 Role 只可以用来对某一命名空间中的资源赋予访问权限。 下面的 Role 示例定义到名称为 "default" 的命名空间,可以用来授予对该命名空间中的 Pods 的读取权限:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default #如果是clusterRoles 则没删除这一行
name: pod-reader
rules:
- apiGroups: [""] # "" 指定 API 组
resources: ["pods","pods/log"] #子资源
verbs: ["get", "watch", "list"]
- apiGroups: [""]
resources: ["configmaps"]
resourceNames: ["my-configmap"] #具体名称的资源
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
#下面这个只有clusterRoles 才可以使用
- nonResourceURLs: ["/healthz", "/healthz/*"] # '*' 在 nonResourceURL 中的意思是后缀全局匹配。
verbs: ["get", "post"]
clusterRoles比 roles 多出以下的能力
- 集群范围资源 (比如 nodes)
- 非资源端点(比如 "/healthz")
- 跨命名空间访问的有名字空间作用域的资源(如 get pods --all-namespaces)
4.2.3 rolebindings/clusterRolebindings
rolebindings也可以使用ClusterRoles,会将里面的资源的作用域限定到rolebindings的名称空间范围内。
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-pods
namespace: default
subjects:
- kind: User #用户
name: jane
apiGroup: rbac.authorization.k8s.io
- kind: Group #用户组
name: "frontend-admins"
apiGroup: rbac.authorization.k8s.io
- kind: ServiceAccount #服务帐户
name: default
namespace: kube-system
- kind: Group # 所有myNamespace名称空间下的服务
name: system:serviceaccounts:myNamespace
apiGroup: rbac.authorization.k8s.io
- kind: Group #所有名称空间的所有服务
name: system:serviceaccounts
apiGroup: rbac.authorization.k8s.io
- kind: Group #所有认证过的用户
name: system:authenticated
apiGroup: rbac.authorization.k8s.io
- kind: Group #所有未谁的用户
name: system:authenticated
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role #可以是集群名角或普通的角色
name: pod-reader
apiGroup: rbac.authorization.k8s.io
5.服务
官方文档
服务是微服务抽象,常用于通过选择符访问一组Pod, 也可以访问其他对象,
- 集群外部的服务
- 其他名称空间的服务
上面这两种情况,服务的选择符可以省略。
5.1 代理模式
kubernetes v1.0时使用用户空间代理 (userspace)
v1.1添加了iptable代理模式,
v1.2默认使用iptables代理模式
v1.11添加ipvs 模式
当Node上不支持ipvs会回退使用iptables模式
5.1.1 userSpace模式

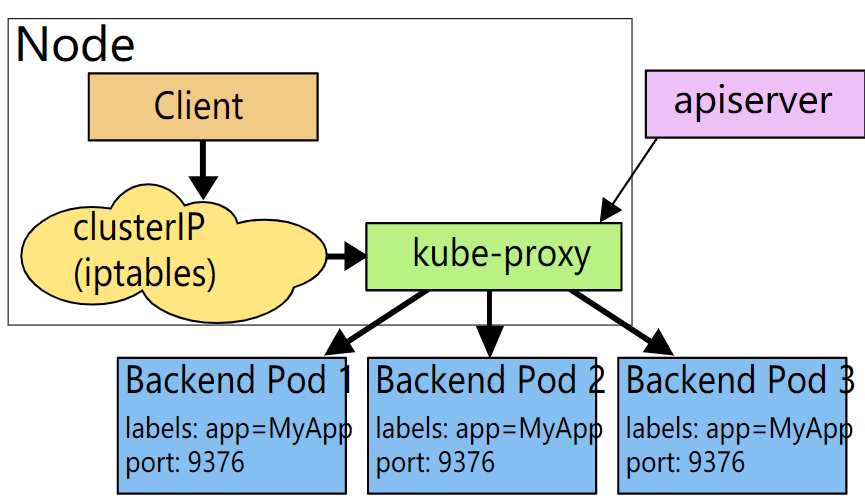
每个结点上部署kube-proxy ,它会监视主结点的apiserver对service 和 endpoints的增删改
为每个server随机开一个端口,并写入集群Ip写入iptables,把对集群服务的集群Ip的流量 转发到这个随机的端口上 ,
然后再转发到后端的Pod上, 一般是采用轮询的规则,根据服务上的sessionAnfinity来设置连接的亲和性
5.1.2 iptables模式


与userspace的区别是 不仅把service写入Iptables,同时把endpoints也写入了iptables,
所以不用在内核空间和用户空间之间来回切换,性能提升
5.1.3 ipvs

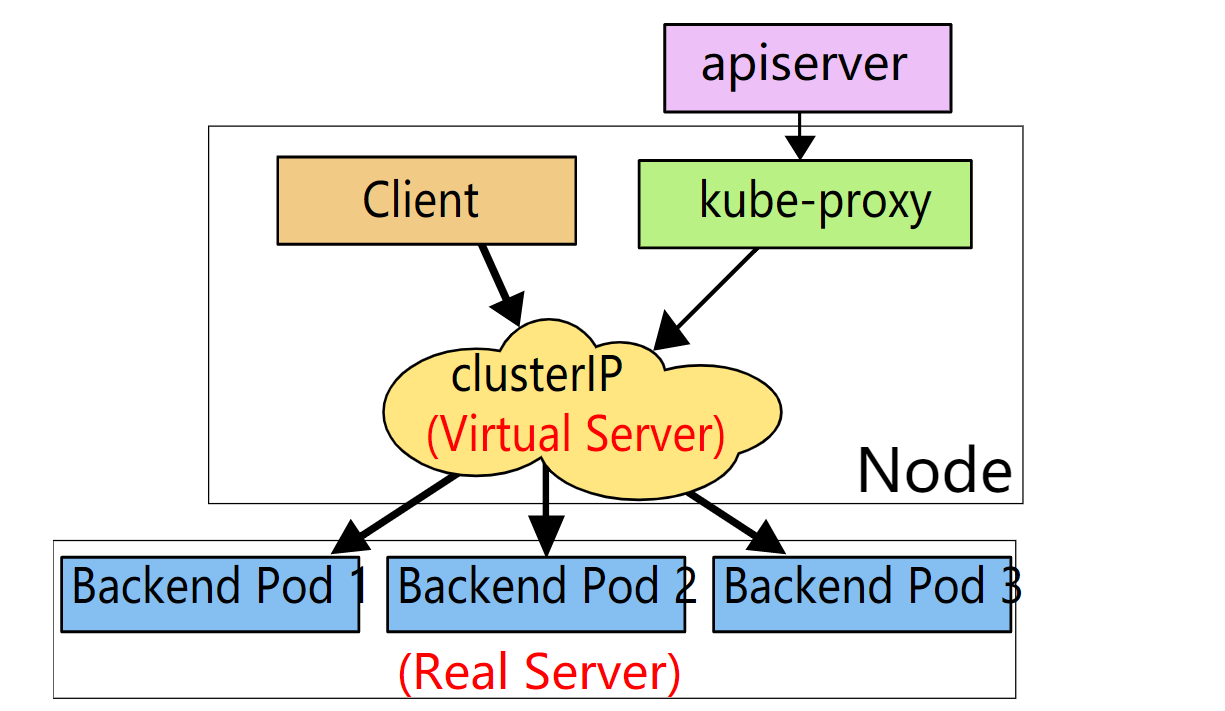
ipvs(ip virtrual server)和iptables都是基于netfilter ,但ipvs以哈希表做为基础数据结构,并工作在内核空间
相比iptables,所以他有更好的性能,也支持更多的负载均衡算法
- rr: round-robin 轮询
- lc: least connection (smallest number of open connections) 最少连接
- dh: destination hashing 目标哈希
- sh: source hashing 源哈希
- sed: shortest expected delay 最低延迟
- nq: never queue 不排队
如果需要粘性会话,可以在服务中设置
service.spec.sessionAffinity 为 clusterip ,默认是none
service.spec.sessionAffinityConfig.clientIP.timeoutSeconds 可以调整会话最长时间,默认是10800秒
5.2 服务发现
服务可以通过环境变量和DNS的方式来发现服务,推荐的做法是通过DNS
5.2.1 通过环境变量
一个名称为 "redis-master" 的 Service 暴露了 TCP 端口 6379, 同时给它分配了 Cluster IP 地址 10.0.0.11 ,
这个 Service 生成了如下环境变量:
REDIS_MASTER_SERVICE_HOST=10.0.0.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
如果需要在pod中使用这些环境变量,需要在启动pod之前先启动服务。
5.2.2 通过DNS
服务直接用服务名称为域名,
Pod会在服务之前加上ip为域名
例如在名称空间 hbb下有服务 hbb-api, 服务指向的后端pod Ip地址是10-244-6-27.,则会有dns记录
# 服务
hscadaexapi.hbb.svc.cluster.local
# pod
10-244-6-27.hscadaexapi.hbb.svc.cluster.local
dns应该尽可能使用,最好不要使用环境变量的方式
5.3 服务类型
- clusterip 集群IP
- nodeport 结点IP
- loadbalance 外部负载均衡器
- external ip 外部IP
- none 无头服务(有状态服务)
- externalname 外部服务
5.3.1 clusterip 集群IP
虚拟的ip ,通常指向一组pod (真实ip)
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377
5.3.2 nodeport 结点IP
每个主结点上的具体端口,通常把 node ip+端口 转发到 一组pod(真实ip)
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: NodePort
selector:
app: MyApp
ports:
# 默认情况下,为了方便起见,`targetPort` 被设置为与 `port` 字段相同的值。
- port: 80
targetPort: 80
# 可选字段
# 默认情况下,为了方便起见,Kubernetes 控制平面会从某个范围内分配一个端口号(默认:30000-32767)
nodePort: 30007
5.3.3 loadbalance 外部负载均衡器
通常把 外部流量 转发到 一组pod(真实ip) ,外部ip一般是在双网卡的边缘节点上
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
clusterIP: 10.0.171.239
loadBalancerIP: 78.11.24.19
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 146.148.47.155
5.3.4 external IP
将外部的流量引入服务 ,这种外部Ip 不由集群管理,由由集群管理员维护
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
externalIPs:
- 80.11.12.10
5.3.5 none 无头服务(有状态服务)
kube-proxy组件不对无头服务进行代理,无头服务 加上序号 指向 Pod,固定搭配,
所以即使 服务的pod挂了, 重启来的服务的 域名也不会换一个,用于有状态的服务。
后面讲到Pod控制器statefulset会再细讲
5.3.6 externalname 外部服务
kube-proxy组件不会对外部服务进行代理则是映射到dns 用于描述一个集群外部的服务,有解耦合的作用,
所以它和无头服务一样没有选择器,他也不由集群管理,而是由集群管理员维护
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
5.4 集群入口 ingress
由于iptables代理模块或亦 ipvs代理模式都是4层负载均衡,无法对7层协议进行负载均衡,所以对于外部的流量 ,常使用入口资源来进行负载均衡,把外部的流量均衡到服务上
- ingress contorller
- ingress 资源
5.4.1 ingress controller
ingress controller 是负载均衡器实例,一个集群中可以部署多个, 每个又可以自为一个负载均衡集群
在创建ingress资源的时候,可以用 注解Annotations:来指定要使用哪个ingress controller
kubernetes.io/ingress.class: nginx
这个nginx是controller容器启动时 用命令行的方式指定的
Args:
/nginx-ingress-controller
--default-backend-service=kube-system/my-nginx-ingress-default-backend
--election-id=ingress-controller-leader
--ingress-class=nginx
5.4.2 ingress 资源
Ingress 公开了从集群外部到集群内服务的 HTTP 和 HTTPS 路由。 流量路由由 Ingress 资源上定义的规则控制。
可以将 Ingress 配置为服务提供外部可访问的 URL、负载均衡流量、终止 SSL/TLS,以及提供基于名称的虚拟主机等能力。 Ingress 控制器 通常负责通过负载均衡器来实现 Ingress,尽管它也可以配置边缘路由器或其他前端来帮助处理流量。
Ingress 不会公开任意端口或协议。 将 HTTP 和 HTTPS 以外的服务公开到 Internet 时,通常使用 Service.Type=NodePort 或 Service.Type=LoadBalancer 类型的服务
5.4.2.1 捕获重写Path 转发
`apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: test-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- http:
paths:
- path: /testpath
pathType: Prefix
backend:
serviceName: test
servicePort: 80
5.4.2.2 基于主机域名转发
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: name-virtual-host-ingress
spec:
rules:
- host: foo.bar.com
http:
paths:
- backend:
serviceName: service1
servicePort: 80
- host: bar.foo.com
http:
paths:
- backend:
serviceName: service2
servicePort: 80
6.配置和存储
- config map
- secrets
- nfs persistent volume
- empty/hostpath
6.1 config map
ConfigMap 允许你将配置文件与镜像文件分离,以使容器化的应用程序具有可移植性。
6.1.1 创建config map
# 从文件夹创建(文件夹里的文本文件将会被创建成config map
kubectl create configmap my-config --from-file=path/to/bar
# 从文件创建
kubectl create configmap my-config --from-file=key1=/path/to/bar/file1.txt --from-file=key2=/path/to/bar/file2.txt
# 从字符串创建
kubectl create configmap my-config --from-literal=key1=config1 --from-literal=key2=config2
# 从键值文本创建
kubectl create configmap my-config --from-file=path/to/bar
# 从env文件创建
kubectl create configmap my-config --from-env-file=path/to/bar.env
6.1.2 使用config map
- 作为pod的环境变量
- 作为存储卷挂载到Pod
6.1.2.1 作为pod的环境变量
创建1个config map 配置文件,在default名称空间里
kubectl create configmap hbb-config --from-literal=key1=aaa --from-literal=key2=bbb
创建一个pod ,使用busybox镜像,并把上面的cm 加载到环境变量,在pod 的container里面加上
containers:
- name: busybox
image: busybox:1.28
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
env:
- name: HBBKEY1
valueFrom:
configMapKeyRef:
name: hbb-config
key: key1
- name: HBBKEY2
valueFrom:
configMapKeyRef:
name: hbb-config
key: key2
简易写法,加载所有hbb-config里的key value
containers:
- name: busybox
image: busybox:1.28
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
envFrom:
- configMapRef:
name: hbb-config
经测试,如果修改了config map ,Pod的环境变量是不会自动更新的,除非删除pod重新创建
6.1.2.2 作为存储卷挂载到pod
containers:
- name: busybox
image: busybox:1.28
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
volumeMounts:
- name: hbb-cm-volume
mountPath: /etc/config
volumes:
- name: hbb-cm-volume
configMap:
name: hbb-config
经验证,修改config map后,去查看挂载上去的卷,文件中的值也随之发生了改变,所以这种方式是比较好的方式。
6.2 secrets
Secret 是一种包含少量敏感信息例如密码、令牌或密钥的对象。 这样的信息可能会被放在 Pod 规约中或者镜像中。 用户可以创建 Secret,同时系统也创建了一些 Secret。
- 创建secret
- 验证 secret
- 使用 secret
6.2.1 创建secrets
- 通过文件生成
- 通过字符串生成
- 手动创建
- 通过stringData 应用时加密明文secret
- 查看验证
6.2.1.1 通过文件生成
#生成文件
echo -n 'admin' > ./username.txt
echo -n '1f2d1e2e67df' > ./password.txt
#从文件生成
kubectl create secret generic db-user-pass --from-file=./username.txt --from-file=./password.txt
默认的键名就是文件名,如果要另外指定可以--from-file=[key=]source,密码也是如此
#从文件生成
kubectl create secret generic db-user-pass --from-file=hbb-key=./username.txt --from-file=hbb-pas=./password.txt
6.2.1.2 通过字符串生成
说明:特殊字符(例如 $、*、*、= 和 !)可能会被 sell转义,所以要用''括起来
kubectl create secret generic dev-db-secret \
--from-literal=username=devuser \
--from-literal=password='S!B\*d$zDsb='
6.2.1.3 手动创建 secret
加密用户名admin和密码password
[root@www ~]# echo -n 'admin' | base64 ; echo -n 'password' |base64
YWRtaW4=
cGFzc3dvcmQ=
创建一个mysecret.yaml
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
用kubectl 创建
kubectl apply -f ./mysecret.yaml
6.2.1.4 通过stringData 应用时加密明文
创建1个 mysecret.yaml
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
stringData:
config.yaml: |-
apiUrl: "https://my.api.com/api/v1"
username: hbb
password: hbb-password
执行
kubectl apply -f ./mysecret.yaml
将会创建 一个mysecret 资源,里面有一个config.yaml的key,它的value是一个加密的字符串。
注: mysecret.yaml第7行的|- 的意思是:将下面三行字符串组合起来,替换右边的缩进(空格和换行)成一个换行符。
这种方式的好处是,可以和helm一起使用,helm使用go 的模版,可以配置明文的字符
6.2.2 查看验证secret
[root@www ~]# kubectl describe secret/dev-db-secret
Name: dev-db-secret
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 12 bytes
username: 7 bytes
使用get 和describe 查看secret都不能直接看到data里的数据。
如果要查看secret加密前的值应该用 get -o yaml 查看到base64字符串后再解码
[root@www ~]# kubectl get secret/dev-db-secret -o yaml
apiVersion: v1
data:
password: UyFCXCpkJHpEc2I9
username: ZGV2dXNlcg==
kind: Secret
...
[root@www ~]# echo UyFCXCpkJHpEc2I9|base64 --decode
S!B\*d$zDsb=
[root@www ~]# echo ZGV2dXNlcg==|base64 --decode
devuser
6.2.3 使用secret
和config map一毛一样,略
6.3 nfs persistent volume
- provisioning 供应方式
- persistent volume 持久卷
- persistent volume claim 持久卷声明
- storage class 存储类
6.3.1 provisioning 持久卷供应方案
- 静态
- 动态
6.3.1.1 静态供应
- 集群管理员创建Pv
- 集群用户 创建pvc
- 集群用户 绑定pvc到Pod
6.3.1.2 动态供应
-
集群管理员创建storage class
-
storage class监视集群中的 pvc和pod
- 集群用户创建pvc时如果挂在这个storage class上,则会自动创建pv,pv继承storage class的回收策略
- pod使用了Pvc, 则storage class会自动把pv挂载到pod的卷上
- pvc 删除时 根据storage的回收策略回收 pv
6.3.2 pv persistent volume
PersistentVolume(PV)是已经由管理员提供或者动态使用供应的集群中的一块存储的存储类。它是集群中的资源,就像节点是集群资源一样。PV是类似于Volumes的卷插件,但是其生命周期与使用PV的任何单个Pod无关。
- access mode 访问模式
- reclaim policy 回收策略
- source 存储源
- 节点亲和力
6.3.2.1 access mode 访问模式
- ReadWriteOnce-可以通过单个节点以读写方式安装该卷RWO
- ReadOnlyMany-该卷可以被许多节点只读安装ROX
- ReadWriteMany-该卷可以被许多节点读写安装RWX
6.3.2.2 reclaim policy 回收策略
如果用户删除了Pod正在使用的PVC,则不会立即删除该PVC。PVC的清除被推迟,直到任何Pod不再主动使用PVC。另外,如果管理员删除绑定到PVC的PV,则不会立即删除该PV。PV的去除被推迟,直到PV不再与PVC结合。
当用户完成其卷处理后,他们可以从允许回收资源的API中删除PVC对象。PersistentVolume的回收策略告诉集群在释放其声明之后如何处理该卷。当前,可以保留,回收或删除卷。
- retain 保留
- delete 删除
- Recycle 回收(已弃用,使用动态供应代替)
6.3.2.2.1 retain 保留
这种策略在pvc删除后,会保留pv,并释放pv,但这个pv不能被其他pvc重用。如果要回收需要集群管理员手动的去回收,回收步骤如下
- 删除pv
- 手动清理pv中的文件数据
- 如果要重用存储介质,需要重声明一个pv
6.3.2.2.2 delete 删除
默认的策略是删除,删除Pvc ,如果存储卷类型支持的话,将会同时删除pv及其中的文件数据
6.3.2.2.3 recycle 回收(弃用
如果pv的介质支持的话,此回收策略将会使用
rm -rf /volume/*
清理pv的数据,然后使这个pv可以被其他pvc使用,由于这样经常会导致意外终结的Pod,pv里的数据来不及排查就被回收,所以这种方式已被 弃用。应该使用动态配置+手动回收来避免这种情况发生。
6.3.2.3 存储源
由于我们集群环境是私有的局域网,所以通常只会使用nfs来作为存储的介质,其他的类型还有很多,这里不会介绍更多,需要有需要了解可以到k8s中文社区自行查阅资料,下面是一个由nfs provisioner创建的pv,可以从存储源看出对应的nfs服务的相关信息
Source:
Type: NFS (an NFS mount that lasts the lifetime of a pod)
Server: www.haoyun.nfs1
Path: /k8s/default-hbb-pvc-pvc-02d94a26-d5df-4e70-9e3f-a12630f2bd41
ReadOnly: false
6.3.2.4 节点亲和力
pv一旦设置了节点亲和力,则与Pv结合的Pod都会部署到命中的节点上
6.3.3 persistent volume claim
PersistentVolumeClaim(PVC)是由用户进行存储的请求。它类似于pod。pod消耗节点资源,PVC消耗PV资源。Pod可以请求特定级别的资源(CPU和内存)。声明可以请求特定的大小和访问模式
静态供应情况下,pvc绑定Pv
动态供应情况下,pvc绑定 storage class
6.3.4 storage class
虽然PersistentVolumeClaims允许用户使用抽象存储资源,但对于不同的pod,用户通常需要具有不同存储介质,例如机械硬盘和固态硬盘,机房1和机房2,集群管理员需要能够提供各种PersistentVolume,这些PersistentVolume不仅在大小和访问模式上有更多差异,而且还不让用户了解如何实现这些卷的细节。
这个是推荐使用的方式,所以这里重点实践
- nfs 服务器搭建(www.haoyun.nfs1),并验证可用性
- 基于nfs部署一个 nfs client provisioner(www.haoyun.nfs1/k8s)
- 创建1个storage class
- 创建1个绑定storage class的pvc
- 创建1个绑定pvc的pod
- 验证
6.3.4.1 nfs服务器搭建
略,
验证
1. 安装nfs-client
# yum install -y nfs-utils
2. 创建挂载目录
# mkdir /var/nfs
3. 查看NFS Server目录
# showmount -e www.haoyun.nfs1
4. 挂载NFS Server目录
# mount -t nfs www.haoyun.nfs1:/k8s ~/nfs-test
5. 测试完卸载
# umount -t nfs ~/nfs-test/
6.3.4.2 nfs client provisioner
略
6.3.4.3 创建1个storage class
用工具安装部署完nfs provisioner时已经生成,略
6.3.4.4 创建1个绑定storage class的pvc
创建文件 pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: hbb-pvc
annotations:
volume.beta.kubernetes.io/storage-class: "nfs-client"
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Mi
添加pvc到集群中的nfs名称空间,storage class是集群资源,任何名称空间都可以使用
kubectl apply -f pvc.yaml -n nfs
6.3.4.5 创建pod,验证nfs provisioner
创建podWithPvc.yaml
kind: Pod
apiVersion: v1
metadata:
name: podwithpvc
spec:
containers:
- name: podwithpvc
image: busybox:1.28
command:
- "/bin/sh"
args:
- "-c"
- "touch /mnt/SUCCESS && exit 0 || exit 1" #创建一个SUCCESS文件后退出
volumeMounts:
- name: nfs-pvc
mountPath: "/mnt"
restartPolicy: "Never"
volumes:
- name: nfs-pvc
persistentVolumeClaim:
claimName: hbb-pvc #与PVC名称保持一致
添加pod到nfs名称空间
kubectl apply -f podWithPvc.yaml
这个Pod会挂载storage class生成的pv到/mnt目录,并创建一个名为seccess的文件
到nfs服务器上查看/k8s目录 可以看到多了一个名为storageClass名称+pod名称的目录
[root@www k8s]# ll
total 0
drwxrwxrwx 2 root root 21 Aug 29 09:20 nfs-hbb-pvc-pvc-f1a0750e-2214-43ac-a148-cff3db88d4f4
删除pod 再删除pvc 再去查看
[root@www k8s]# ll
total 0
drwxrwxrwx 2 root root 21 Aug 29 09:20 archived-nfs-hbb-pvc-pvc-f1a0750e-2214-43ac-a148-cff3db88d4f4
目录的名称变为archived + storageClass名称 + pod名称,这是因为storage class 声明时设置成删除且归档了
[root@www ~]# kubectl describe sc -n nfs nfs-client
Name: nfs-client
IsDefaultClass: No
Annotations: meta.helm.sh/release-name=hbb-nfs,meta.helm.sh/release-namespace=nfs
Provisioner: cluster.local/hbb-nfs-nfs-client-provisioner
Parameters: archiveOnDelete=true
AllowVolumeExpansion: True
MountOptions: <none>
ReclaimPolicy: Delete
VolumeBindingMode: Immediate
Events: <none>
这种方式比较直接删除更能保障数据安全,但是需要集群管理员定时删除不必要的归档,(例如超过1个月的归档没有开发人员认领,就删除掉)
6.4 empty volume 和 hostpath volume
补充两种卷,
- empty
- hostpath
6.4.1 empty volume
当 Pod 指定到某个节点上时,首先创建的是一个 emptyDir 卷,并且只要 Pod 在该节点上运行,卷就一直存在。 就像它的名称表示的那样,卷最初是空的。 尽管 Pod 中的容器挂载 emptyDir 卷的路径可能相同也可能不同,但是这些容器都可以读写 emptyDir 卷中相同的文件。 当 Pod 因为某些原因被从节点上删除时,emptyDir 卷中的数据也会永久删除。
说明: 容器崩溃并不会导致 Pod 被从节点上移除,因此容器崩溃时
emptyDir卷中的数据是安全的。
emptyDir 的一些用途:
- 缓存空间,例如基于磁盘的归并排序。
- 为耗时较长的计算任务提供检查点,以便任务能方便地从崩溃前状态恢复执行。
- 在 Web 服务器容器服务数据时,保存内容管理器容器获取的文件。
默认情况下, emptyDir 卷存储在支持该节点所使用的介质上;这里的介质可以是磁盘或 SSD 或网络存储,这取决于您的环境。 但是,您可以将 emptyDir.medium 字段设置为 "Memory",以告诉 Kubernetes 为您安装 tmpfs(基于 RAM 的文件系统)。 虽然 tmpfs 速度非常快,但是要注意它与磁盘不同。 tmpfs 在节点重启时会被清除,并且您所写入的所有文件都会计入容器的内存消耗,受容器内存限制约束。
示例
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}
6.4.2 hostpath volume
不常用的方式, Pod挂载node上的文件目录到pod中,略
7.调度
- nodeSelector
- taints/tolerattions
- affinity/antiAffinity
- distuption
- HPA(Horizontal pod Autoscaler)
7.1 nodeSelector(节点选择器)
- 节点标签
- Pod 加spec.nodeSelector
- 部署验证
7.1.1 节点标签
[root@www ~]# kubectl get no www.haoyun.edge1 --show-labels
NAME STATUS ROLES AGE VERSION LABELS
www.haoyun.edge1 Ready <none> 6d21h v1.18.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,isEdgeNode=,kubernetes.io/arch=amd64,kubernetes.io/hostname=www.haoyun.edge1,kubernetes.io/os=linux
挑选一个内置的hostname标签来验证
kubernetes.io/hostname=www.haoyun.edge1
7.1.2 pod加节点选择器
创建一个busybox-nodeselector.yaml,在里面加上一个节点选择器,
使用了内置的label kubernetes.io/hostname ,限定Pod只能部署到edge1上
[root@www ~]# vim busybox-nodeselector.yaml
apiVersion: v1
kind: Pod
metadata:
name: busybox-nodeselector-test
namespace: default
spec:
nodeSelector:
kubernetes.io/hostname: www.haoyun.edge1
containers:
- name: busybox
image: busybox:1.28
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
restartPolicy: Always
应用它到集群
kubectl apply -f busybox-nodeselector.yaml
7.1.3 部署验证
查看运行状态,确实跑到edge1上了
[root@www ~]# kubectl get pod -A -o wide|grep nodeselec
default busybox-nodeselector-test 1/1 Running 0 22s 10.244.6.61 www.haoyun.edge1 <none> <none>
查看生成的pod详情
spec:
containers:
- command:
- sleep
- "3600"
image: busybox:1.28
imagePullPolicy: IfNotPresent
name: busybox
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: default-token-74k2x
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
nodeName: www.haoyun.edge1
nodeSelector:
kubernetes.io/hostname: www.haoyun.edge1
验证通过
7.2 taints/tolerationss (污点/容忍)
污点是打在node上的标记,容忍是打在Pod上的标记
- 给node加污点 taints
- 给pod打容忍标记 tolerations
- 部署pod验证
7.2.1 给node 打污点标记
查看主节点www.haoyu.m1的污点
kubectl describe no www.haoyun.m1
查看spec.taints
spec:
podCIDR: 10.244.0.0/24
podCIDRs:
- 10.244.0.0/24
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
已打一个名为node-role.kubernetes.io/master 的Noschedule的污点
7.2.2 给pod打容忍标记
先用get pod -o wide查看到一个部署在www.haoyun.m1结点上的Pod
然后用describe 或edit查看到它的spec.tolerations
tolerations:
- key: CriticalAddonsOnly
operator: Exists
- effect: NoSchedule
key: node-role.kubernetes.io/master
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
其中的
- effect: NoSchedule
key: node-role.kubernetes.io/master
表示可以容忍节点上存在这个污点
7.2.3 部署验证
略
7.3 affinity/antiAffinity(亲和力/反亲和力)
亲和力/反亲和力 又分为
- 节点亲和力/反亲和力
- pod亲和力/反亲和力
node亲和力用于限定Pod部署到Node上的命中规则,
Pod亲和力则用于限定 Pod与pod 布置到同一个Node上
他们都有多种匹配规则和 “软” “硬”两次匹配策略
交叉相其实是四种不同的设置,但由于他们大同小异,故在此只以节点的亲和力来做说明。
7.3.1 节点亲和力
节点亲和力 /反亲和力使用步骤如下
- 给结点标签
- 给pod加上节点亲和力 /反亲和力
- 部署Pod验证
7.3.1.1 给结点打标签
例如给名为www.haoyun.edge1的结点打上 isedgenode的标签
kubectl label no www.haoyun.edge1 isEdgeNode=true
查看节点已打的标签
[root@www ~]# kubectl get no www.haoyun.edge1 --show-labels
NAME STATUS ROLES AGE VERSION LABELS
www.haoyun.edge1 Ready <none> 6d20h v1.18.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,isEdgeNode=,kubernetes.io/arch=amd64,kubernetes.io/hostname=www.haoyun.edge1,kubernetes.io/os=linux
7.3.1.2 给Pod加上节点亲和力
查看 nginx-ingress-controller的deployment
kubectl edit deployment -n kube-system
找到pod的template
template:
metadata:
creationTimestamp: null
labels:
app: nginx-ingress
app.kubernetes.io/component: controller
component: controller
release: my-nginx-ingress
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: isEdgeNode
operator: Exists
可以看到spec.affinity.nodeAffinity里有一条规则,必需节点选择器命中isedgenode这个标签存在, 也就是说打标签的时候不管是设置什么值,只要有isedgenode就可以部署上去。
requiredDuringSchedulingIgnoredDuringExecution必需preferredDuringSchedulingIgnoredDuringExecution尽可能
相比起节点选择器,他有更灵活的匹配替换,而且可以有“软”,“硬”两种策略
写法相对也复杂得多。
7.3.1.3 部署Pod验证
由于已经部署过了,所以直接查看,可以看到nginx-ingress-controller的Pod是在www.haoyun.edge1的结点上的。
[root@www ~]# kubectl get pod -A -o wide|grep ingress
kube-system my-nginx-ingress-controller-77d976f664-dj5vg 1/1 Running 3 6d20h 10.244.6.56 www.haoyun.edge1 <none> <none>
7.4 disruption 干扰调度
pod不会自动消息,除非自愿干扰或 非自愿干扰
-
PDB(pod disruption budget)
-
非自愿干扰
-
自愿干扰
7.4.1 pod disruption budget
pdb用于确保pod驱逐的过程中服务的可用Pod数量在安全的范围内。
官方文档对不同的部署方案的例子
-
无状态前端:
- 关注:服务容量减少不要超过10%。
- 解决方案:例如,使用minAvailable 90%的PDB。
- 关注:服务容量减少不要超过10%。
-
单实例有状态应用程序:
- 关注:请勿在不与我交谈的情况下终止此应用程序。
- 可能的解决方案1:请勿使用PDB,并且可以承受偶尔的停机时间。
- 可能的解决方案2:将PDB设置为maxUnavailable = 0。了解(在Kubernetes之外)集群操作员需要在终止之前咨询您。当集群操作员与您联系时,请准备停机,然后删除PDB以表明已准备好进行中断。之后重新创建。
- 关注:请勿在不与我交谈的情况下终止此应用程序。
-
多实例有状态应用程序,例如Consul,ZooKeeper或etcd:
- 关注:不要将实例数量减少到仲裁以下,否则写入将失败。
- 可能的解决方案1:将maxUnavailable设置为1(适用于不同的应用程序规模)。
- 可能的解决方案2:将minAvailable设置为法定大小(例如,小数位数为5时为3)。(一次允许更多中断)。
- 关注:不要将实例数量减少到仲裁以下,否则写入将失败。
-
可重新启动的批处理作业:
-
关注:在自愿中断的情况下,工作需要完成。
- 可能的解决方案:不要创建PDB。作业控制器将创建一个替换容器。
-
pdb通过设置 maxunAvailable (最大不可用pod个数)或 minAvailable(最小可用pod个数) 来保证Pod驱逐时服务的可用性,例:
例:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
maxUnavailable: 1
selector:
matchLabels:
app: zookeeper
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: zookeeper
7.4.2 非自愿干扰
- 节点下层物理机的硬件故障
- 集群管理员错误地删除虚拟机(实例)
- 云提供商或虚拟机管理程序中的故障导致的虚拟机消失
- 内核错误
- 节点由于集群网络隔离从集群中消失
- 由于节点资源不足导致 pod 被驱逐。
这里只着重介绍资源不足导致的Pod被驱逐,因为其他情况都与配置无关
7.4.2.1 eviction api
eviction api是一组kubelet的api,用于指定当Node的资源不足时,(一般是指硬盘空间不足或内存不足的情况 ,)要如何驱逐Pod以保证node的资源始终在合理的范围内,可以在kubelet 的config map里配置,或者命令行启动参数的方式设置eviction api, 可参阅文档
一个例子:
- 节点内存容量:
10Gi - 操作员希望为系统守护进程保留 10% 内存容量(内核、
kubelet等)。 - 操作员希望在内存用量达到 95% 时驱逐 pod,以减少对系统的冲击并防止系统 OOM 的发生。
为了促成这个场景,kubelet将像下面这样启动:
--eviction-hard=memory.available<500Mi
--system-reserved=memory=1.5Gi
这个配置的暗示是理解系统保留应该包含被驱逐阈值覆盖的内存数量。
要达到这个容量,要么某些 pod 使用了超过它们请求的资源,要么系统使用的内存超过 1.5Gi - 500Mi = 1Gi。
这个配置将保证在 pod 使用量都不超过它们配置的请求值时,如果可能立即引起内存压力并触发驱逐时,调度器不会将 pod 放到这个节点上。
7.4.3 自愿干扰
- 程序所有者主动干扰
- 集群管理员主动干扰
7.4.3.1 程序所有者主动干扰
- 删除 Deployment 或其他管理 Pod 的控制器
- 更新了 Deployment 的 Pod 模板导致 Pod 重启
- 直接删除 Pod(例如,因为误操作)
7.4.3.2 集群管理员主动干扰
本节只会介绍排空,因为2 一般用于云供应商平台,3太简单略。
7.4.3.2.1 drain /uncordon(排空 )
有时候某个Node需要停止运行维护,比如加内存之类的操作,这时如果只是删除Node上的pod, 则很大概率新的pod会重新被调度到这个node上,这种情况下集群管理员应该排空这个node,在维护结束后再结束之后再使用uncordon,使Pod能被调试到这个维护结束的node上
例如对 www.haoyun.edge1结点做排空操作
kubectl drain www.haoyun.edge1
维护结束之后恢复
kubectl uncordon www.haoyun.edge1
7.5 Horizontal pod Autoscaler
略,需要配合promethues 之类的数据采集才可以使用,可能之后专门讲promethues再讨论,因为这个功能对浩云来说不是很重要
8.pod配置
- enviorment 环境变量
- volume 卷
- proms 探针
8.1 设置pod环境变量
-
写在docker file里
-
使用helm 写pod 参数里传递
-
使用config map
略
8.2 设置pod的存储卷
参见 6.配置和存储
略
8.3 probes 探针
kubelet 使用存活探测器来知道什么时候要重启容器。 例如,存活探测器可以捕捉到死锁(应用程序在运行,但是无法继续执行后面的步骤)。 这样的情况下重启容器有助于让应用程序在有问题的情况下更可用。
kubelet 使用就绪探测器可以知道容器什么时候准备好了并可以开始接受请求流量, 当一个 Pod 内的所有容器都准备好了,才能把这个 Pod 看作就绪了。 这种信号的一个用途就是控制哪个 Pod 作为 Service 的后端。 在 Pod 还没有准备好的时候,会从 Service 的负载均衡器中被剔除的。
kubelet 使用启动探测器可以知道应用程序容器什么时候启动了。 如果配置了这类探测器,就可以控制容器在启动成功后再进行存活性和就绪检查, 确保这些存活、就绪探测器不会影响应用程序的启动。 这可以用于对慢启动容器进行存活性检测,避免它们在启动运行之前就被杀掉。
-
探针探测类型
-
探针可配置项
-
启动探针 startupProbe
-
就绪探针 readinessProbe
-
存活探针 livenessProbe
8.3.1 探针探测类型
由于各种探针的写法是一样的,只是名称不同,作用也不同
于是这里以存活探针为例,实践以下几种探针的探测方法
- 命令行
- http
- tcp
8.3.1.1 命令行探针
命令返回成功存活,失败kubelet根据restartPolicy处置Pod
Pod 的
spec中包含一个restartPolicy字段,其可能取值包括 Always、OnFailure 和 Never。默认值是 Always。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5 #首次延迟5秒检测
periodSeconds: 5 #每5秒检测一次
8.3.1.2 http探针
http responed 大于等于200小于400成功 ,否则大于等于400失败,kubelet根据restartPolicy处置 pod
Pod 的
spec中包含一个restartPolicy字段,其可能取值包括 Always、OnFailure 和 Never。默认值是 Always。
1.13版本之前,如果设置了 http_proxy环境变量,则探针会使用代理,1.13版本后探针不使用代理。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: k8s.gcr.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
8.3.1.3 tcp探针
tcp探针的示例使用了就绪探针和存探针
并不是就绪探针探测就绪了才会使用存活探针去检测存活,这两个探针是并行的
如果需要设置在容器启动成功后再探测存活,应该使用启动探针 (startupProbe
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: k8s.gcr.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
8.3.2 探针可配置项
Probe 有很多配置字段,可以使用这些字段精确的控制存活和就绪检测的行为:
initialDelaySeconds:容器启动后要等待多少秒后存活和就绪探测器才被初始化,默认是 0 秒,最小值是 0。periodSeconds:执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1。timeoutSeconds:探测的超时后等待多少秒。默认值是 1 秒。最小值是 1。successThreshold:探测器在失败后,被视为成功的最小连续成功数。默认值是 1。 存活探测的这个值必须是 1。最小值是 1。failureThreshold:当探测失败时,Kubernetes 的重试次数。 存活探测情况下的放弃就意味着重新启动容器。 就绪探测情况下的放弃 Pod 会被打上未就绪的标签。默认值是 3。最小值是 1。
HTTP Probes 可以在 httpGet 上配置额外的字段:
host:连接使用的主机名,默认是 Pod 的 IP。也可以在 HTTP 头中设置 “Host” 来代替。scheme:用于设置连接主机的方式(HTTP 还是 HTTPS)。默认是 HTTP。path:访问 HTTP 服务的路径。httpHeaders:请求中自定义的 HTTP 头。HTTP 头字段允许重复。port:访问容器的端口号或者端口名。如果数字必须在 1 ~ 65535 之间。
对于 HTTP 探测,kubelet 发送一个 HTTP 请求到指定的路径和端口来执行检测。 除非 httpGet 中的 host 字段设置了,否则 kubelet 默认是给 Pod 的 IP 地址发送探测。 如果 scheme 字段设置为了 HTTPS,kubelet 会跳过证书验证发送 HTTPS 请求。 大多数情况下,不需要设置host 字段。 这里有个需要设置 host 字段的场景,假设容器监听 127.0.0.1,并且 Pod 的 hostNetwork 字段设置为了 true。那么 httpGet 中的 host 字段应该设置为 127.0.0.1。 可能更常见的情况是如果 Pod 依赖虚拟主机,你不应该设置 host 字段,而是应该在 httpHeaders 中设置 Host。
对于一次 TCP 探测,kubelet 在节点上(不是在 Pod 里面)建立探测连接, 这意味着你不能在 host 参数上配置服务名称,因为 kubelet 不能解析服务名称。
9. helm
为了第十章,必须把helm的一直基本姿势介绍一下,所以有第9章
- helm是什么
- 安装helm
- chart 是文件结构介绍
- helm 语法
9.1 helm是什么
helm是kubernetes的包管理器,用于查找,分享,使用kubernetes生态的应用。
9.2 安装helm
- 前置条件
- 安装
- windows
- linux
9.2.1 前置条件
- 拥有一个集群
- 拥有kubectl,并配置用于与kubeapi通讯的config连接配置文件
一般helm都是安装在主节点上,开发人员用有权限范围的用户登录上去操作helm即可,
可以和git结合使用,或安装helm局域网服务器Tiller
也可以在开发人员机器上通过config+kubectl 直接连接 上集群 ,但是这样开发人员需要在自己电脑上安装kubectl。
9.2.2 安装
无论是windows还是linux,都是直接去下载helm的二进制文件。
linux复制helm二进制到bin目录:
mv helm /usr/bin
windows设置环境变量:
我的电脑属性->高级->设置环境变量->path+=
9.3 chart文件结构
xxx_chart/
Chart.yaml # chart的信息文件
LICENSE # 可选: 许可证 如:GPL LGPL
README.md # 可选:
values.yaml # 默认的配置值文件
values.schema.json # 可选: 对value.yaml提供输入格式校验的josn文件
charts/ # 依赖的其他图表的存放文件夹
crds/ # 自定义资源
templates/ # 使用go模版的yaml文件,会从value.yaml或其他文件读值生成资源yaml
templates/NOTES.txt # 可选: 安装成功时,显示在终端上的文字
9.4 helm语法
helm语法是yaml混合 go模版的语法
听起来很复杂,其实学起来不复杂
仅需要抓着helm chart安装生成的文件抽丝剥茧,就能快速掌握,因为本身并不复杂
-
上下文
-
.根 -
.valuevalue.yaml -
.release安装时用户输入 -
.chartchart.yaml
-
-
模版
- 定义
- 使用
-
其他语法 去官网文档查
10.把.net core web app部署到集群并附加调试
现有两个.net core web app
- api
- blazor
前端将通过ingress暴露给集群外部,后端则只在集群内部。以此为例实践第10章
- 工具推荐
- visual studio
- visual studio tools for kubernetes
- visual studio code
- C#
- YAML
- kubernetes
- cloud code for visual studio code
- visual studio
- 将现有.net core web app部署到集群
10.1 工具推荐
略
10.2 将现有.net core web app部署到集群
10.2.1 为现有项目添加chart和docker file
这个在前端和后端web app中都需要做,因为都要部署到集群。
在visual studio 安装10.1中的扩展后
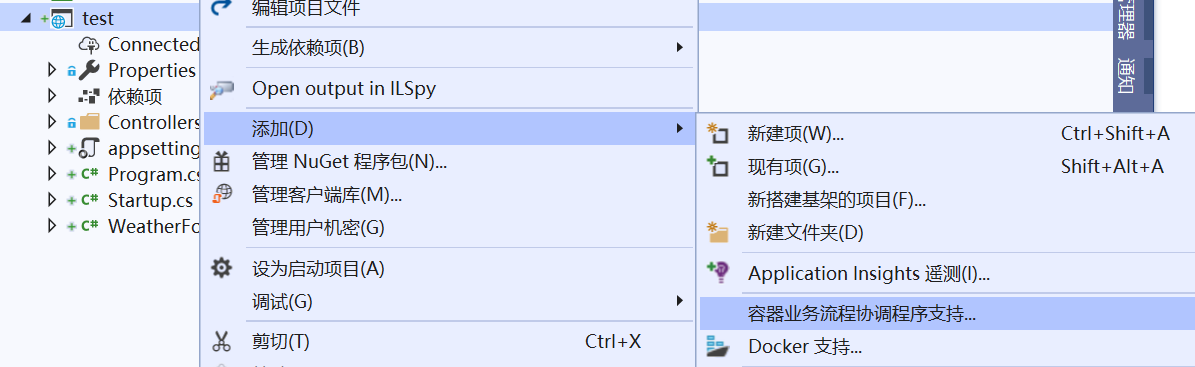
选择kubernetes/helm
确定后生成chart文件夹和docker file,还有一个azds.yaml (部署到微软云上才用到),
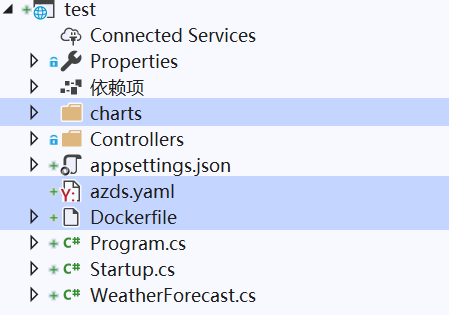
10.2.2 程序配置
10.2.2.1 后端
- 端口
- 跨域策略
- api实现
10.2.2.1.1 端口配置5001
public class Program
{
public static void Main(string[] args)
=> CreateHostBuilder(args).Build().Run();
public static IHostBuilder CreateHostBuilder(string[] args)
=> Host.CreateDefaultBuilder(args)
.ConfigureWebHostDefaults(
webBuilder => webBuilder
.UseStartup<Startup>().UseUrls("http://*:5001"));
}
value.yaml中修改服务的targetport
service:
type: ClusterIP
port: 80
targetPort: 5001
修改deployment.yaml里的image 和containerPort
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ template "hscadaexapi.fullname" . }}
labels:
# 略
spec:
revisionHistoryLimit: 0
replicas: {{ .Values.replicaCount }}
selector:
matchLabels:
app: {{ template "hscadaexapi.name" . }}
release: {{ .Release.Name }}
template:
# 略
spec:
containers:
- name: {{ .Chart.Name }}
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
imagePullPolicy: {{ .Values.image.pullPolicy }}
ports:
- name: http
containerPort: {{ .Values.service.targetPort}}
protocol: TCP
10.2.2.1.2 跨域策略
.net core因为安全性设计,默认不支持非同源策略的域名对.net web app进行访问
下表给出了与 URL http://store.company.com/dir/page.html 的源进行对比的示例:
| URL | 结果 | 原因 |
|---|---|---|
http://store.company.com/dir2/other.html |
同源 | 只有路径不同 |
http://store.company.com/dir/inner/another.html |
同源 | 只有路径不同 |
https://store.company.com/secure.html |
失败 | 协议不同 |
http://store.company.com:81/dir/etc.html |
失败 | 端口不同 ( http:// 默认端口是80) |
http://news.company.com/dir/other.html |
失败 | 主机不同 |
定义1个策略名称
public readonly string myAllowSpecificOrigins = "myAllowSpecificOrigins";
配置策略
// startup.cs
public void ConfigureServices(IServiceCollection services)
{
//略
services.AddCors(o =>
{
o.AddPolicy(myAllowSpecificOrigins, build =>
{
build
.AllowAnyOrigin()
.AllowAnyHeader()
.AllowAnyMethod();
});
});
//略
}
添加到中单件管道
// startup.cs
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
//略
app.UseCors(myAllowSpecificOrigins);
//略
}
10.2.2.1.3 api实现
略
10.2.2.2 前端
- 端口
- userApi url
- 调试时根据launch.json传变环境变量
- 部署时通过deployment的pod 模版传入环境变量
10.2.2.2.1 端口
同10.2.2.1.1,略
10.2.2.2.2 userApi环境变量
10.2.2.2.2.1 调试时
launchSetting.json
{
"profiles": {
"HScadaEx.Blazor": {
"commandName": "Project",
"launchBrowser": true,
"environmentVariables": {
"ASPNETCORE_ENVIRONMENT": "Development",
"userApi": "http://localhost:5001"
},
"applicationUrl": "http://localhost:5011"
}
}
}
10.2.2.2.2.2 部署时
value.yaml
# 略
userApi: http://hscadaexapi.hbb.svc # http://服务名称.名称空间.svc
# 略
deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ template "hscadaexblazor.fullname" . }}
# 略
spec:
#略
template:
# 略
spec:
containers:
- name: {{ .Chart.Name }}
# 略
env:
# 略
- name: userApi
value: {{ .Values.userApi | quote }}
程序中使用环境变量
// startup.cs
public void ConfigureServices(IServiceCollection services)
{
var userApi = Environment.GetEnvironmentVariable("userApi");
services.AddHttpClient("usersApi", x =>
{
x.BaseAddress = new Uri($"{userApi}/api/Users/");
x.DefaultRequestHeaders.Add("User-Agent", "BlazorSever");
x.DefaultRequestHeaders.Accept.Add(new System.Net.Http.Headers.MediaTypeWithQualityHeaderValue("application/json"));
}).SetHandlerLifetime(TimeSpan.FromSeconds(30));
Console.WriteLine($"环境变量userApi = {userApi}");
services.AddTransient<IBLL.User.IUserService, Service.UsersServer>();
}
10.2.2.2.3 ingress 集群入口资源
我希望访问www.haoyun.blazor的时候,可以从集群外部访问前端应用
访问链路:用户-> www.haoyun.blazor->dns->集群边缘节点外部ip->ingress controller(集群)->blazor server--ipvs-->pod(集群)
values.yaml
ingress:
enabled: true
annotations:
# kubernetes.io/tls-acme: "true"
path: /
hosts:
- www.haoyun.blazor
tls: []
# - secretName: chart-example-tls
# hosts:
# - chart-example.local
/template/ingerss.yaml 保持不变即可
{{- if .Values.ingress.enabled -}}
{{- $fullName := include "hscadaexblazor.fullname" . -}}
{{- $servicePort := .Values.service.port -}}
{{- $ingressPath := .Values.ingress.path -}}
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: {{ $fullName }}
labels:
app: {{ template "hscadaexblazor.name" . }}
chart: {{ template "hscadaexblazor.chart" . }}
release: {{ .Release.Name }}
heritage: {{ .Release.Service }}
{{- with .Values.ingress.annotations }}
annotations:
{{ toYaml . | indent 4 }}
{{- end }}
spec:
{{- if .Values.ingress.tls }}
tls:
{{- range .Values.ingress.tls }}
- hosts:
{{- range .hosts }}
- {{ . }}
{{- end }}
secretName: {{ .secretName }}
{{- end }}
{{- end }}
rules:
{{- range .Values.ingress.hosts }}
- host: {{ . }}
http:
paths:
- path: {{ $ingressPath }}
backend:
serviceName: {{ $fullName }}
servicePort: http
{{- end }}
{{- end }}
10.2.3 理解/修改docker file以支持调试
默认的docker file解读
FROM mcr.microsoft.com/dotnet/core/aspnet:3.1 AS base #以..3.1环境为基础创建一个名为base的镜像
WORKDIR /app #设置工作目录 保存为匿名镜像
EXPOSE 80 #导出端口 80 保存为匿名镜像
FROM mcr.microsoft.com/dotnet/core/sdk:3.1 AS build #以..sdk3.1为基础创建一个名为build的镜像
WORKDIR /src #设置工作目录 保存为匿名镜像
COPY ["src/test/test.csproj", "src/test/"] #复制csobj文件 保存为匿名镜像
RUN dotnet restore "src/test/test.csproj" #还原nuget包 保存为匿名镜像
COPY . . #递归复制解决方案到 src目录 保存为匿名镜像
WORKDIR "/src/src/test" #设置工作目录为镜像中的test项目目录 保存为匿名镜像
RUN dotnet build "test.csproj" -c Release -o /app/build #在镜像中编译 保存为匿名镜像
FROM build AS publish #以build 为基础 创建一个名为publish的镜像
RUN dotnet publish "test.csproj" -c Release -o /app/publish #发布到/app/publish目录 保存为匿名镜像
FROM base AS final #base为基础创建一个名为final的镜像
WORKDIR /app #设置工作目录,保存为匿名镜像
COPY --from=publish /app/publish . #复制publish镜像的/app/publish文件夹到final的工作目录 保存为匿名镜像
ENTRYPOINT ["dotnet", "test.dll"] # 设置入口 保存为匿名镜像
修改release->debug ,添加调试工具后
以api 的dockerfile为例, blazor略
FROM mcr.microsoft.com/dotnet/core/aspnet:3.1-buster-slim AS base
WORKDIR /app
EXPOSE 5001 #导出所需端口
RUN apt-get update && apt-get install -y --no-install-recommends unzip && apt-get install -y procps && rm -rf /var/lib/apt/lists/* && curl -sSL https://aka.ms/getvsdbgsh | bash /dev/stdin -v latest -l /vsdbg # 调试工具安装
FROM mcr.microsoft.com/dotnet/core/sdk:3.1-buster AS build
WORKDIR /src
COPY ["src/HScadaEx.API/HScadaEx.API.csproj", "src/HScadaEx.API/"]
COPY ["src/HScadaEx.IBLL/HScadaEx.IBLL.csproj", "src/HScadaEx.IBLL/"]
COPY ["src/HScada.Model/HScada.Model.csproj", "src/HScada.Model/"]
COPY ["src/HscadaEx.BLL/HscadaEx.BLL.csproj", "src/HscadaEx.BLL/"]
COPY ["src/HScadaEx.Core/HScadaEx.Core.csproj", "src/HScadaEx.Core/"]
RUN dotnet restore "src/HScadaEx.API/HScadaEx.API.csproj"
COPY . .
WORKDIR "/src/src/HScadaEx.API"
RUN dotnet build "HScadaEx.API.csproj" -c Debug -o /app/build #改为debug,不需要调试就用release
FROM build AS publish
RUN dotnet publish "HScadaEx.API.csproj" -c Debug -o /app/publish#改为debug,不需要调试就用release
FROM base AS final
WORKDIR /app
COPY --from=publish /app/publish .
ENTRYPOINT ["dotnet", "HScadaEx.API.dll"]
10.2.4 部署
- 构建docker ,把docker镜像传输到
工作节点上 - 复制chart到
主节点上 - 使用helm 部署到 hbb名称空间
10.2.4.1 构建docker镜像
由于个人计算机资源有限,所以我这里只使用docker save 和docker load命令 将docker镜像复制到仅有的一个工作节点上。正确的做法是在集群外部搭建一个docker私有仓库,按需拉取。
已知私有仓库部署方式
- docker-registry 简易的,没有认证授权功能
- Harbor
- nexus
对于 2和3 有认证授权的镜像
正确的姿势是配置好证书后,导入为secret资源,在拉取镜像时指定secret资源即可。
10.2.4.2 复制chart到主节点
同样 chart也有私有服务器可以搭建,名为Tiller,正确的姿势也是应该搭服务器,让集群调度的时候按需获取,
10.2.4.3 helm 常用指令
更多信息查看官网文档 或 helm -h
查看
helm ls -n 名称空间
添加repository
helm add repo 名称 url
安装
helm install -n 名称空间 release名称 chart
#其中的chart 可以是本地文件,也可以是tiller上的chart路径
更新
helm upgrade -n 名称空间 release名称 chart
查看变更历史记录
helm history -n 名称空间 release名称
回滚
helm rollback
删除
helm delete -n 名称空间 release名称
10.2.3 调试
- 通过kubernetes api 的客户端进行附加调试
- 开发过程中的快速调试okteto
10.2.3.1 通过kubernetes api客户端
10.2.3.1.1 安装kubectl 配置 集群连接信息
-
下载kubectl二进制,添加到系统变量path
-
复制集群管理员生成的 config文件到 c:\用户\.kube 文件夹
10.2.3.1.2 修改docker file
- release->debug
- 安装vsdbg
#See https://aka.ms/containerfastmode to understand how Visual Studio uses this Dockerfile to build your images for faster debugging.
FROM mcr.microsoft.com/dotnet/core/aspnet:3.1-buster-slim AS base
WORKDIR /app
EXPOSE 5001
EXPOSE 5002
RUN apt-get update && apt-get install -y --no-install-recommends unzip && apt-get install -y procps && rm -rf /var/lib/apt/lists/* && curl -sSL https://aka.ms/getvsdbgsh | bash /dev/stdin -v latest -l /vsdbg
FROM mcr.microsoft.com/dotnet/core/sdk:3.1-buster AS build
WORKDIR /src
COPY ["src/HScadaEx.API/HScadaEx.API.csproj", "src/HScadaEx.API/"]
COPY ["src/HScadaEx.IBLL/HScadaEx.IBLL.csproj", "src/HScadaEx.IBLL/"]
COPY ["src/HScada.Model/HScada.Model.csproj", "src/HScada.Model/"]
COPY ["src/HscadaEx.BLL/HscadaEx.BLL.csproj", "src/HscadaEx.BLL/"]
COPY ["src/HScadaEx.Core/HScadaEx.Core.csproj", "src/HScadaEx.Core/"]
RUN dotnet restore "src/HScadaEx.API/HScadaEx.API.csproj"
COPY . .
WORKDIR "/src/src/HScadaEx.API"
RUN dotnet build "HScadaEx.API.csproj" -c Debug -o /app/build
FROM build AS publish
RUN dotnet publish "HScadaEx.API.csproj" -c Debug -o /app/publish
FROM base AS final
WORKDIR /app
COPY --from=publish /app/publish .
ENTRYPOINT ["dotnet", "HScadaEx.API.dll"]
10.2.3.1.3 LaunchSetting.json
这里用cloud code插件生成调试配置
launchSetting.json
{
"version": "0.2.0",
"configurations": [
{
"name": "Attach to Kubernetes Pod (.NET Core)",
"type": "cloudcode.kubernetes",
"request": "attach",
"language": "NETCore",
"podSelector": {
"app": "hscadaexblazor" //pod的app label
},
"localRoot": "${workspaceFolder}", //本地工作区
"remoteRoot": "/app" //远程容器中的工作目录
}
]
}
.net core目前只能用于附加调试, go/node.js/py 可以热重载调试,从谷歌插件的文档上看到的。
这种方式的缺点很明显,如果要调试过程修改了代码,由于不能热重载,只能在本地改好代码->重生成docker image->推送到docker repository ->更新image到集群 ->再附加调试
所以比较推荐另一种方式的调试,虽然也不支持热重载,但是用dotnet watch run,在代码重生成时实时响应到容器中,并重启容器中的程序
10.2.3.2 通过okteto 在开发过程中快速调试
okteto是一个开源的项目,用于简化各种技术栈 在kubernetes中的开发工程。
传统的kubernetes 服务开发过程就是不断的重复这个过程
while(调试ing)
{
附加调试->修改代码->生成docker镜像->推送镜像->拉镜像->更新到集群
}
okteto的方式是把开发环境打包成一个镜像,实时同步容器与本地的文件变化,转发本地流量到容器 、转发容器流量到本地 等连接调试用的是ssh ,配合dotnet watch run 可以仅是生成代码就把生成的结果应用到容器中,虽然不是真正的热重载,容器中的程序会重启,但快速了很多,而且这是各种技术栈都能用的,不仅限于.net 的万金油,于是流程简化为
do
{
dotnet watch run
}while(调试ing)
{
附加调试->修改代码->生成
}
10.2.3.2.1 安装okteto
- 下载二进制文件,并加到系统环境变量path
- 复制集群管理员生成的config ,放到 c:\用户\.kube文件夹
10.2.3.2.2 在解决方案中添加okteto.yaml
name: hscadaexapi #deployment service 的名称
namespace: hbb #名称空间
image: mcr.microsoft.com/dotnet/core/sdk #开发环境变量
environment:
- ASPNETCORE_ENVIRONMENT=Development #环境变量
command:
- bash #启动命令
workdir: /okteto #工作目录
remote: 22000 # ssh调试端口 把本地22000->容器22
sync: #同步的文件夹 本地:容器
- .:/okteto
forward: #端口转发 本地:容器
- 5001:5001
persistentVolume: {}
10.2.3.2.3 启动okteto ,
okteto up
这里集群里会多出一个deployment 和service 资源, 跑起一个pod,这个pod是空的,仅仅是一个开发环境,
然后okteto会并 当前文件夹的文件同步到远程容器中的$workdir ,并执行 $command
接下去就是在容器中启动.net core程序
dotnet watch run
查看工作台输出 已经启动了程序的话, 在本地访问 localhost:forward 应该访问到容器上了
10.2.3.2.4 通过ssh连接容器调试
大多数ide都支持ssh远程调试,这里我以visual studioi为例
alt+shift+p 附加调试,选择 ssh ,配置参数
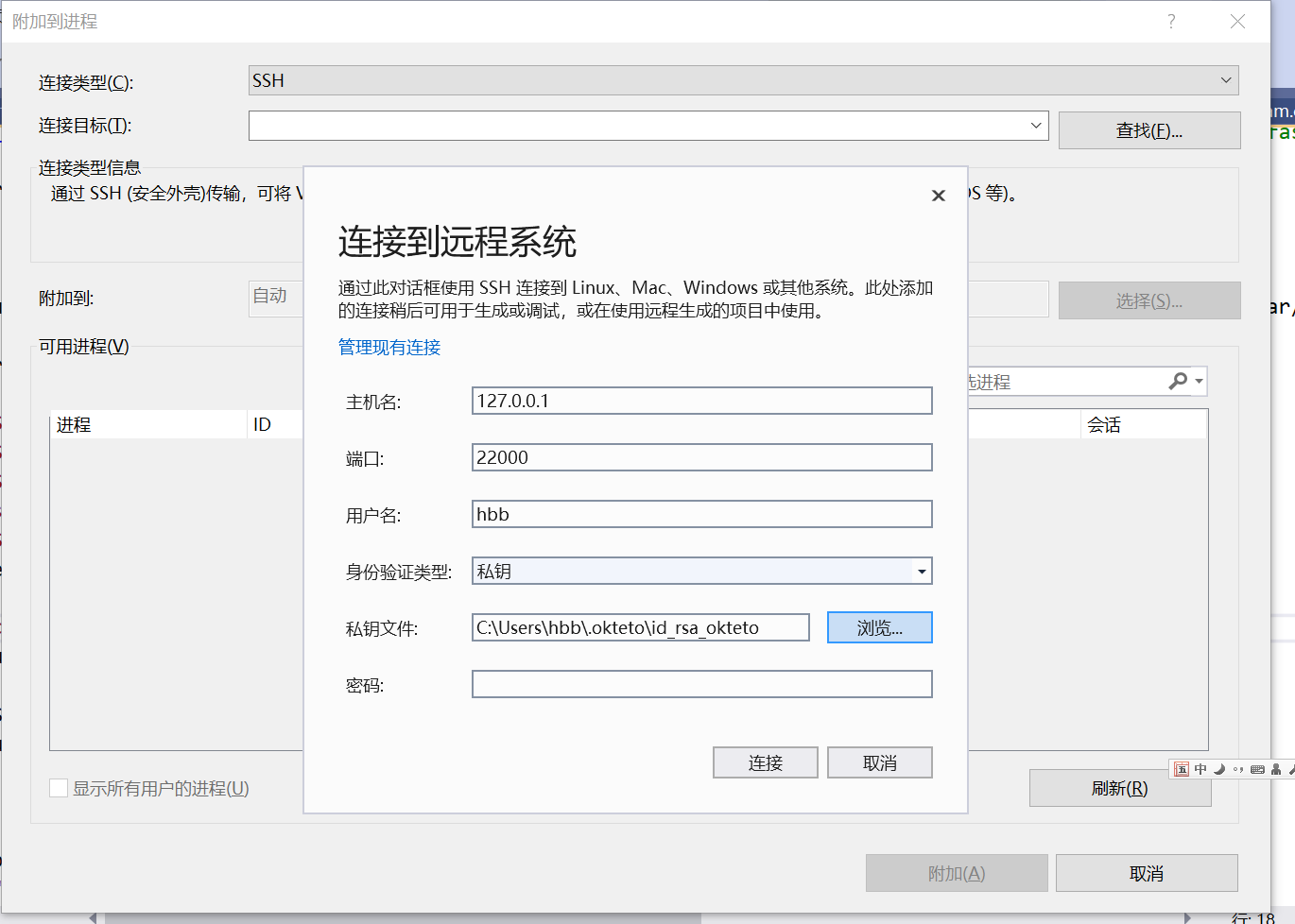
之后就会让你选择要附加的进程了



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏