第一次个人编程作业
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 10 | 20 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 120 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 5 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 180 | 300 |
| · Coding | · 具体编码 | 900 | 1200 |
| · Code Review | · 代码复审 | 120 | 600 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 10 |
| · 合计 | 1585 | 2475 |
二、计算模块接口
2.1 计算模块接口的设计与实现过程
2.1.1 程序设计思路
-
在刚开始看到这个题时我只能想到循环查找字符串、利用树存储来加快时间等模糊的想法,但并没有实际的能力去实现。在我参考了不少同学的思路后,我发现总共大多是使用DFA或AC自动机的方法。在思考哪个更适合我之后,我选择了用python来实现DFA算法。
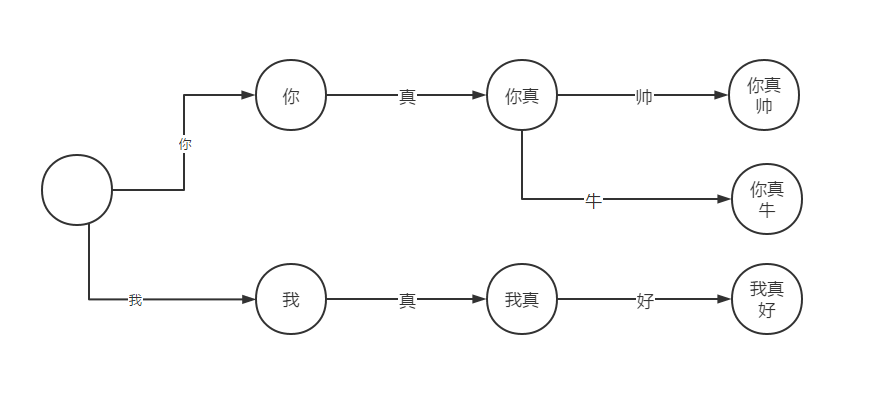
如图将关键词“你真帅”“我真好”“你真牛”用该树存储起来。从根节点开始,在比较待查文本的字符时,若遇到“你”则进入“你”节点,并判断此时状态:显然并不是终点,“帅”或“牛”才是。而如果整个比较过程都没有出错,顺利到了终点,那么便成功找到了一个关键词,若出错则重来。 -
在python中,用字典dict来实现DFA算法较方便。如下,可见使用字典实现可以避免不少麻烦。
state_event_dict = {
'你':{
'真':{
'帅':{
'is_end':True
},'is_end':False
'牛':{
'is_end':True
},'is_end':False
},
},
'我':{
'真':{
'好':{
'is_end':True
},'is_end':False
},'is_end':False
}
},
2.1.2实际思路
- 在实践中,我一开始先实现了查找字符的DFA算法,该算法只能检测出完全符合敏感词的文本。在之后我将输入的keywords_list扩充为拼音、首字母、汉字的所有组合,用这样来实现能够检测出除了原词以外的各种变体。但是遇到同音字仍然没有办法,于是我放弃了将汉字作为检测字符,对于待测文本中的每一个汉字都转化为拼音,通过拼音来实现能检测出同音词的功能。但是仍不能解决左右拆分的汉字的问题,我曾试过将偏旁也转为拼音后进行检测,后来发现不仅效率降低不少,而且许多原本能检测出来的词也检测不出来了,由于水平有限,还是放弃了偏旁检测。不过最终还是能在给的示例样本中达到百分之九十以上的成功率,还是可以了。
2.1.3代码实现
-
类
class DFA
内含_generate_state_event_dict函数,自动生成keyword_list(关键词查找树),以及match函数,根据输入的关键词在(keyword_list)树上查找并输出。但只提供了基础的输入输出功能,对关键词输入的优化(增添删改)以及获取数据的输出格式还需外部函数进行优化。
-
主要函数
-
将敏感词从文件输入并转为列表方便操作
-
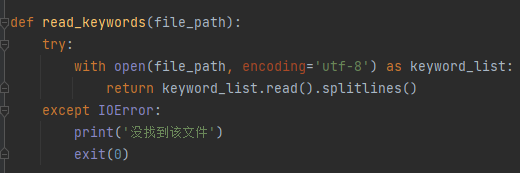
def read_keywords(file_path): with open(file_path, encoding='utf-8') as keyword_list: return keyword_list.read().splitlines()将待查文本从文件输入转为字符串方便操作
-
def read_article(file_path): with open(file_path, encoding='utf-8') as article: return article.read()将数据按格式输出到ans.txt
-
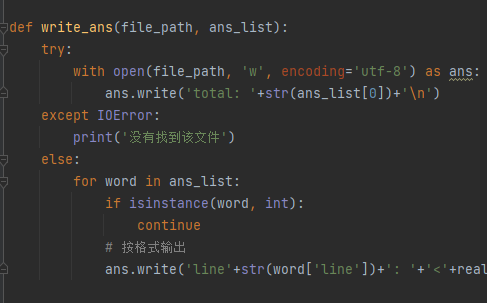
def write_ans(file_path, ans_list): with open(file_path, 'w', encoding='utf-8') as ans: ans.write('total: '+str(ans_list[0])+'\n') for word in ans_list: if isinstance(word, int): continue ans.write('line'+str(word['line'])+': '+'<'+real_keyword[word['keyword']]+'> ' + word['match'] + '\n')扩充敏感字列表,加入拼音、拼音首字母、汉字等各种变形的敏感字plus
# 扩充关键字列表 for keyword in keyword_list: # 注意使用lazy_pinyin(一维列表)而不是pinyin(二维列表) if ord(keyword[0]) > 255: pinyin_list = lazy_pinyin(keyword) # 首字母 first_letter_list = lazy_pinyin(keyword, 4) # 判断是否中文避免数组越界( dfs(keyword, after_list, pinyin_list, first_letter_list, "", 0, len(keyword)) return after_list -
关键的递归,让敏感字变形更迅速,扩充敏感字列表也就更方便
def dfs(keyword, after_list, pinyin_list, first_letter_list, cur_chars, w, length): if w == length: # 保存原形,为了能格式输出 real_keyword[cur_chars] = keyword if cur_chars not in after_list: after_list.append(cur_chars) return dfs(keyword, after_list, pinyin_list, first_letter_list, cur_chars + first_letter_list[w], w + 1, length) dfs(keyword, after_list, pinyin_list, first_letter_list, cur_chars + pinyin_list[w], w + 1, length) -
使用match函数来对文本进行关键词检测
def match(self, content: str): # 引入got_one_end达成避免在出现flgong时同时检测出flg与flgong的错误现象的目的,pop掉flg,使用列表是为了方便在函数间传递 got_one_end = [False] match_list = [0] state_list = [] temp_match_list = [] # 默认第一行开始 which_line = 1 for char_pos, char in enumerate(content): is_pin = False if char == '\n': which_line += 1 # 英文转小写 if 65 <= ord(char) <= 90: char = char.lower() # print(char+"here!!!\n") # 汉字转拼音(除了偏旁) if 19968 <= ord(char) <= 40869: # if char not in pianpangs: char = lazy_pinyin(char)[0] is_pin = True if is_pin: for index, char_part in enumerate(char): # 对拼音的最后一个字符进行判定,若符合,则将原本汉字存入错误文本中 if index == len(char) - 1: self._match_part(char_part, char_pos, match_list, state_list, temp_match_list, content, which_line, got_one_end) continue # 对拼音除最后一个字符之外的每一个都进行判定,输入None是为了不把拼音存入错误文本中 if self._match_part(char_part, index, match_list, state_list, temp_match_list, None, which_line, got_one_end) == -1: break else: self._match_part(char, char_pos, match_list, state_list, temp_match_list, content, which_line, got_one_end) return match_list -
match_part函数是用于检测文本的一个字符是否符合关键词,过程较为复杂
def _match_part(self: str, char, char_pos, match_list, state_list, temp_match_list, content, which_line, got_one_end): # 如果是某关键词首字母则从开头头开始 # temp_match_list的match的值是变形后敏感词文本,keyword是未变形的敏感词文本 if char in self.state_event_dict: state_list.append(self.state_event_dict) temp_match_list.append({ "line": which_line, "match": "", "keyword": "" }) for index, state in enumerate(state_list): # 排除特殊字符 if char in ['`', '1', '2', '3', '4', '5', '6', '7', '8', '9', '0', ';', '-', '=', '[', ']', '\\', '\'', ',', '.', '/', '~', '!', '@', '#', '$', '%', '^', '&', '*', '(', ')', '+', '_', '{', '}', '|', ':', '"', '<', '>', '?', '…', '·', '*', '?', '【', '】', '《', '》', ':', '“', ',', '。', '、', '/', ' ', '¥', '!']: # 也可以使用排除掉汉字、英文字母的方法 # if not 19968 <= ord(char) <= 40869 and not 97 <= ord(char) <= 122 and not 65 <= ord(char) <= 90: if content: temp_match_list[index]["match"] += content[char_pos] # 直接跳过字符到下一个 continue if char in state: # 进入下一个关键字的字符 state_list[index] = state[char] # 大写字母保存在错误文本,原关键词保存在正确文本 if content: temp_match_list[index]["match"] += content[char_pos] temp_match_list[index]["keyword"] += char if state[char]["is_end"]: match_list.append(copy.deepcopy(temp_match_list[index])) match_list[0] += 1 if len(state[char].keys()) == 1: # 这一步是排除未完整检测完如 flgong 便将flg加入检测出的列表中的错误 if got_one_end[0]: match_list.pop() match_list.pop() match_list[0] -= 1 match_list.append(copy.deepcopy(temp_match_list[index])) state_list.pop(index) temp_match_list.pop(index) got_one_end[0] = False else: state_list.pop(index) temp_match_list.pop(index) continue # 比如出现flgong,该代码是为了避免同时检测出flg与flgong,pop掉flg got_one_end[0] = True else: state_list.pop(index) temp_match_list.pop(index) return -1
-
2.2 计算模块接口部分的性能改进
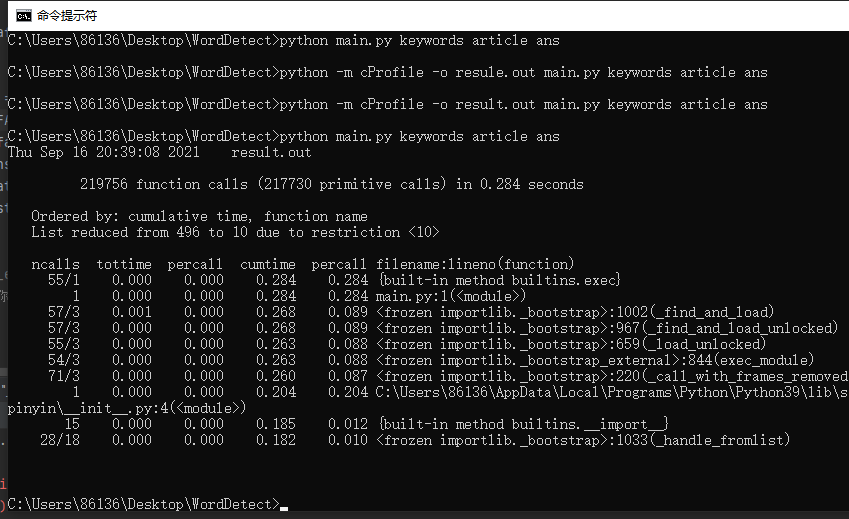
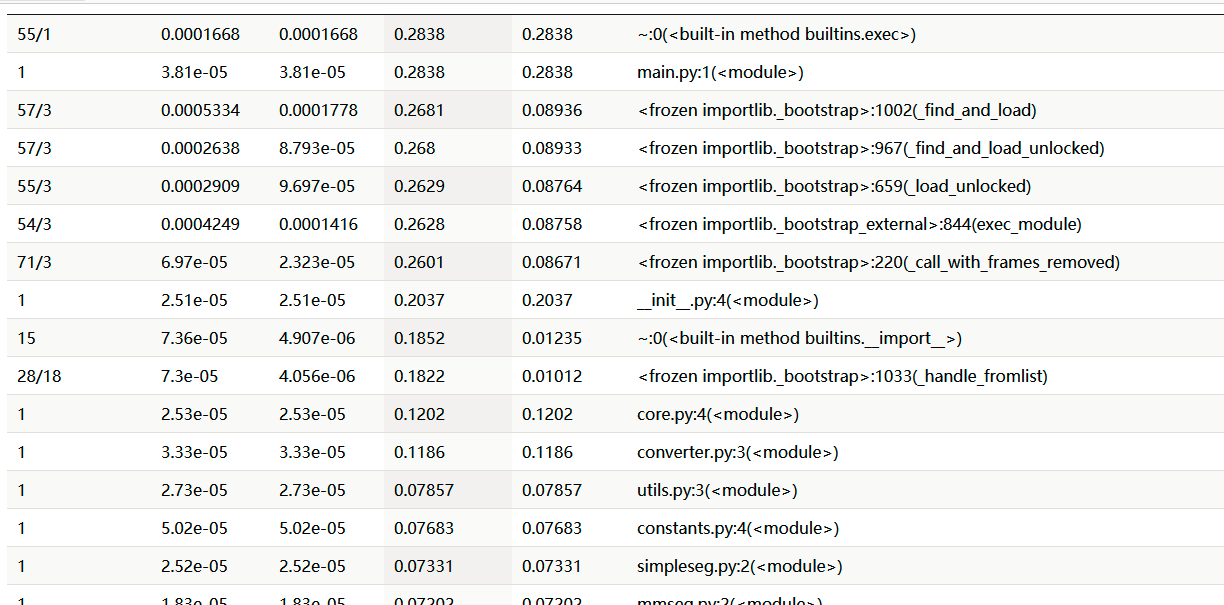
- cprofile,安装了snakeviz,可以清晰看见main函数占了大多时间,调用第三方pinyin库并没有十分耗时

2.3 计算模块部分单元测试展示
写unitest
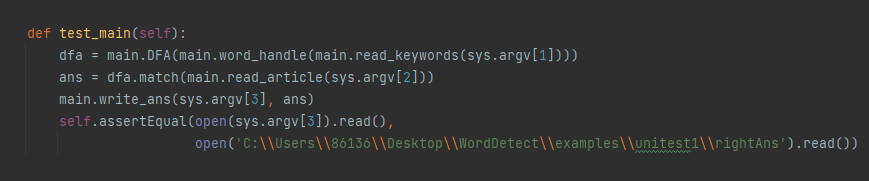
敏感词1
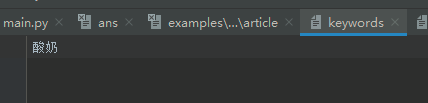
待查文本1

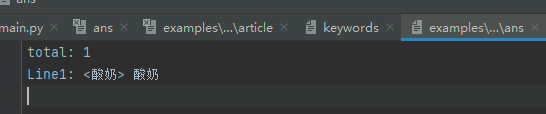
输出正确答案1
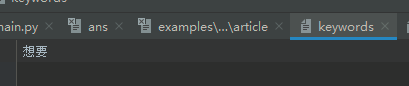
敏感词2
待查文本2
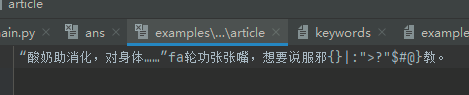
答案2

2.4 计算模块部分异常处理说明
在文件的输入输出函数上增加了异常捕捉处理

三、心得
- 在写代码前一定要预留出足够的时间去思考需要完成什么、需要学什么、怎么调试,并且题目一定一定一定要看清楚,不然可能会出现急头白脸看了一堆资料、写了一堆东西结果没用的情况。
- 而本次实验对我来说比较难,参考了好多教程、代码,用了好多不同的方式才勉强出来一部分。但是即便花了不少精力,还是没能来得及,反思了下,原因应该是没有客观合理地预料这一周需要完成的各种事务,以至于没能预留出足够的时间在这个项目上,导致哪怕快通宵了还是没能完成。不过这才是第一次,希望吸取了经验教训后将来能有所进步。
- 关于代码,我这次由于急迫写得太乱,很多功能不同的部分没能很好地分离开来,也没有设置一些合理的接口,导致代码可读性很差,复查时阅读很困难。但这都是经验教训,下次的作业会尽力克服掉这些不足的。
