python爬虫2-HTML文本处理
HTML文本处理
re模式匹配
正则表达式是一种强大的字符串匹配和处理工具,允许通过指定的模式来查找、替换和验证字符串。
函数
编译正则表达式
re.compile(pattern, flags=0): 将字符串形式的正则表达式编译为一个正则对象,用于后续的匹配操作。
匹配操作
re.match(pattern, string, flags=0): 从字符串的起始位置匹配模式。re.search(pattern, string, flags=0): 扫描整个字符串,并返回第一个成功的匹配。re.findall(pattern, string, flags=0): 返回字符串中所有与模式匹配的子串列表。re.finditer(pattern, string, flags=0): 返回一个迭代器,每次迭代返回一个匹配对象。re.fullmatch(pattern, string, flags=0): 如果整个字符串与模式匹配,则返回一个匹配对象,否则返回None。
替换操作
re.sub(pattern, repl, string, count=0, flags=0): 将字符串中与模式匹配的部分替换为指定的字符串。re.subn(pattern, repl, string, count=0, flags=0): 类似于sub,但返回一个元组(new_string, number_of_subs_made)。
分割操作
re.split(pattern, string, maxsplit=0, flags=0): 根据模式分割字符串,返回分割后的子串列表。
正则表达式修饰符
re.IGNORECASE(或re.I): 忽略大小写匹配。re.MULTILINE(或re.M): 多行匹配。re.DOTALL(或re.S): 让.匹配包括换行符在内的所有字符。re.VERBOSE(或re.X): 可以使用空格和注释来组织正则表达式。
示例
下面是一个简单的示例,展示如何使用正则表达式模块进行匹配和替换操作:
import re
# 示例文本
text = 'Hello, my email is john.doe@example.com. Please contact me.'
# 定义匹配邮箱地址的正则表达式模式,使用命名组
pattern = r'(?P<username>[\w\.-]+)@(?P<domain>[a-zA-Z\d\.-]+)\.(?P<tld>[a-zA-Z]{2,})'
emails = re.findall(pattern, text)
print(emails)
# [('john.doe', 'example', 'com')]
# 替换的新域名
new_domain = 'qq.com'
# 使用 re.sub() 替换匹配的邮箱地址,并保留原用户名和顶级域名
new_text = re.sub(pattern, fr'\g<username>@{new_domain}', text)
print(new_text)
# Hello, my email is john.doe@qq.com. Please contact me.
(?P<username>[\w\.-]+): 命名组 <username>,匹配一个或多个字母、数字、下划线、点号或破折号,用于表示电子邮件地址中的用户名部分。
@: 匹配电子邮件地址中的 @ 符号。
(?P<domain>[a-zA-Z\d\.-]+): 命名组 <domain>,匹配一个或多个字母、数字、破折号或点号,用于表示电子邮件地址中的域名部分。
\.(?P<tld>[a-zA-Z]{2,}): 匹配顶级域名(TLD),用于表示电子邮件地址中的顶级域名部分。
fr'\g<username>@{new_domain}': 在 re.sub() 中使用 \g<username> 来引用命名组 <username> 的内容,然后在替换字符串中使用 {new_domain} 替换原来的域名部分。
豆瓣数据
- 获取网页并保存
import requests
url = 'https://movie.douban.com/top250'
header = {
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
reponse = requests.get(url,headers=header)
reponse.encoding = "utf-8"
with open('douban.html', 'w', encoding='utf-8') as fp:
fp.write(reponse.text)
- 正则匹配,并保存为csv文件
import re
import csv
# 打开并读取文件
with open('douban.html', 'r', encoding='utf-8') as file:
content = file.read()
# 匹配模式
obj = re.compile(r'<span class="title">(?P<name>.*?)</span>.*?<p class="">.*?<br>.*?'
r'(?P<year>\d+) .*?<span class="rating_num" property="v:average">(?P<rating>.*?)</span>',re.S)
# 使用 re.findall() 找到所有匹配的信息
result = obj.finditer(content)
# 保存找到的信息到CSV文件
with open('douban.csv', 'w', newline='', encoding='utf-8') as csvfile:
csvwriter = csv.writer(csvfile)
for it in result:
dic = it.groupdict()
csvwriter.writerow(dic.values())
# 使用 re.findall() 找到所有匹配的信息
result = obj.finditer(content)
# 匹配到的信息
for it in result:
print(it.group("name"))
print(it.group("year"))
print(it.group("rating"))
bs4
Beautiful Soup(简称 bs4)是一个用于解析 HTML 和 XML 文件的 Python 库。它能够方便地从网页中提取数据,特别是结合其他库如 requests 进行网页抓取时。
find_all函数
find_all方法用于查找文档中所有符合条件的元素。它返回一个包含所有匹配元素的列表。
语法
soup.find_all(name, attrs, recursive, string, limit, **kwargs)
name: 标签名,字符串类型或列表类型。如'a'或['a', 'b']。attrs: 属性,字典类型。如{'class': 'link'}。recursive: 布尔类型,默认值为True,表示是否递归查找子标签。string: 用于查找包含特定字符串的标签。limit: 整数类型,限制返回的结果数量。**kwargs: 其他属性,直接作为关键字参数传入。
示例
from bs4 import BeautifulSoup
html_content = '''
<!DOCTYPE html>
<html>
<head>
<title>Sample Page</title>
</head>
<body>
<h1>Welcome to the Sample Page</h1>
<p class="description">This is a simple HTML file for demonstration purposes.</p>
<div class="content">
<p>Here is some sample content.</p>
<a href="https://www.example.com">Example Link</a>
<a href="https://www.anotherexample.com">Another Example Link</a>
</div>
</body>
</html>
'''
# 传入文本并解析为html
soup = BeautifulSoup(html_content, 'html.parser')
# 找到所有 <a> 标签
links = soup.find_all('a')
for link in links:
print('链接文本:', link.text)
print('URL:', link['href'])
# 运行结果
'''
链接文本: Example Link
URL: https://www.example.com
链接文本: Another Example Link
URL: https://www.anotherexample.com
'''
find函数
find方法用于查找文档中第一个符合条件的元素。它返回单个元素。
语法
soup.find(name, attrs, recursive, string, **kwargs)
name: 标签名,字符串类型或列表类型。如'a'或['a', 'b']。attrs: 属性,字典类型。如{'class': 'link'}。recursive: 布尔类型,默认值为True,表示是否递归查找子标签。string: 用于查找包含特定字符串的标签。**kwargs: 其他属性,直接作为关键字参数传入。
示例
from bs4 import BeautifulSoup
html_content = '''
<!DOCTYPE html>
<html>
<head>
<title>Sample Page</title>
</head>
<body>
<h1>Welcome to the Sample Page</h1>
<p class="description">This is a simple HTML file for demonstration purposes.</p>
<div class="content">
<p>Here is some sample content.</p>
<a href="https://www.example.com">Example Link</a>
<a href="https://www.anotherexample.com">Another Example Link</a>
</div>
</body>
</html>
'''
# 传入文本并解析为html
soup = BeautifulSoup(html_content, 'html.parser')
# 找到第一个 <a> 标签
first_link = soup.find('a')
if first_link:
print('第一个链接文本:', first_link.text)
print('URL:', first_link['href'])
# 运行结果
'''
第一个链接文本: Example Link
URL: https://www.example.com
'''
豆瓣数据
获取网页并保存
import requests
url = 'https://movie.douban.com/top250'
header = {
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
reponse = requests.get(url,headers=header)
reponse.encoding = "utf-8"
with open('douban.html', 'w', encoding='utf-8') as fp:
fp.write(reponse.text)
bs4处理,并保存为csv文件
from bs4 import BeautifulSoup
import re
import csv
with open('douban.html', 'r', encoding='utf-8') as file:
html_content = file.read()
# 解析 HTML 内容
soup = BeautifulSoup(html_content, 'html.parser')
# 标题
ol_grid_view = soup.find('ol', class_="grid_view")
span_title = ol_grid_view.find_all('span',class_="title")
# 过滤英文
name = []
for title in span_title:
if '/' not in title.text:
name.append(title.text)
# 年份
year = []
div_bd = ol_grid_view.find_all('div',class_="bd")
ps = []
for div in div_bd:
ps.append(div.find_all('p',class_="")[0])
for p in ps:
pattern = r'\b\d{4}\b'
matches = re.findall(pattern, p.text)
year.append(matches[0])
# 评分
rating = []
span_rating = ol_grid_view.find_all('span',class_="rating_num")
for rat in span_rating:
rating.append(rat.text)
# 保存找到的信息到CSV文件
with open('douban2.csv', 'w', newline='', encoding='utf-8') as csvfile:
csvwriter = csv.writer(csvfile)
# 使用 zip 将三个列表合并成一个字典
dic = zip(name, year, rating)
for v1, v2, v3 in dic:
csvwriter.writerow([v1, v2, v3])
xpath
lxml是一个强大的 Python 库,用于处理 XML 和 HTML 数据
基本路径表达式
以下是一些基本的 XPath 路径表达式示例:
- 选取节点:
/: 根节点//: 从当前节点选择所有后代节点.: 当前节点..: 父节点
- 选取具体节点:
/bookstore/book: 选取根元素 bookstore 下的所有 book 元素//title: 选取所有 title 元素//book[@category='cooking']: 选取所有 category 属性为 cooking 的 book 元素
- 选取节点的内容:
/bookstore/book/title/text(): 选取根元素 bookstore 下的所有 book 元素的 title 子元素的文本内容
路径获取
通过浏览器右键可以方便获取xpath路径
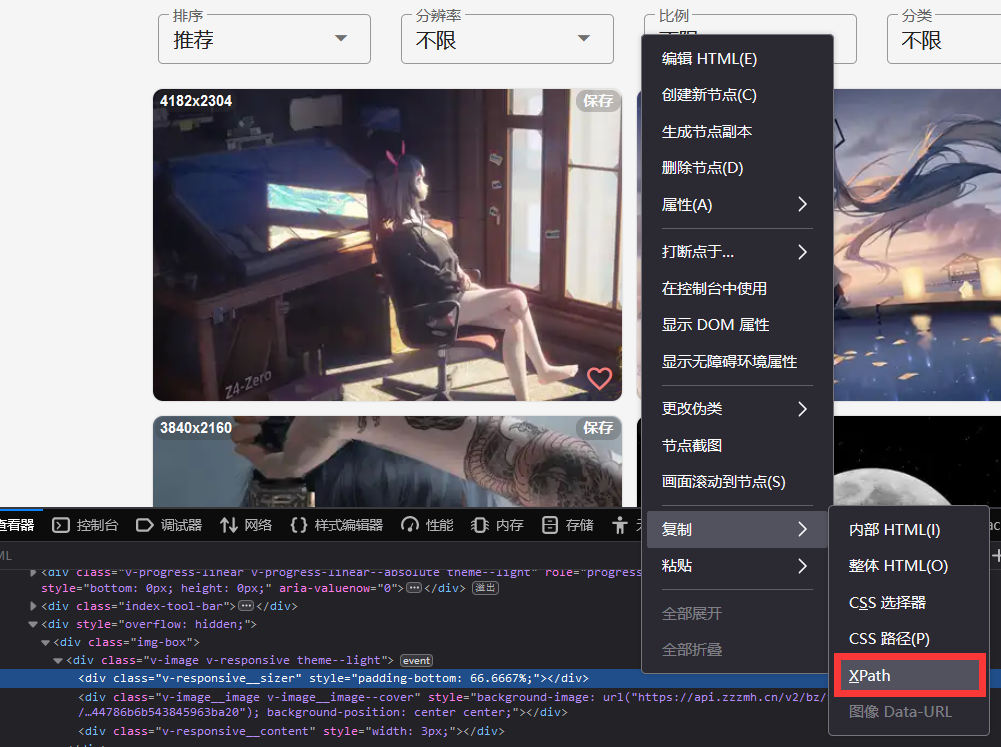
实例
from lxml import etree
# XML 文档字符串
xml_string = '''
<bookstore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
</book>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J.K. Rowling</author>
<year>2005</year>
</book>
</bookstore>
'''
# 解析 XML 字符串
root = etree.fromstring(xml_string)
# 使用 XPath 选取所有 title 元素的文本内容
titles = root.xpath('//title/text()')
# 打印所有 title 的文本内容
for title in titles:
print("书名:", title)
# 使用 XPath 选取category=cooking的作者名
authors = root.xpath("/bookstore/book[@category='cooking']/author/text()")
# 打印作者名字
for author in authors:
print("作者:",author)
豆瓣数据
获取网页并保存
import requests
url = 'https://movie.douban.com/top250'
header = {
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
reponse = requests.get(url,headers=header)
reponse.encoding = "utf-8"
with open('douban.html', 'w', encoding='utf-8') as fp:
fp.write(reponse.text)
lxml处理,并保存为csv文件
from lxml import etree
import re
import csv
# 打开并读取文件
with open('douban.html', 'r', encoding='utf-8') as file:
content = file.read()
# 解析 XML 字符串
root = etree.HTML(content)
# 使用 XPath 选取所有 title 元素的文本内容
lis = root.xpath('//*[@id="content"]/div/div[1]/ol/li')
# 打开csv文件
csvfile = open('douban3.csv', 'w', newline='', encoding='utf-8')
csvwriter = csv.writer(csvfile)
for li in lis:
name = li.xpath("./div/div[2]/div[1]/a/span[1]/text()")[0] #名字
year = li.xpath("./div/div[2]/div[2]/p[1]/text()[2]")[0] #年份
rating = li.xpath("./div/div[2]/div[2]/div/span[2]/text()")[0] #评分
year = re.findall(r'\b\d{4}\b', year)[0] #对年份进行处理
# 写入csv文件
csvwriter.writerow([name, year, rating])
# 关闭csv文件
csvfile.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号