
网易云爬虫教程
import requests #用于发起网络请求 from lxml import etree #解析数据 headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36' } # 请求头 #1、网易云音乐热歌榜页面地址 url = "https://music.163.com/discover/toplist?id=3778678" # 2、通过网址进入网站获取网页数据 response = requests.get(url,headers = headers) #print(response) #获取响应 # <Response [200]> 200是什么? 状态码 表示同意请求 #print(response.text) #获取网页的源代码 # 3、筛选想要的目标数据 data = etree.HTML(response.text) #获取网页源代码,并将源代码转化为能被xpath匹配的格式,此处HTML必须大写 music_list = data.xpath('//a[contains(@href,"/song?")]') #全文扫描查找符合指定条件的内容,并以列表的形式返回 # print(music_list) #查看返回的列表 # 4、列表进行拆分并显示 for music in music_list: href = music.xpath('./@href')[0] #上面返回的列表依然不是最终想要的,所以还需在当前节点下查找指定条件的内容 # print(href) music_id = href.split('=')[1] # 使用关键字split 从查找到的内容中截取自己想要的 music_name = music.xpath('./text()')[0] #获取当前节点下的文本内容(此处是获取歌曲的名字) print(music_id) url_base = "http://music.163.com/song/media/outer/url?id=" #定义下载接口 music = requests.get(url_base+music_id, headers = headers) #获取音乐 with open('./music/' + music_name + '.mp3', 'wb') as file: #保存音乐文件 file.write(music.content) print(music_name + '下载成功') #提示 # 爬取网易云音乐 # 1、首先获取网页的地址 # 2、通过关键requests向网页发起请求,请求通过后即可抓取网页的数据 # 3、解析数据(获取歌曲的ID):直接抓取到的数据通常不是我们想要的,这时候就需要通过etree来进行数据解析,这个过程中通常会用到关键字 # xpath(xpath详细讲解:https://www.cnblogs.com/it-tsz/p/8899161.html)。XPath 是一门在 XML 文档中查找信息的语言。 # XPath 可用来在 XML 文档中对元素和属性进行遍历。 # xpath常见的几种使用方法: # 1) // 双斜杠 定位根节点,会对全文进行扫描,在文档中选取所有符合条件的内容,以列表的形式返回。 # 2) / 单斜杠 寻找当前标签路径的下一层路径标签或者对当前路标签内容进行操作 # 3) /text() 获取当前路径下的文本内容 # 4) /@xxxx 提取当前路径下标签的属性值 # 5) | 可选符 使用|可选取若干个路径 如//p | //div 即在当前路径下选取所有符合条件的p标签和div标签。 # 6) . 点 用来选取当前节点 # 7) .. 双点 选取当前节点的父节点 # 代码中的第23行使用的就是第4和第6种方法来获取当前路径当前节点下标签的属性值的。 # 4、第29行:将歌曲的下载链接赋值给一个变量 # 5、第31行:将获取到的歌曲ID置于下载链接的末端,从而下载歌曲 # 6、第33、34行:使用open函数将下载的歌曲以二进制写入的方式保存到music 文件夹中,每首歌曲以获取的歌曲名命名,保存为 # MP3的格式,注意此处的music文件夹需手动在脚本所在目录下创建 # 7、每首歌曲下载成功后会以“歌名+下载成功”的方式提示
其实大方向就3步:
1、对网页发出请求(请求通过)
2、获取歌曲ID(将网页源代码转换成xpath匹配的格式,从中查找到歌曲ID)
3、将歌曲ID置于下载链接中下载歌曲
可能模糊的地方:
1、解析数据时指定数据的位置
进去网页,打开网页代码(Elements),然后按下图操作
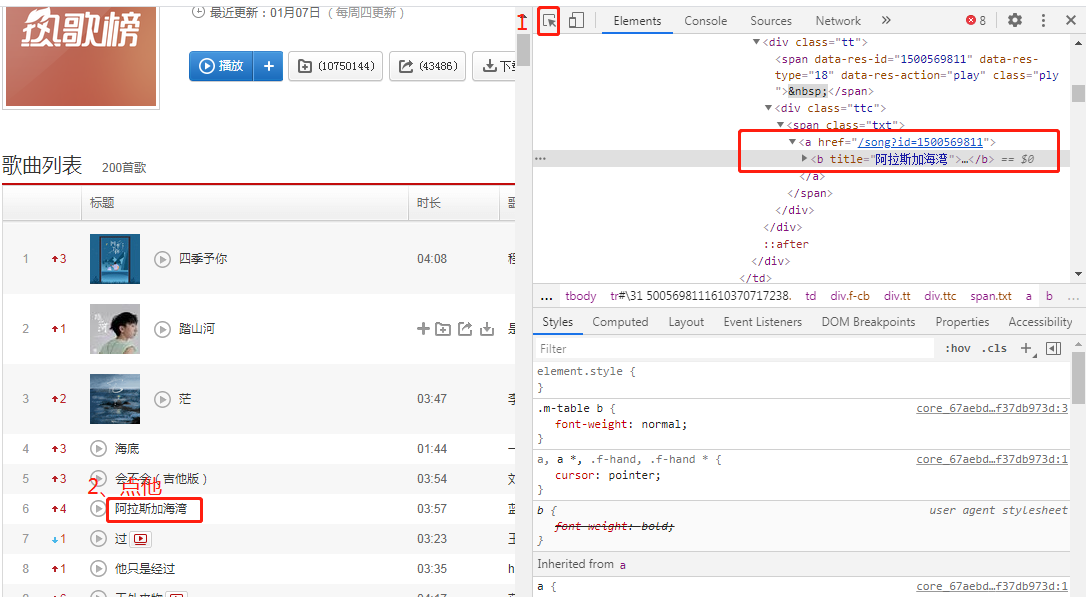
2、请求头的获取
按ctrl + r
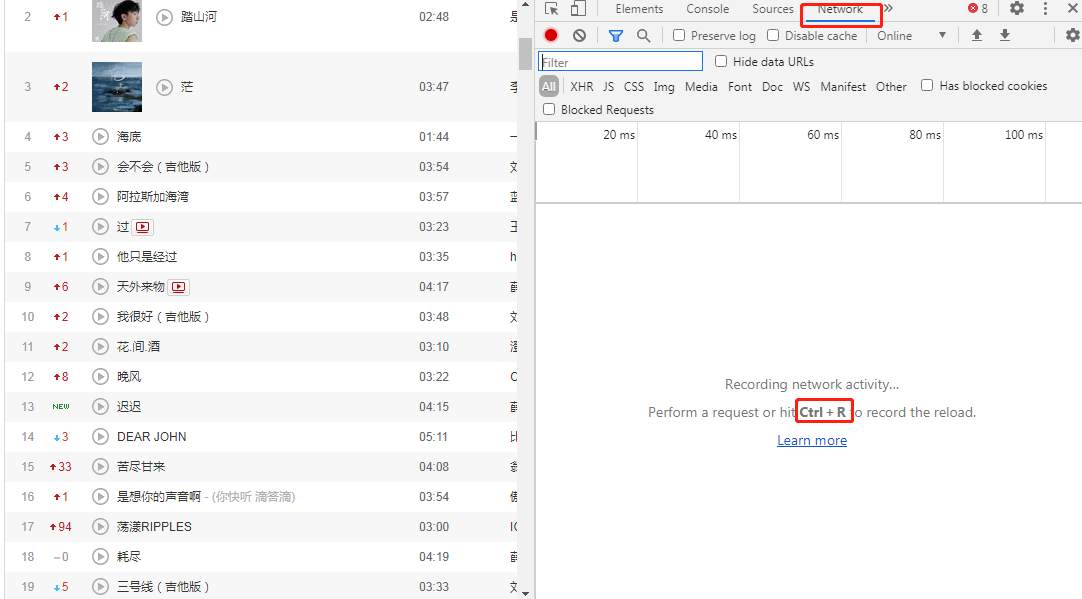
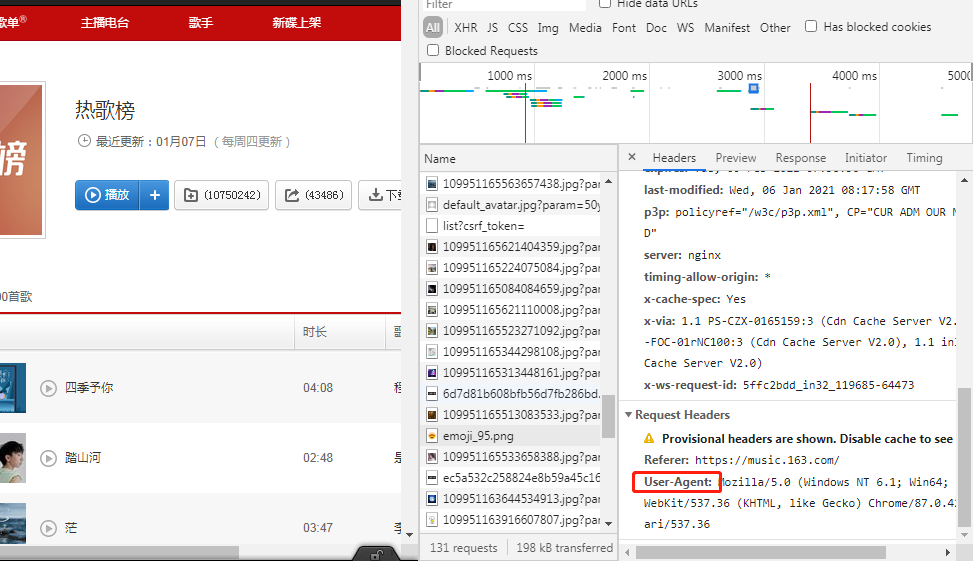
找到user-agent:将后面的内容复制到代码中
贵有恒,何必三更睡五更起最是无用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号