


监督学习:
回归:就是从无限多个可能的书中预测出一个数
分类:
非监督学习:
聚类算法(clustering):例如将某种有检测有病和没有病碱性无监督的分类。结果聚集到判断是有病还是没有病,也就是将相似的点聚集到一块
异常检测(anomaly detection):用于监测异常事件
降维(dimensionality reduction):它能帮组一个大的数据集压缩成一个小的数据集,同时丢失尽可能少的数据集
线性回归模型:是一种特殊的监督学习,因为他可以输出数字
分类模型:分类模型预测类别或离散类别
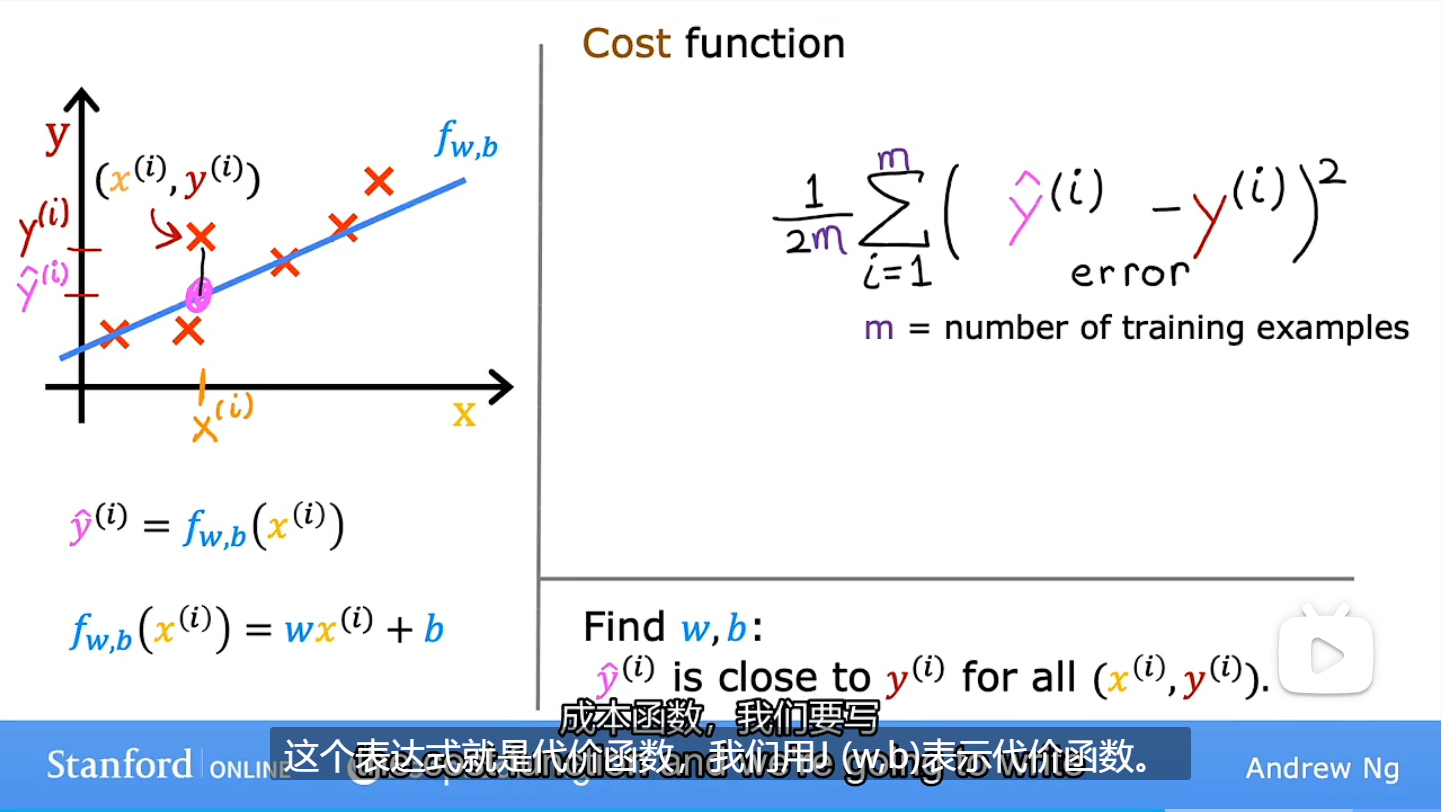
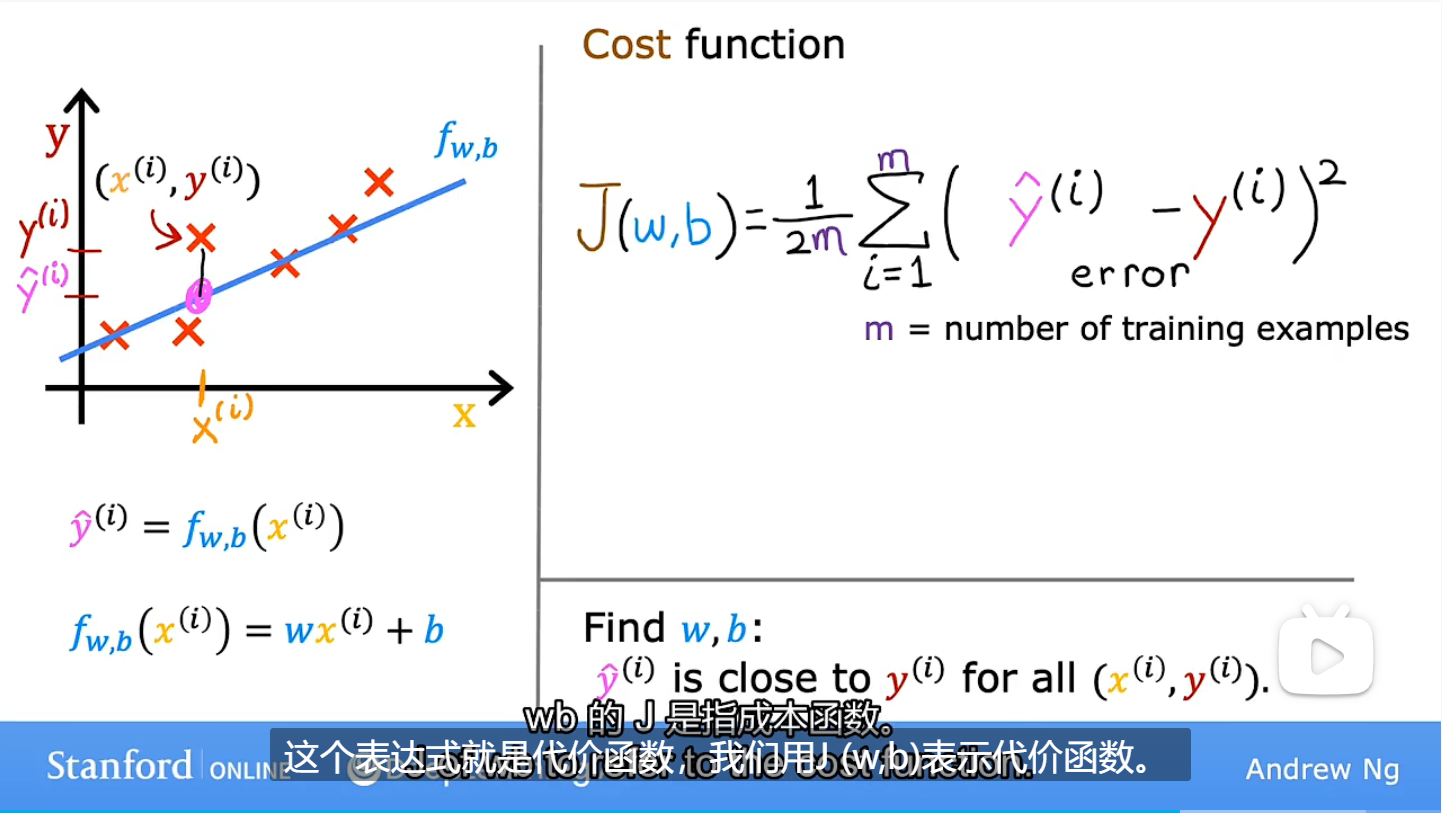
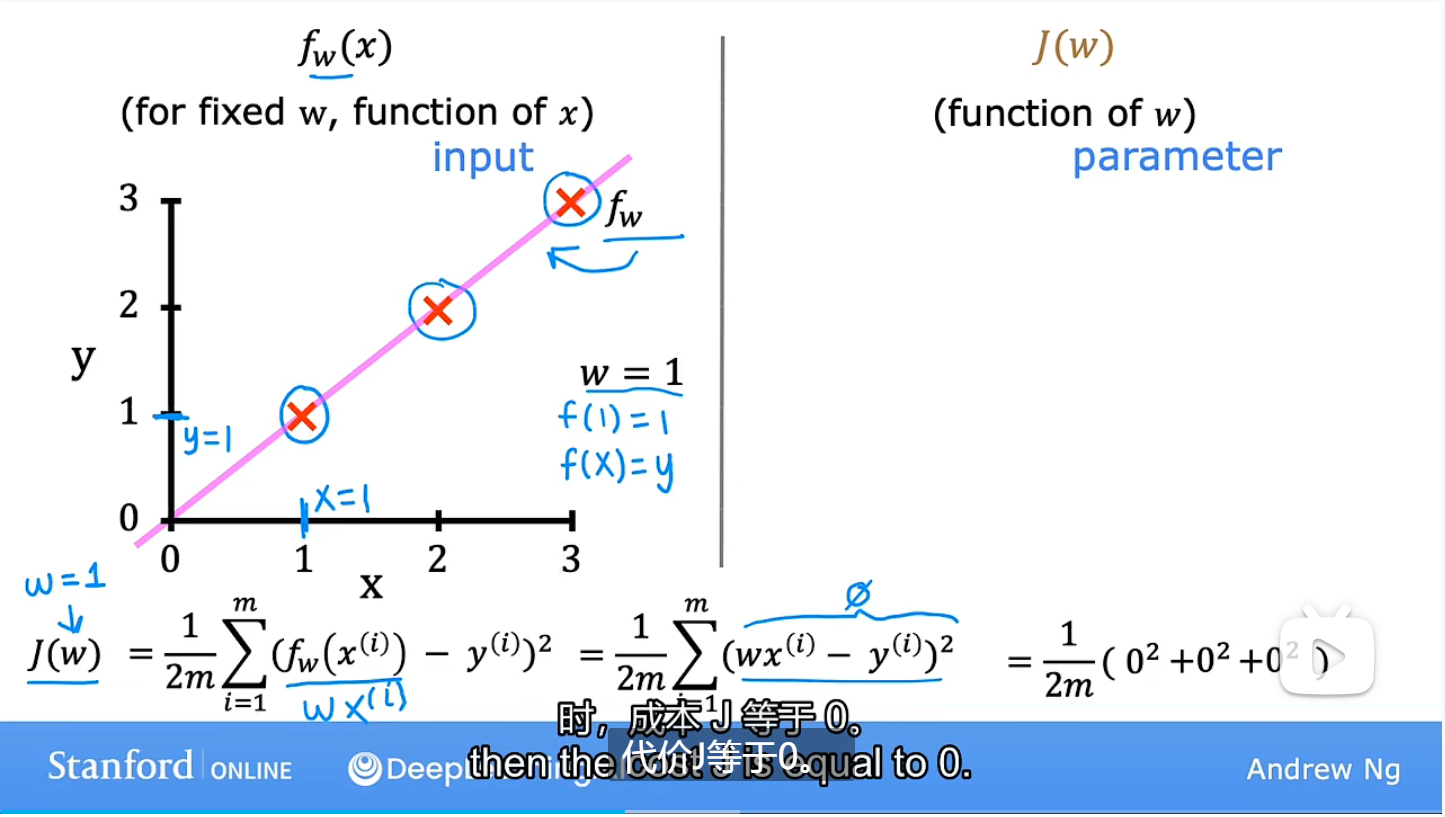
为了衡量w和b的选择与训练数据的吻合程度,需要使用到代价函数J,当w=1时,J为0,是一条经过原点的直线,也就是代价函数最小的时候
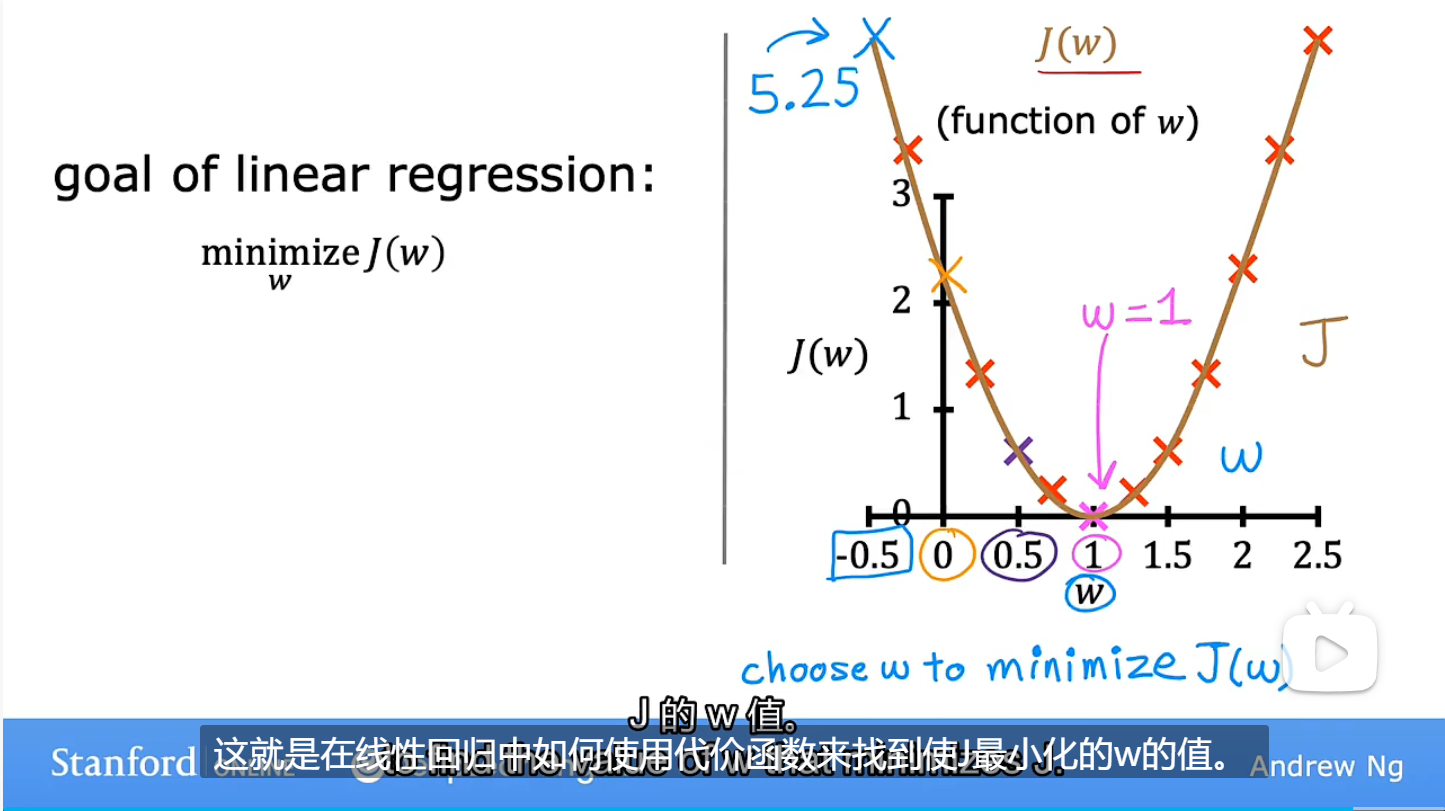
梯度下降算法:机器学习中非常重要的算法


SKlearn简介
scikit-learn,又写作sklearn,是一个开源的基于python语言的机器学习工具包。它通过NumPy, SciPy和Matplotlib等python数值计算的库实现高效的算法应用,并且涵盖了几乎所有主流机器学习算法。
SKlearn官网:scikit-learn: machine learning in Python
在工程应用中,用python手写代码来从头实现一个算法的可能性非常低,这样不仅耗时耗力,还不一定能够写出构架清晰,稳定性强的模型。更多情况下,是分析采集到的数据,根据数据特征选择适合的算法,在工具包中调用算法,调整算法的参数,获取需要的信息,从而实现算法效率和效果之间的平衡。而sklearn,正是这样一个可以帮助我们高效实现算法应用的工具包。

sklearn有一个完整而丰富的官网,里面讲解了基于sklearn对所有算法的实现和简单应用。
常用模块
sklearn中常用的模块有分类、回归、聚类、降维、模型选择、预处理。
分类:识别某个对象属于哪个类别,常用的算法有:SVM(支持向量机)、nearest neighbors(最近邻)、random forest(随机森林),常见的应用有:垃圾邮件识别、图像识别。
回归:预测与对象相关联的连续值属性,常见的算法有:SVR(支持向量机)、 ridge regression(岭回归)、Lasso,常见的应用有:药物反应,预测股价。
聚类:将相似对象自动分组,常用的算法有:k-Means、 spectral clustering、mean-shift,常见的应用有:客户细分,分组实验结果。
降维:减少要考虑的随机变量的数量,常见的算法有:PCA(主成分分析)、feature selection(特征选择)、non-negative matrix factorization(非负矩阵分解),常见的应用有:可视化,提高效率。
模型选择:比较,验证,选择参数和模型,常用的模块有:grid search(网格搜索)、cross validation(交叉验证)、 metrics(度量)。它的目标是通过参数调整提高精度。
预处理:特征提取和归一化,常用的模块有:preprocessing,feature extraction,常见的应用有:把输入数据(如文本)转换为机器学习算法可用的数据。
安装SKlearn
安装最新版本
Scikit-learn需要:
•Python(> = 2.7或> = 3.4),
•NumPy(> = 1.8.2),
•SciPy(> = 0.13.3)。
【注意】Scikit-learn 0.20是支持Python 2.7和Python 3.4的最后一个版本。Scikit-learn 0.21将需要Python 3.5或更高版本。
如果你已经安装了numpy和scipy,那么安装scikit-learn的最简单方法就是使用 pip或者canda
pip install -U scikit-learn
conda install scikit-learn
如果你尚未安装NumPy或SciPy,你也可以使用conda或pip安装它们。使用pip时,请确保使用binary wheels,并且不会从源头重新编译NumPy和SciPy,这可能在使用特定配置的操作系统和硬件(例如Raspberry Pi上的Linux)时发生。从源代码构建numpy和scipy可能很复杂(特别是在Windows上),需要仔细配置以确保它们与线性代数例程的优化实现相关联。为了方便,我们可以使用如下所述的第三方发行版本。
发行版本
如果你还没有numpy和scipy的python安装,我们建议你通过包管理器或通过python bundle安装。它们带有numpy,scipy,scikit-learn,matplotlib以及许多其他有用的科学和数据处理库。
可用选项包括:Canopy和Anaconda适用于所有支持的平台
除了用于Windows,Mac OSX和Linux的大量科学python库之外,Canopy和Anaconda都提供了最新版本的scikit-learn。
Anaconda提供scikit-learn作为其免费发行的一部分。
【注意】PIP和conda命令不要混用!!!
要升级或卸载scikit-learn安装了python或者conda你不应该使用PIP命令。
升级scikit-learn:conda update scikit-learn
卸载scikit-learn:conda remove scikit-learn
使用pip install -U scikit-learn安装或者使用pip uninstall scikit-learn卸载可能都没有办法更改有conda命令安装的sklearn。
算法选择
sklearn 实现了很多算法,面对这么多的算法,如何去选择呢?其实选择的主要考虑的就是需要解决的问题以及数据量的大小。sklearn官方提供了一个选择算法的引导图。
这里提供翻译好的中文版本,供大家参考:
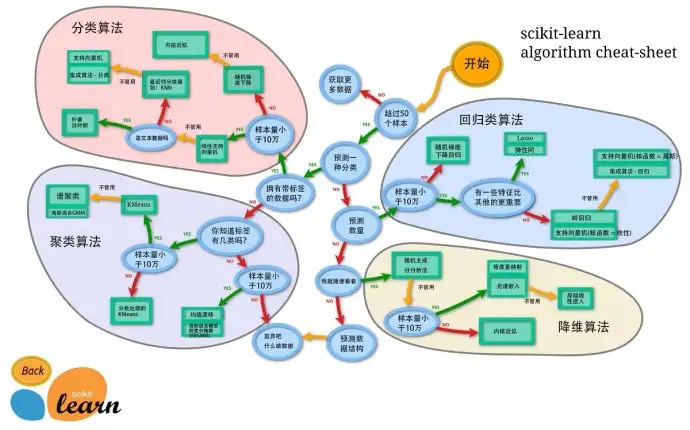
机器学习之决策树在sklearn中的实现
小伙伴们大家好~o( ̄▽ ̄)ブ,首先声明一下,我的开发环境是Jupyter lab,所用的库和版本大家参考:
Python 3.7.1(你的版本至少要3.4以上
Scikit-learn 0.20.0 (你的版本至少要0.20
Graphviz 0.8.4 (没有画不出决策树哦,安装代码conda install python-graphviz
Numpy 1.15.3, Pandas 0.23.4, Matplotlib 3.0.1, SciPy 1.1.0
用SKlearn 建立一棵决策树
这里采用的数据集是SKlearn中的红酒数据集。
1 导入需要的算法库和模块
<pre spellcheck="false" class="md-fences md-end-block ty-contain-cm modeLoaded" lang="Python" contenteditable="true" cid="n11" mdtype="fences" >from sklearn import tree #导入tree模块
from sklearn.datasets import load_wine #导入红酒数据集
from sklearn.model_selection import train_test_split #导入训练集和测试集切分包</pre>
2 探索数据
<pre spellcheck="false" class="md-fences md-end-block ty-contain-cm modeLoaded" lang="python " contenteditable="true" cid="n13" mdtype="fences" >wine = load_wine()
wine.data
wine.data.shape
wine.target
wine.target.shape</pre>
运行的结果是这样子的:
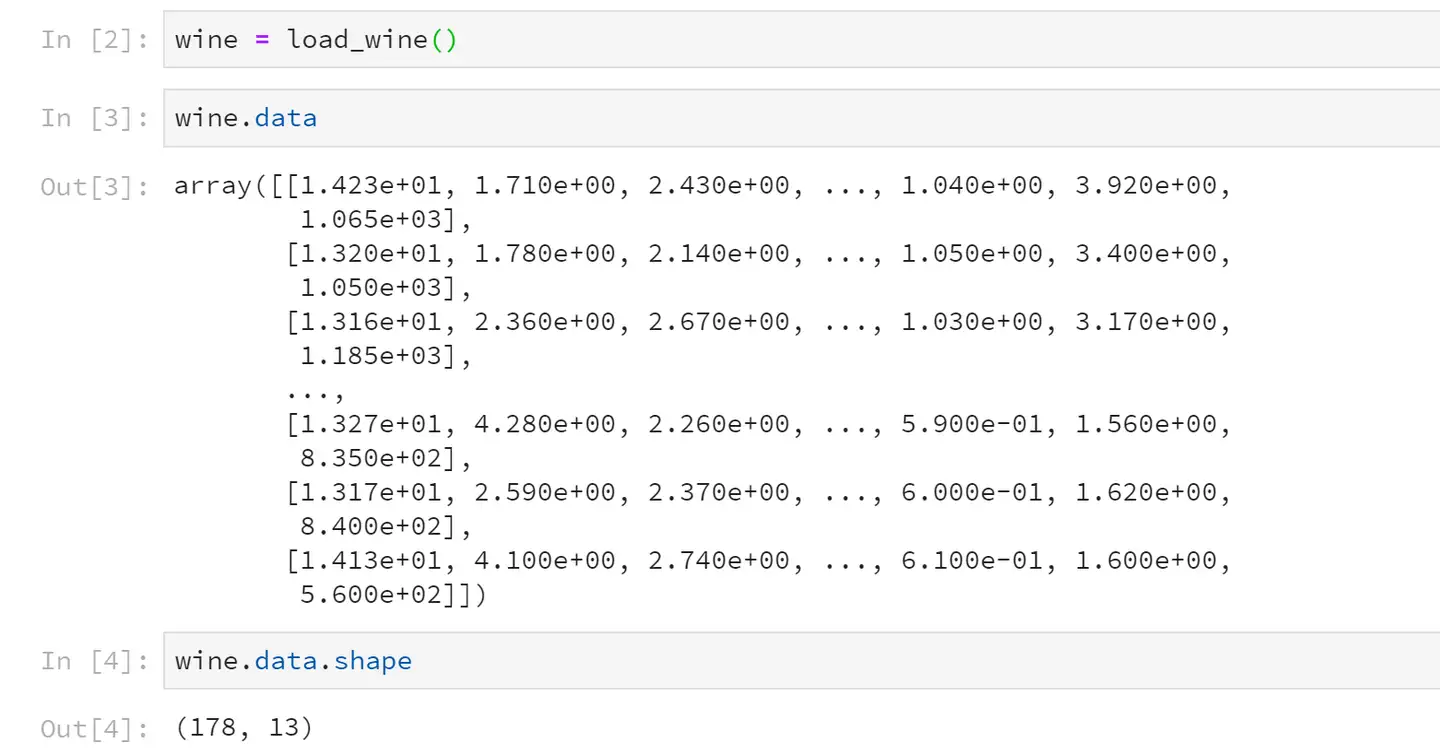
data就是该数据集的特征矩阵,从运行结果可以看出,该红酒数据集一共有178条记录,13个特征。
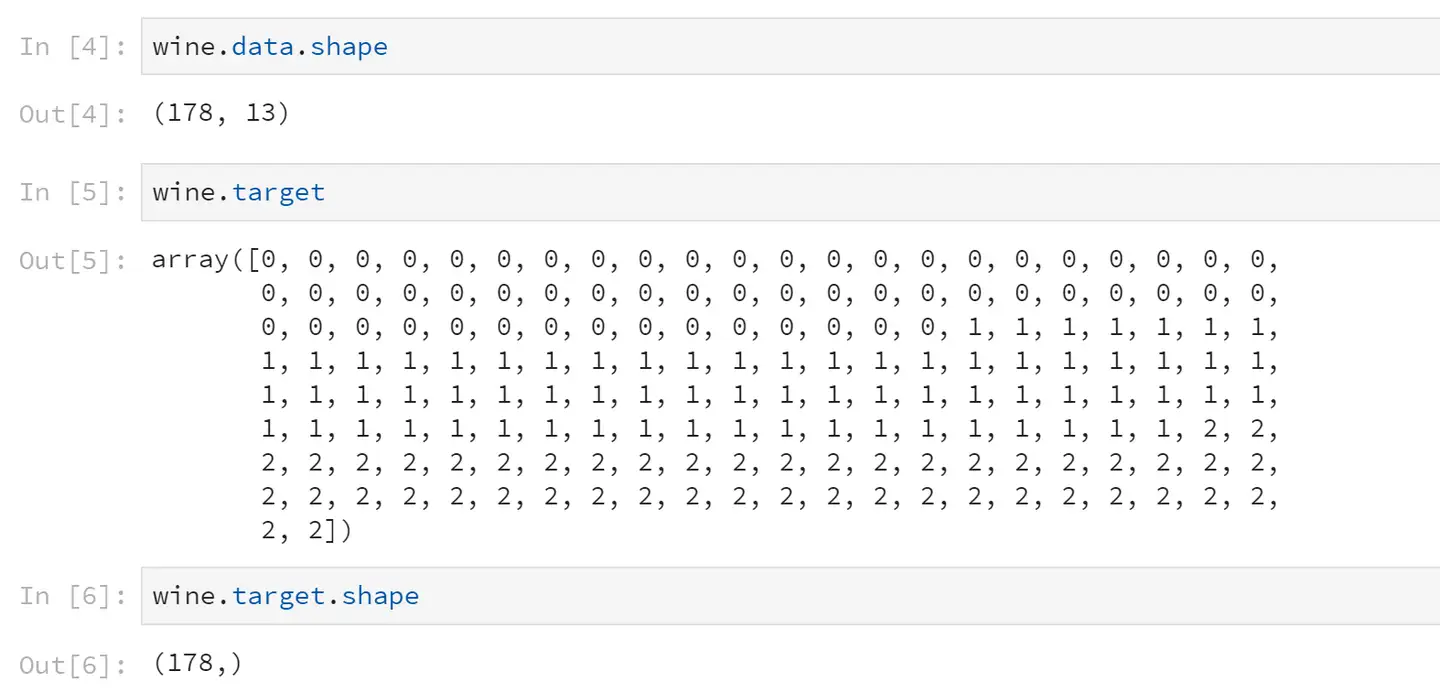
特征矩阵中有178条记录,相对应的标签Y就有178个数据。
如果wine是一张表,应该长这样:
<pre spellcheck="false" class="md-fences md-end-block ty-contain-cm modeLoaded" lang="Python" contenteditable="true" cid="n20" mdtype="fences" >import pandas as pd
pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)</pre>
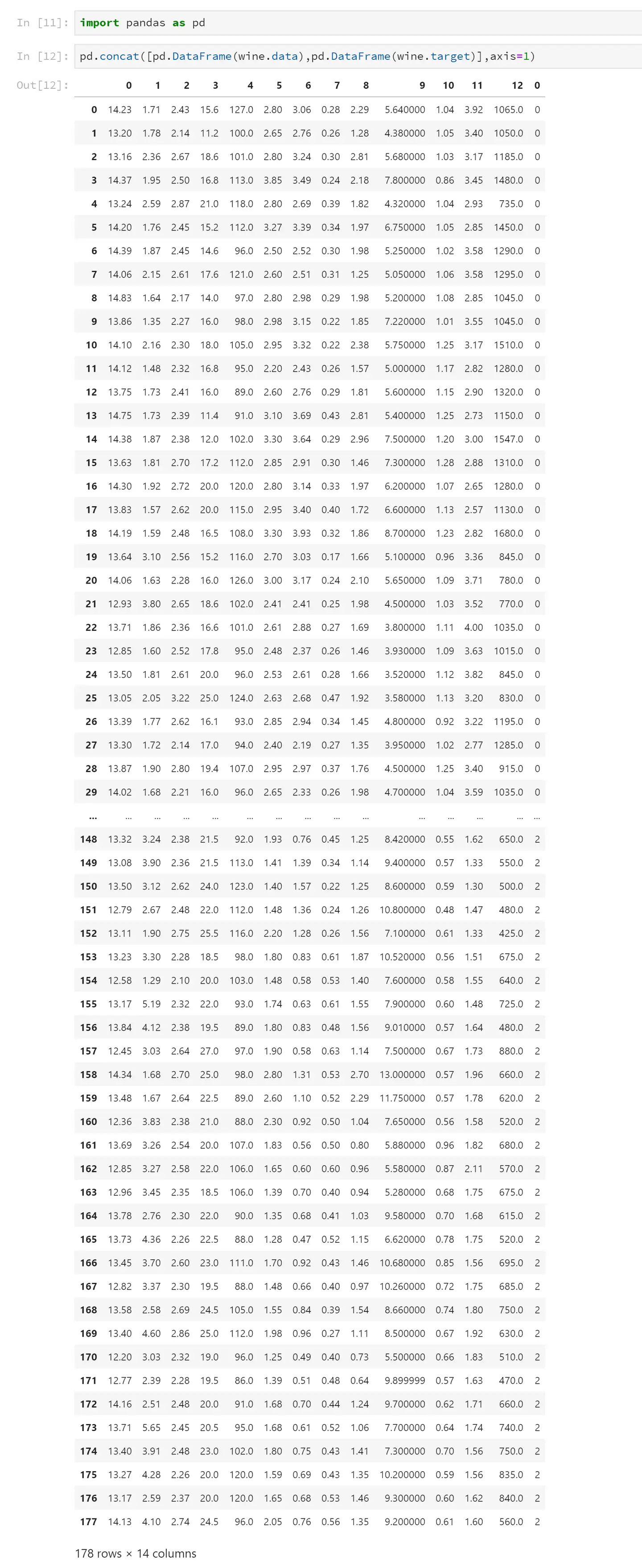
这是数据集特征列名和标签分类
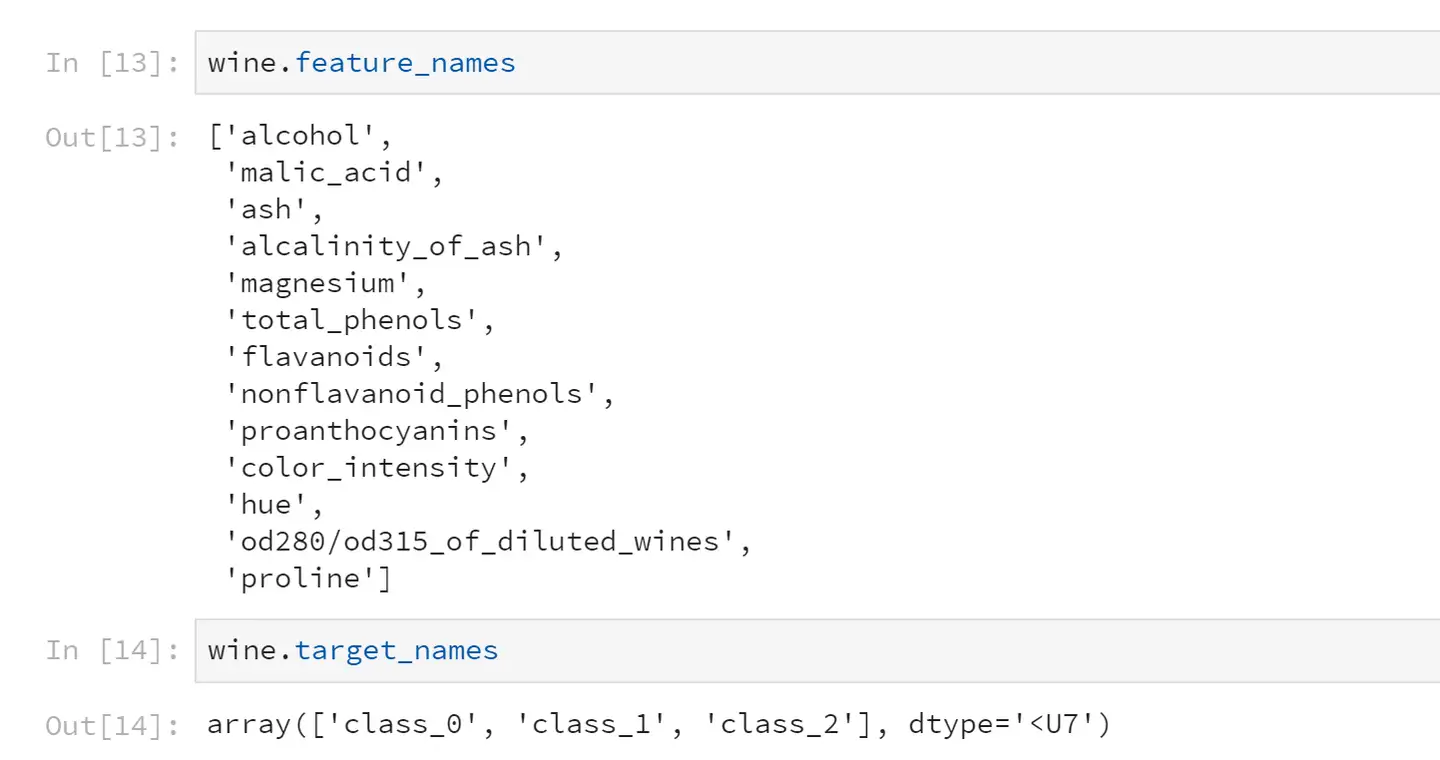
<pre spellcheck="false" class="md-fences md-end-block ty-contain-cm modeLoaded" lang="python" contenteditable="true" cid="n23" mdtype="fences" >wine.feature_names
wine.target_names</pre>
3 分训练集和测试集
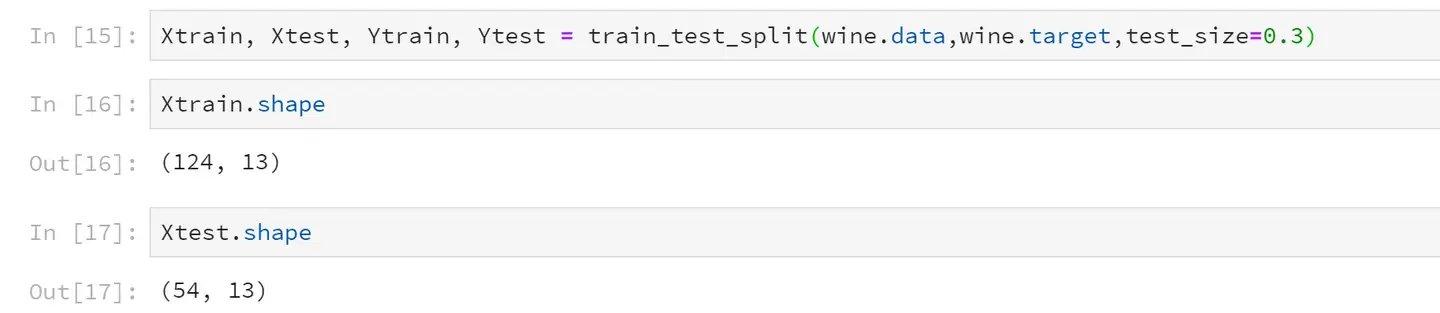
这里选取30%作为测试集。切分好之后,训练集有124条数据,测试集有54条数据。
<pre spellcheck="false" class="md-fences md-end-block ty-contain-cm modeLoaded" lang="Python" contenteditable="true" cid="n28" mdtype="fences" >Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
Xtrain.shape
Xtest.shape</pre>
4 建立模型
<pre spellcheck="false" class="md-fences md-end-block ty-contain-cm modeLoaded" lang="Python" contenteditable="true" cid="n32" mdtype="fences" >clf = tree.DecisionTreeClassifier(criterion="entropy") #初始化树模型
clf = clf.fit(Xtrain, Ytrain) #实例化训练集
score = clf.score(Xtest, Ytest) #返回预测的准确度
score</pre>

5 画出一棵树吧
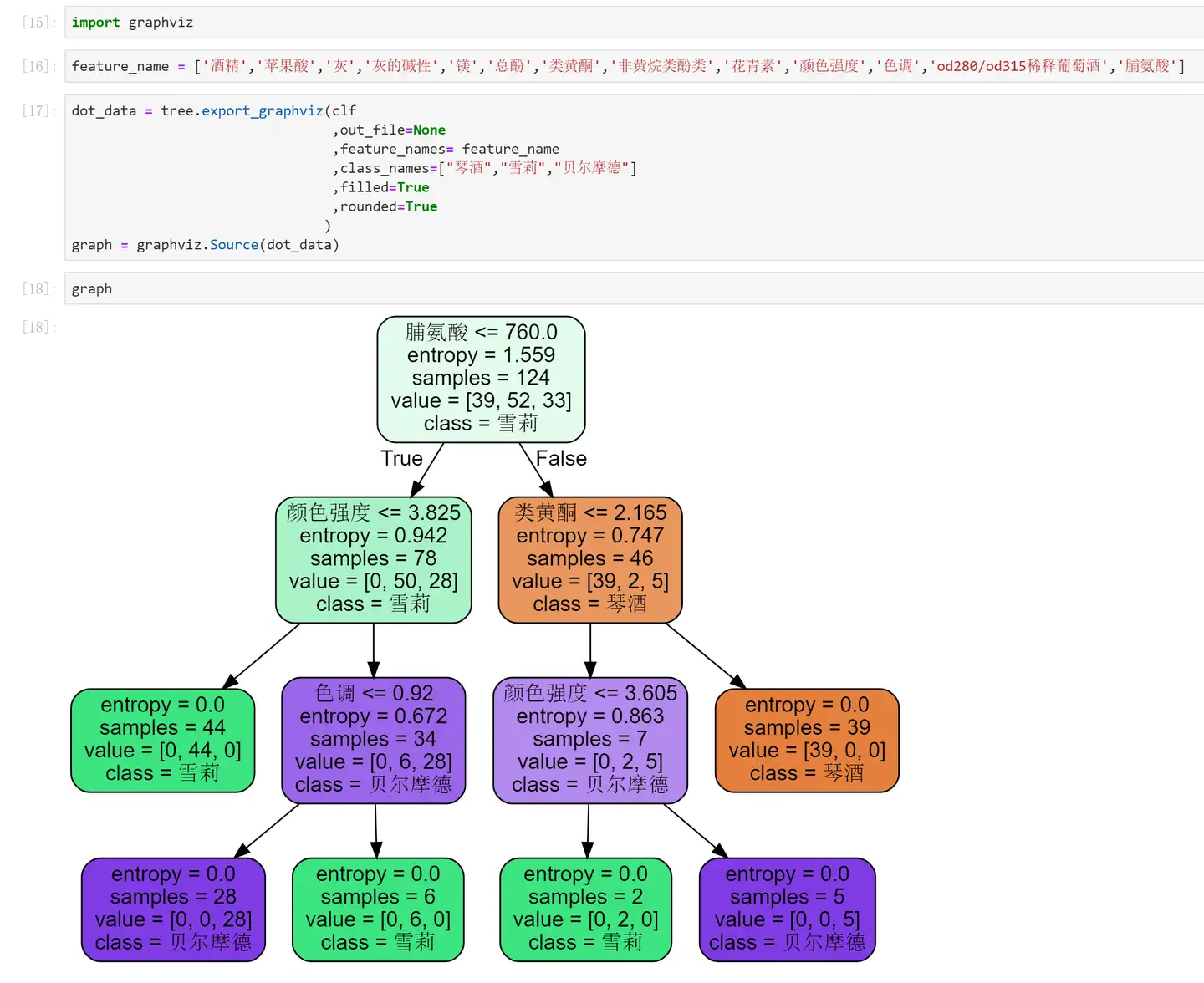
<pre spellcheck="false" class="md-fences md-end-block ty-contain-cm modeLoaded" lang="Python" contenteditable="true" cid="n36" mdtype="fences" >feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
import graphviz
dot_data = tree.export_graphviz(clf
,out_file=None
,feature_names= feature_name
,class_names=["琴酒","雪莉","贝尔摩德"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph</pre>
6 探索决策树
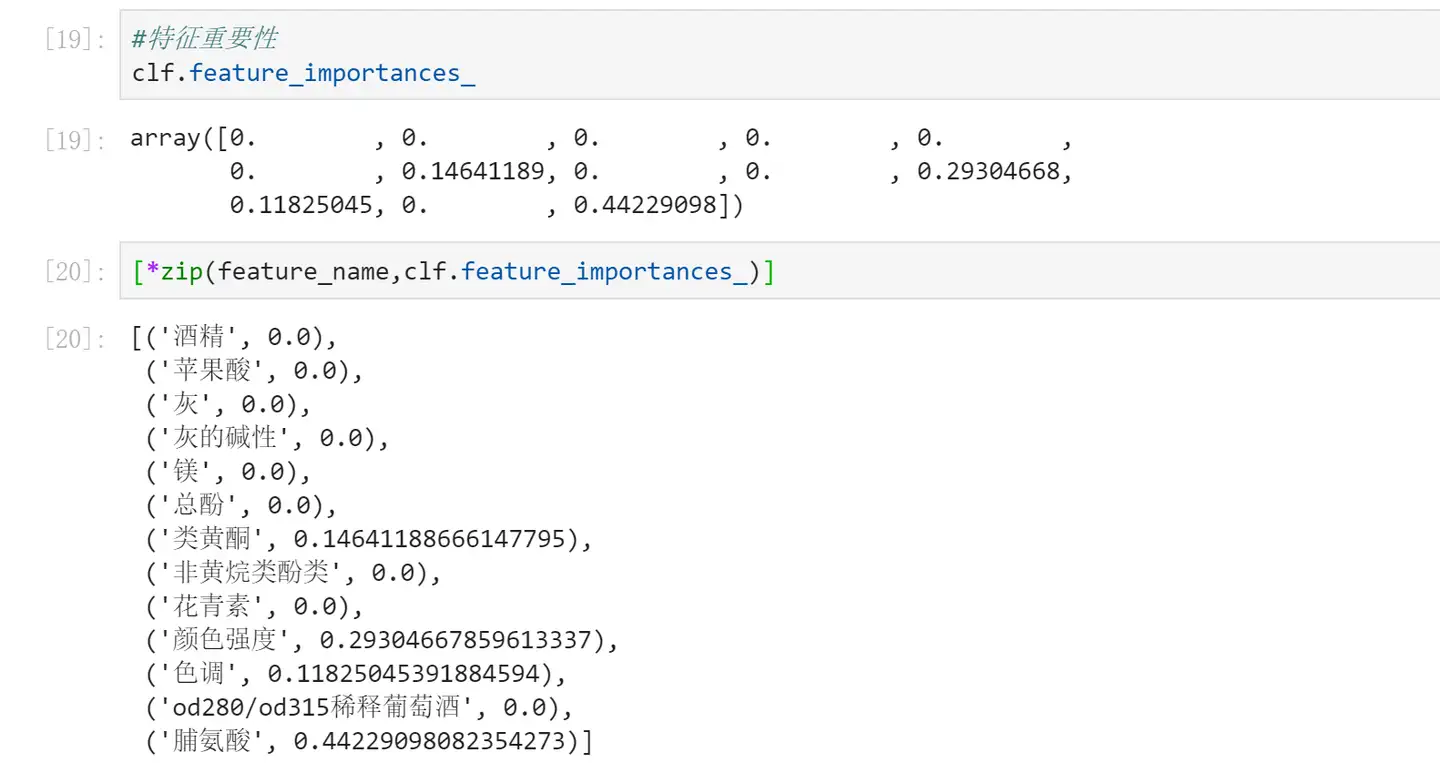
<pre spellcheck="false" class="md-fences md-end-block ty-contain-cm modeLoaded" lang="Python" contenteditable="true" cid="n40" mdtype="fences" >#特征重要性
clf.feature_importances_
[*zip(feature_name,clf.feature_importances_)]</pre>
到现在为止,我们已经学会建立一棵完整的决策树了。有兴趣的话,动手建立一棵属于自己的决策树吧~
ANN人工神经网络

人工神经网络使用非线性激活函数的原因
①. 神经网络用于实现复杂的函数,非线性激活函数可以使神经网络随意地逼近任意复杂函数
②. 而如果使用线性激活函数,网络每一层的输入都是上一层的线性输出,因此,无论该神经网络有多少层,最终输出都是输入的线性组合,与没有隐藏层的效果相当,这种情况就是最原始的感知机。并且还降低了效率。
③. 因此,才需要引入非线性函数作为激活函数,这样深层神经网络才有意义,输出不再是输入的线性组合,才可以逼近任意函数。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构