本文主要总结一下常用的nltk中的处理词语的几个函数以及词频计算和可视化。
1. concordance()
>>> from nltk.book import * >>> text1.concordance('monstrous') Displaying 11 of 11 matches: ong the former , one was of a most monstrous size . ... This came towards us , ON OF THE PSALMS . " Touching that monstrous bulk of the whale or ork we have r ll over with a heathenish array of monstrous clubs and spears . Some were thick d as you gazed , and wondered what monstrous cannibal and savage could ever hav that has survived the flood ; most monstrous and most mountainous ! That Himmal they might scout at Moby Dick as a monstrous fable , or still worse and more de th of Radney .'" CHAPTER 55 Of the Monstrous Pictures of Whales . I shall ere l ing Scenes . In connexion with the monstrous pictures of whales , I am strongly ere to enter upon those still more monstrous stories of them which are to be fo ght have been rummaged out of this monstrous cabinet there is no telling . But of Whale - Bones ; for Whales of a monstrous size are oftentimes cast up dead u
搜索某个特定词语在文章中出现的位置,这里nltk.text.Text类对象有该属性,list对象没有。
2. similar()
>>> from nltk.book import * >>> text1.similar('monstrous') imperial subtly impalpable pitiable curious abundant peril trustworthy untoward singular lamentable few determined ma horrible tyrannical lazy mystifying christian exasperate
搜索文章中与目标具有相同上下文的词,这里nltk.text.Text类对象有该属性,list对象没有。
3. common_contexts()
>>> from nltk.book import * >>> text2.common_contexts(['monstrous','very'] a_pretty is_pretty a_lucky am_glad be_glad
搜索list中词在文章中出现的共同的两个或两个以上的上下文,这里nltk.text.Text类对象有该属性,list对象没有。
4. 统计词汇
1)len(): 计算text, list等的长度
2)set(): 去掉list, text中的重复元素
3)sorted(): 将list, text中的元素按首字母排序
>>> ds ['you', 'i', 'love', 'meet', 'solve', 'drink'] >>> len(ds) 6 >>> set(ds) set(['love', 'i', 'drink', 'solve', 'meet', 'you']) >>> sorted(ds) ['drink', 'i', 'love', 'meet', 'solve', 'you']
4)count(): 计算某个特定词在text,list中出现的次数
>>> ds.count('love') 1 >>> from nltk.book import * >>> text1.count('you') 841
5)计算词频
FreqDist(): 计算text,list中每一词的词频,返回fdist为nltk.probability.FreqDist对象。
fdist.hapaxes(): 返回只出现一次的词语
fdist.items(): 返回词语,频数对
fdist.max():返回频率最大的词
fdist.freq(): 返回某个特定词的频率
fdist.N(): 样本总数
fdist.keys(): 以频率递减顺序排序的样本链表
fdist.inc(sample): 增加样本
fdist['monstrous']: 计数给定样本出现的次数
>>> from nltk.book import * >>> fdist=FreqDist(text1) >>> type(fdist) <class 'nltk.probability.FreqDist'> >>> fdist.hapaxes()[:10] [u'funereal', u'unscientific', u'prefix', u'plaudits', u'woody', u'disobeying', u'Westers', u'DRYDEN', u'Untried', u'superficially'] >>> fdist.items()[:10] [(u'funereal', 1), (u'unscientific', 1), (u'divinely', 2), (u'foul', 11), (u'four', 74), (u'gag', 2), (u'prefix', 1), (u'woods', 9), (u'clotted', 2), (u'Du >>> fdist.max <bound method FreqDist.max of FreqDist({u',': 18713, u'the': 13721, u'.': 6862, u'of': 6536, u'and': 6024, u'a': 4569, u'to': 4542, u';': 4072, u'in': 3916 >>> fdist.max() u',' >>> fdist.freq('employment') 3.834076505162584e-06
6)可视化
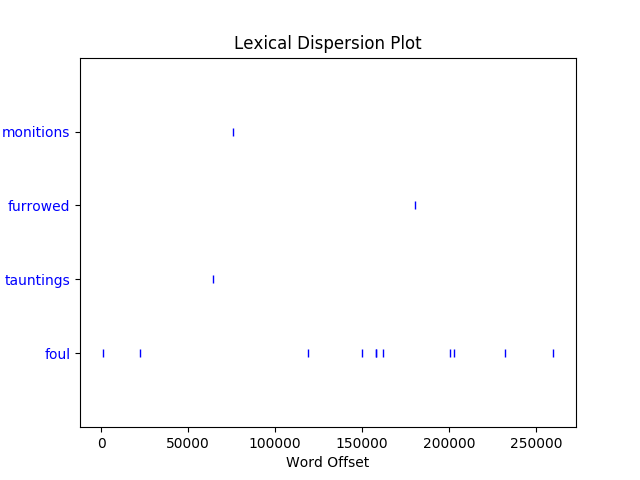
text.dispersion_plot():离散图,横坐标表示文章的位置,纵坐标表示你要显示的词集
>>> from nltk.book import * >>> text1.dispersion_plot(['monition', 'furrowed', 'tauntings', 'foul']) >>> text1.dispersion_plot(['monitions', 'furrowed', 'tauntings', 'foul'])
fdist.tabulate(): 绘制频率分布图
>>> import nltk >>> from nltk.corpus import brown >>> cfd=nltk.ConditionalFreqDist( ... (genre, word) ... for genre in brown.categories() ... for word in brown.words(categories=genre)) >>> genres=['news', 'religion', 'hobbies', 'romance'] >>> modals=['can', 'could', 'may', 'might', 'must', 'will'] >>> cfd.tabulate(conditions=genres, samples=modals) can could may might must will news 93 86 66 38 50 389 religion 82 59 78 12 54 71 hobbies 268 58 131 22 83 264 romance 74 193 11 51 45 43
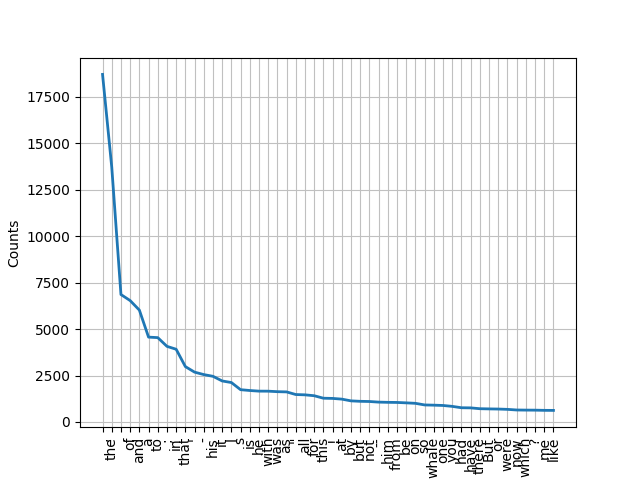
fdist.plot(): 绘制频率分布图
>>> from nltk.book import FreqDist >>> from nltk.book import text1 >>> fdist=FreqDist(text1) >>> fdist.plot(50)
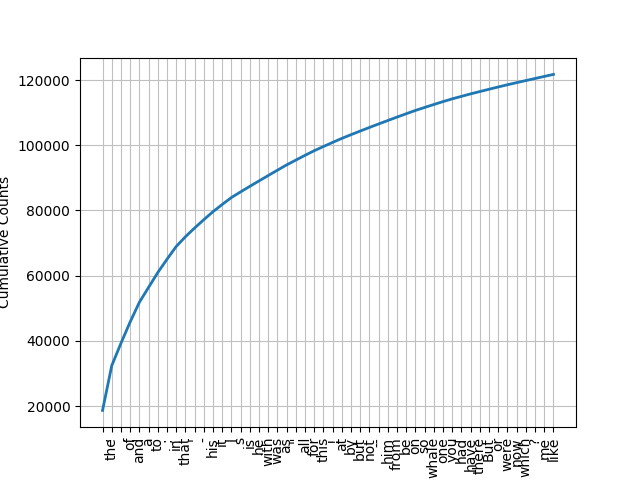
fdist.plot(50, cumulative=True): 绘制累积频率分布图
5. 双连词
1)text.collocations() : 统计文本中频繁的双连词
>>> text1.collocations()
Sperm Whale; Moby Dick; White Whale; old man; Captain Ahab; sperm
whale; Right Whale; Captain Peleg; New Bedford; Cape Horn; cried Ahab;
years ago; lower jaw; never mind; Father Mapple; cried Stubb; chief
mate; white whale; ivory leg; one hand
>>>
2) nltk.bigrams(para):提取文本中的双连词, para可以是text, list, str等。
6. text与list的转换
>>> ds ['you', 'can', 'understand', 'me', 'than', 'done'] >>> import nltk >>> fd=nltk.Text(ds) >>> fd <Text: you can understand me than done...>
7. 条件频率分布
nltk中的条件频率分布是定义,访问和可视化一个计数条件频率分布的常用方法和习惯用法,涉及的相关函数如下:
1) cfdist=ConditionalFreqDist(pairs): 从配对链表中创建条件频率分布
2) cfdist.conditions(): 将条件按字母排序来分类
3) cfdist[condition]: 此条件下的频率分布
4) cfdist[condition][sample]: 此条件下给定样本的频率
5)cfdist.tabulate(): 为条件频率分布制表
6) cfdist.tabulate(samples, conditions): 在指定样本和条件限制下制表
7)cfdist.plot(): 为条件频率绘图
8)cfdist.plot(samples, conditions):在指定样本和条件限制下绘图
9) cfdist1 < cfdist2: 测试样本在cfdist1中出现次数是否小于在cfdist2中出现的次数。


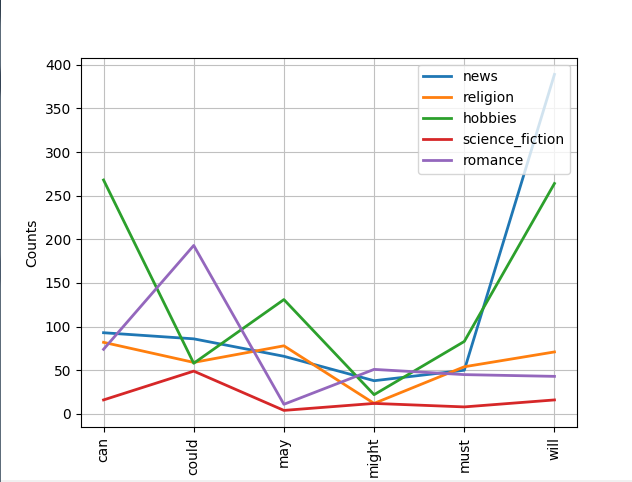
1 >>> from nltk.corpus import brown 2 >>> import nltk 3 >>> cfdist=nltk.ConditionalFreqDist( 4 ... (genre, word) 5 ... for genre in brown.categories() 6 ... for word in brown.words(categories=genre)) 7 >>> 8 >>> cfdist.conditions() 9 [u'mystery', u'belles_lettres', u'humor', u'government', u'fiction', u'reviews', u'religion', u'romance', u'science_fiction', u'adventure' 10 >>> cfdist['mystery'] 11 FreqDist({u'.': 3326, u',': 2805, u'the': 2573, u'to': 1284, u'and': 1215, u'a': 1136, u'of': 903, u'was': 820, u'``': 740, u"''": 738, .. 12 >>> cfdist['mystery']['and'] 13 1215 14 >>> genres=['news', 'religion', 'hobbies', 'science_fiction', 'romance'] 15 >>> modals=['can', 'could', 'may', 'might', 'must', 'will'] 16 >>> cfdist.tabulate(conditions=genres, samples=modals) 17 can could may might must will 18 news 93 86 66 38 50 389 19 religion 82 59 78 12 54 71 20 hobbies 268 58 131 22 83 264 21 science_fiction 16 49 4 12 8 16 22 romance 74 193 11 51 45 43 23 >>> cfdist.plot()
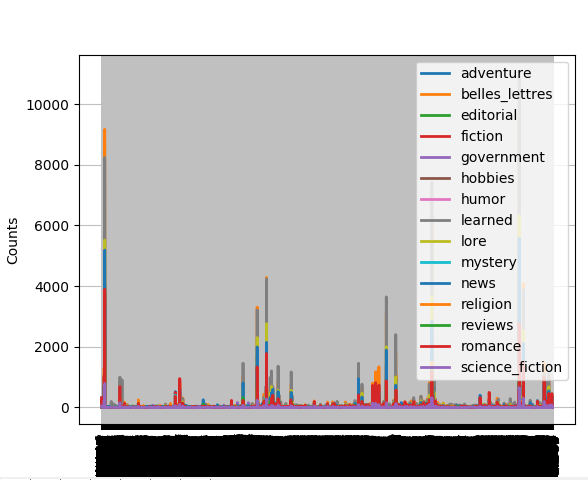
>>> cfdist.plot(samples=modals, conditions=genres)