k8s问题记录 - 机器重启后无法连接(The connection to the server <master>:6443 was refused - did you specify the right host or port?)
报错截图
The connection to the server 127.0.0.1:6443 was refused - did you specify the right host or port?

问题分析
6443 是api-server监听的端口,master节点6443请求不通
可能的原因
- 集群硬件时间和系统时间不同步,在重启服务器后系统时间会同步硬件时间,集群的时间管理混乱,进而导致此类问题
- 查看端口是否被占用或者是否被防火墙、iptables这些拦截下来了
- 更改主机名或者服务器重启后出现此报错
- 通用排查
开始排查
- 首先检查,确保以下内容正常无误
1.防火墙已经关闭
2.selinux设置disabled完成(这个很重要,如果没有关闭,会导致机器重启,k8s重启失败,6443接口请求不通)
3.docker(containerd)启动正常
4.kubelet运行状态active
5.docker(containerd) images存在所需镜像 - 检查6443端口监听状态
[root@dev-master ~]# netstat -pnlt | grep 6443 tcp6 0 0 :::6443 :::* LISTEN 3804/kube-apiserver - 检查k8s相关的服务是否都正常开启,正常类似如下状态:
# netstat -tunlp |grep kube tcp 0 0 0.0.0.0:31080 0.0.0.0:* LISTEN 28351/kube-proxy tcp 0 0 127.0.0.1:10248 0.0.0.0:* LISTEN 25129/kubelet tcp 0 0 127.0.0.1:10249 0.0.0.0:* LISTEN 28351/kube-proxy tcp 0 0 127.0.0.1:40745 0.0.0.0:* LISTEN 25129/kubelet tcp 0 0 0.0.0.0:32276 0.0.0.0:* LISTEN 28351/kube-proxy tcp 0 0 0.0.0.0:30260 0.0.0.0:* LISTEN 28351/kube-proxy tcp 0 0 0.0.0.0:30108 0.0.0.0:* LISTEN 28351/kube-proxy tcp 0 0 0.0.0.0:30526 0.0.0.0:* LISTEN 28351/kube-proxy tcp 0 0 0.0.0.0:30238 0.0.0.0:* LISTEN 28351/kube-proxy tcp 0 0 0.0.0.0:31615 0.0.0.0:* LISTEN 28351/kube-proxy tcp 0 0 0.0.0.0:30593 0.0.0.0:* LISTEN 28351/kube-proxy tcp 0 0 0.0.0.0:32548 0.0.0.0:* LISTEN 28351/kube-proxy tcp 0 0 0.0.0.0:30148 0.0.0.0:* LISTEN 28351/kube-proxy tcp6 0 0 :::10250 :::* LISTEN 25129/kubelet tcp6 0 0 :::6443 :::* LISTEN 38054/kube-apiserve tcp6 0 0 :::10256 :::* LISTEN 28351/kube-proxy tcp6 0 0 :::10257 :::* LISTEN 52587/kube-controll tcp6 0 0 :::10259 :::* LISTEN 37260/kube-schedule - 检查etcd是否正常:
systemctl status etcdsystemctl start etcdjournalctl -u etcd -f - 检查docker(containerd)是否正常:
k8s 1.24.2版本以后 不再支持docker引擎,根据自己的版本检查对应的容器引擎。systemctl status docker systemctl status containerdsystemctl start docker systemctl start containerdjournalctl -u docker -f journalctl -u containerd -f - 检查kubelet是否正常:
systemctl status kubeletsystemctl start kubeletjournalctl -u kubelet -f - 最后检查当前pod信息
- docker:
[root@dev-master ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 893fcc28f78f 3db3d153007f "kube-scheduler --au…" 8 weeks ago Up 8 weeks k8s_kube-scheduler_kube-scheduler-dev-master_kube-system_fb928538fabb4df5210f80904ba26ca7_9 f5d1721520eb 5344f96781f4 "kube-controller-man…" 8 weeks ago Up 8 weeks k8s_kube-controller-manager_kube-controller-manager-dev-master_kube-system_d31ca475a6c2470d726b7718fc143509_10 196933170d0b 8522d622299c "/opt/bin/flanneld -…" 6 months ago Up 6 months k8s_kube-flannel_kube-flannel-ds-z2kmg_kube-system_84ab1d33-45fd-406e-8d15-31e67aaed2a5_11 7dfdd316e4ae registry.aliyuncs.com/google_containers/pause:3.5 "/pause" 6 months ago Up 6 months k8s_POD_kube-flannel-ds-z2kmg_kube-system_84ab1d33-45fd-406e-8d15-31e67aaed2a5_5 fcad19801a96 bbad1636b30d "/usr/local/bin/kube…" 6 months ago Up 6 months k8s_kube-proxy_kube-proxy-prvbf_kube-system_4d0115ba-acd5-4887-8bfa-2633b8321014_5 0f41fb0aecf2 registry.aliyuncs.com/google_containers/pause:3.5 "/pause" 6 months ago Up 6 months k8s_POD_kube-proxy-prvbf_kube-system_4d0115ba-acd5-4887-8bfa-2633b8321014_5 dde5813b5d77 838d692cbe28 "kube-apiserver --ad…" 6 months ago Up 6 months k8s_kube-apiserver_kube-apiserver-dev-master_kube-system_7edfa383e05f8312ca77c3bacd0ea393_9 7b5157b363a0 004811815584 "etcd --advertise-cl…" 6 months ago Up 6 months k8s_etcd_etcd-dev-master_kube-system_0f9a5e2fb006cbdbbe19271c5eea7222_7 f7d78a80931b registry.aliyuncs.com/google_containers/pause:3.5 "/pause" 6 months ago Up 6 months k8s_POD_etcd-dev-master_kube-system_0f9a5e2fb006cbdbbe19271c5eea7222_6 2d02e30659cb registry.aliyuncs.com/google_containers/pause:3.5 "/pause" 6 months ago Up 6 months k8s_POD_kube-scheduler-dev-master_kube-system_fb928538fabb4df5210f80904ba26ca7_5 c99268aeedcb registry.aliyuncs.com/google_containers/pause:3.5 "/pause" 6 months ago Up 6 months k8s_POD_kube-apiserver-dev-master_kube-system_7edfa383e05f8312ca77c3bacd0ea393_5 fa3ae165baf7 registry.aliyuncs.com/google_containers/pause:3.5 "/pause" 6 months ago Up 6 months k8s_POD_kube-controller-manager-dev-master_kube-system_d31ca475a6c2470d726b7718fc143509_6 - containerd:
[root@master ~]# crictl ps CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID POD 51f87088f86d2 35acdf74569d8 16 hours ago Running kube-apiserver 1 daf41f5e77f2f kube-apiserver-master dec1c3221c47d 25561daa66605 16 hours ago Running metrics-server 0 427449f68860c metrics-server-556d5d785-n89zq cda92d8e78103 bf9a79a05945f 16 hours ago Running netchecker-agent 0 dd961b8f652c3 netchecker-agent-8lbtp fd48596d0b3f2 bf9a79a05945f 16 hours ago Running netchecker-agent 0 521855ec0c27f netchecker-agent-hostnet-b64qr 6245bd8c9fc0e 9eaf430eed843 16 hours ago Running node-cache 0 4e988dcf09573 nodelocaldns-85qnd 3707ea82c2c57 1e7da779960fc 16 hours ago Running autoscaler 0 a28171327e3f5 dns-autoscaler-998c74f6b-8gbwg d2cafe758d262 5185b96f0becf 16 hours ago Running coredns 0 21646b425d129 coredns-55859db765-cz8q9 769be058a070f 21def9ea80053 16 hours ago Running kuboard 0 710cc18659088 kuboard-v3-master 7d8f52dc81116 54637cb36d4a1 16 hours ago Running calico-node 0 392c0b70c8f6e calico-node-ftpkk 38d06d15bcf82 b19f8eada6a93 16 hours ago Running kube-proxy 0 dcfa61dc29c26 kube-proxy-45cnr 43880303d76f3 ab525045d05c7 16 hours ago Running kube-controller-manager 1 99a2959e51079 kube-controller-manager-master 0cdaa213071b4 15a59f71e969c 16 hours ago Running kube-scheduler 1 029384239f6de kube-scheduler-master
- docker:
确定问题原因
我此次产生6443报错问题的原因是:检查pod时候,发现所有pod都已宕掉,都是notReady状态,尝试了重启etcd、重启containerd、重启kubelet,都未能解决。猛然间想起来查看SELinux的状态,发现SELinux没有关闭,是permissive状态,所以导致重启机器,重启etcd、重启containerd、重启kubelet均无法重新拉起k8s集群。
解决问题
- 我的解决方式
- 我重新安装了k8s集群,这次安装k8s集群前,,我手动关闭了SELinux,我手动关闭了SELinux,我手动关闭了SELinux,重要的事情说三遍,,然后静待集群安装完成。
- 然后重启机器测试,果然,在机器重启后,k8s集群也重启了,完美解决。
- 通过查阅资料,进行了kubeadm reset 重置,结果还是无济于事,此处记录下 kubeadm reset的过程
- master端:
1.kubectl 查看命令是否正常
2.cd ~ 进入根目录
3.ll -a 查看是否存在.kube文件
4.rm -rf .kube/ 删除
5.systemctl restart docker 重启docker
6.systemctl restart kubelet 重启kubelet
7.kubeadm reset 重置
8.rm -rf /etc/cni/ 删除
9.kubeadm init --kubernetes-version=v1.17.17 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/16 --ignore-preflight-errors=Swap 初始化节点(根据情况修改),【到此步,我已经进行不下去,因为无法init,出现了报错,具体报错原因,我没深研究】
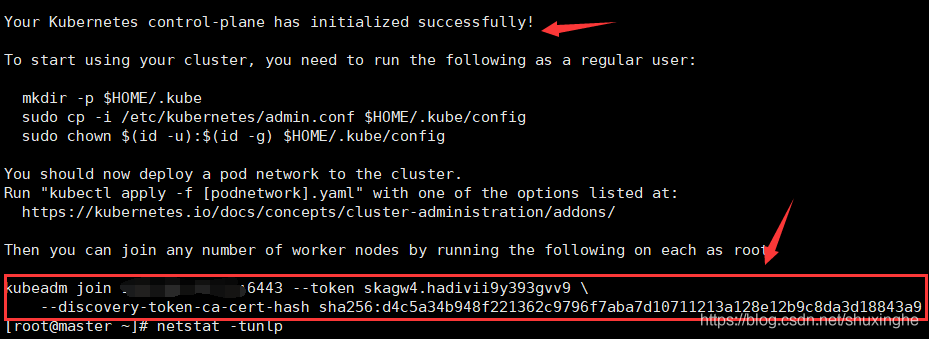
10.初始化命令成功后,创建.kube目录(重新配置)
10.1mkdir -p $HOME/.kube
10.2sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
10.3sudo chown $(id -u):$(id -g) $HOME/.kube/config
11.此时就可以使用kubectl get node 查看集群状态,如果出现状态为notready
12.下载并安装flannel配置,需要配置kube-flannel.yml
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
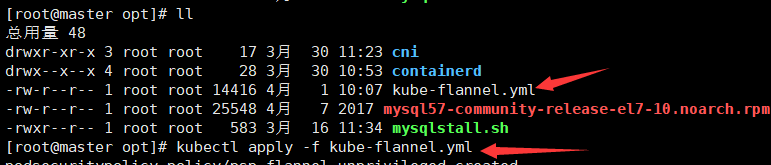
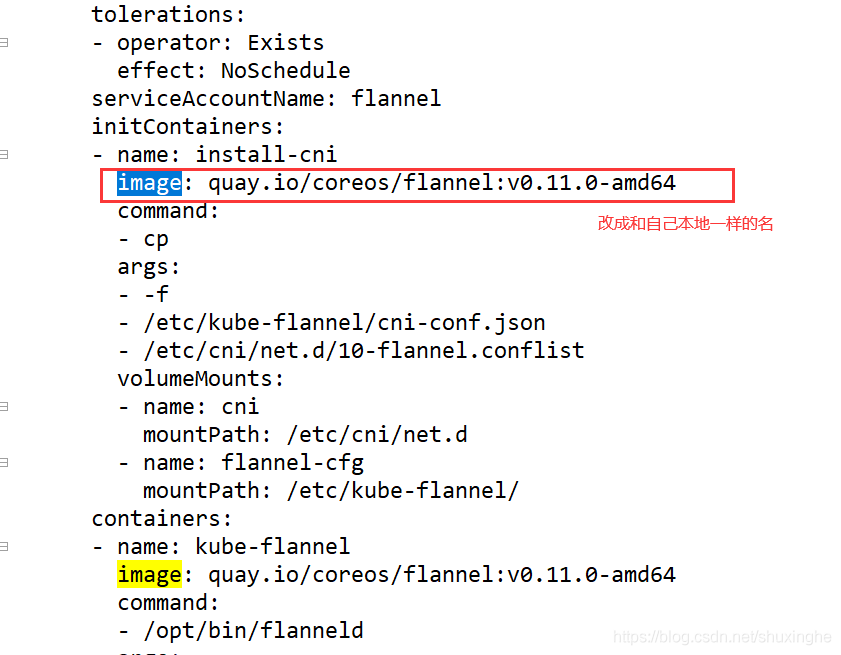
13.然后把文件 kube-flannel.yml 拷贝到opt目录下,执行
kubectl apply -f kube-flannel.yml
14.运行后即可

15.查看节点,已经出现,查看6443端口号,已经出现 - node端
1.kubeadm reset 重置
2.rm -rf /etc/cni/
3.vi /etc/sysconfig/kubelet
3.1.kubeadm join x.x.x.x:6443 --token skagw4.hadivii9y393gvv9 --discovery-token-ca-cert-hash
sha256:d4c5a34b948f221362c9796f7aba7d10711213a128e12b9c8da3d18843
4.systemctl enable docker
- master端:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通