

个人作业—词频统计
作业要求:
对源文件中出现的字符,单词,函数,词频进行统计。并且利用性能测试工具分析找出瓶颈并改进。
基本要求的功能:
1·统计文件的字符数;
2·统计文件的单词数;
3·统计文件的的总行数;
4·统计文件中各个单词出现的次数;
5·统计文件中各个词组出现的次数;
6·尝试在Linux系统下进行性能分析;
功能设计:
必要的步骤:遍历所有文件,读取每一个字符
根据字符的定义,对每一个获取的字符进行判断其类似(数字字母符号,间隔符),进行相应的操作。顺便记录字符数增加。
用一个char型数组存储一次连续获得的数字字母符号。
判断字符串的长度即前四个元素是否为字母来判断是否为合法单词。
遇到'\n'行数增加,遇到文末时当作遇到'\n'处理。
由于数据的不断增加,数组是很难控制其时间复杂度的,放弃这一想法;哈希表的哈希函数的选取,表长度的选取很关键,毕竟是一个读取200+M的文件夹,处理的数据量可想而知,要想得到良好的时间效应就必须造一个填充率不能太高的哈希表,这会占用太大的空间,暂且不能放弃这一思路;链式结构,最简单的是按照字典顺序有序的插入单词结构体至一条链,但是这样的话,每一次插入新元素都得遍历很多单词才能找到其位置,时间复杂度巨高!遍历这种事实在是感觉太蠢了,没有效率,也没有思想的优美。
比较哈希表和链的优缺点,想到了类似于桶式结构,因为单词必须前四个是字母,那么就将所有数据分在26^4(456976)个链中,用它们的前四个字母决定其所在的区间,考虑在小区间里面单词的数量减少很多,这时可以容忍在小区间的遍历带来的时间的代价。哈希表的哈希函数的选取至关重要,解决冲突也不可忽视,在还没有想到其他方法之前就确定了采用使用过多次的链式结构。在时间有限的情况这样应该是我的最佳选择。
思考细节部分的处理:
由于数字的加入,strcmp函数不好使用,那就自己写比较的函数了。
想找到top10的单词的话,当然最简单的就是最后遍历所有的链,畏惧庞大数据量带来的时间的代价,想到要找top10的单词,那么我们就用10个指针时时刻刻指向我们的top10的单词,最后只需要直接调用其数值就可以了。
具体实现代码:
结构体与全局变量:
#define word_MAX 1024
int TOP_WORD = 10;//想要查找前10个单词
int TOP_WORD_WORD = 10;//想要查找前10个词组
//文件夹最后
struct handle_chain {
int change;
long handle;
handle_chain* before;
handle_chain* next;
};
struct word {
char* name;
int num;
word* next_in_name;
word* next_in_num;
word* before_in_num;
};
struct word_word {
char* name1;
char* name2;
int num;
word_word* next_in_name;
word_word* next_in_num;
};
struct top_word_word {
int num;
word_word* chain;
};
word index_word[26][26][26][26] = {};//26个字母,前四个必为字母
//word_word index_word_word[26][26][26][26] = {};//26个字母,前四个必为字母
word* wordlist[10] = {};
//top_word_word word_wordlist[TOP_WORD_WORD] = {};
char OLD[word_MAX] = {}, NEW[word_MAX] = {};//储存之前的那个单词
int char_num = 0, word_num = 0, line_num = 0, file_num = 0;
char to_search[N] = {};
long handle;
handle_chain* head = (handle_chain*)malloc(sizeof(handle_chain)), *work = head;
文件的遍历:
其中把文件和文件夹看成一棵树,遍历的步骤就是深度遍历,由于不知道句柄能否复原所以用栈的结构来储存句柄的值!
void next_file(long &handle, _finddata_t &fileinfo) {//直接找到下一个文件或者文件夹
if (handle == -1)
return;
while (1) {
if (!_findnext(handle, &fileinfo)) {
if (strcmp(fileinfo.name, ".") && strcmp(fileinfo.name, ".."))
break;
}
else {
handle = work->handle;//出栈
work = work->before;
int length = strlen(to_search);
char tem[6] = "\\*.*";
to_search[length - 5 - work->next->change] = '\0';
free(work->next);
if (work&&work == head)
work->next = work;
strcat(to_search, tem);
if (handle == -1)
break;
}
}
return;
}
void findfile(_finddata_t &fileinfo) {//找到下一个文件!
while (handle != -1) {
if (!strcmp(".", fileinfo.name) || !strcmp("..", fileinfo.name)) {
next_file(handle, fileinfo);
if (fileinfo.attrib & 0x00000020)
break;
}
int a = fileinfo.attrib & 0x00000020;//文件>0,文件夹==0
if (a) {
next_file(handle, fileinfo);
if (fileinfo.attrib & 0x00000020)
break;
}
else if (!a) {//可以去掉!
int length = strlen(to_search);
char tem[6] = "\\*.*";
to_search[length - 3] = '\0';
strcat(to_search, fileinfo.name);
strcat(to_search, tem);
creatnode_handle(strlen(fileinfo.name), handle);//进栈
handle = _findfirst(to_search, &fileinfo);
if (!strcmp(".", fileinfo.name) || !strcmp("..", fileinfo.name)) {
next_file(handle, fileinfo);
if (fileinfo.attrib & 0x00000020)
break;
}
}
}
return;
}
判断文件的类型是否为合法的类型:
从文件名的最后向前寻找'.'找到之后从此回溯,用switch加if...else语句判断文件类型
int judge_file(char* name) {//判断是否可读 0为不可读 1为可读
if (!name)
return 0;
int length = strlen(name), now = length;
while (now) {//其实也许可以不要这个判定条件
if (*(name + now - 1) == '.')
break;
now--;
}
if (!now)
return 0;
switch (*(name + now)) {//txt cs cpp js java py h php html
case 't':
if (now + 3 == length && *(name + now + 1) == 'x'&&*(name + now + 2) == 't')
return 1;
else
return 0;
case 'c':
if (now + 3 == length && *(name + now + 1) == 'p'&&*(name + now + 2) == 'p') {
return 1;
}
else if (now + 2 == length && *(name + now + 1) == 's')
return 1;
else
return 0;
case 'h':
if (now + 4 == length && *(name + now + 1) == 't'&&*(name + now + 2) == 'm'&&*(name + now + 3) == 'l') {
return 1;
}
else if (now + 1 == length)
return 1;
else
return 0;
case 'j':
if (now + 4 == length && *(name + now + 1) == 'a'&&*(name + now + 2) == 'v'&&*(name + now + 3) == 'a') {
return 1;
}
else if (now + 2 == length && *(name + now + 1) == 's')
return 1;
else
return 0;
case 'p':
if (now + 3 == length && *(name + now + 1) == 'h'&&*(name + now + 2) == 'p') {
return 1;
}
else if (now + 2 == length && *(name + now + 1) == 'y')
return 1;
else
return 0;
default:
return 0;
}
return 0;
}
从文件获取字符并进入单词或者词组的处理:
void calculate(FILE* fp) {
if (!fp) {
cout << "打开文件失败!" << endl;
return;
}
//bool nonempty = false;//空
char c;//初始化为'1'
int NEW_work = 0;
while (1) {//c属于合法符号
c = fgetc(fp);
if (c == EOF) {//文末处理!!!!!!!!!!!!!!!
//line_num+=nonempty;//文件之间的行数增加
line_num++;
if (judge_word(NEW)) {//有剩余
WORD();
WORD_WORD();
}
memset(OLD, 0, sizeof(char)*word_MAX);
memset(NEW, 0, sizeof(char)*word_MAX);
return;
}
//判断是字符
//nonempty = true;//非空
if (c == '\n' || c == '\r') {
line_num++;//统计行数
//nonempty = false;//下一行为空
}
if ((c > 31 && c < 127))
char_num++;
if ((c > 47 && c < 58) || (c > 64 && c < 91) || (c > 96 && c < 123)) {
NEW[NEW_work] = c;
NEW_work++;
/*if (NEW_work >word_MAX ) {
cout << "出现超长单词" << endl;
}*/
}
else {//出现分隔符
NEW_work = 0;
if (judge_word(NEW)) {//有更新
WORD();
WORD_WORD();
copy(OLD, NEW);//词组的传递
}
memset(NEW, 0, sizeof(char)*word_MAX);
}
}
}
int judge_word(char* src) {
if (strlen(src) < 4)
return 0;
if (!((src[0] > 64 && src[0] < 91) || (src[0] > 96 && src[0] < 123)))
return 0;
if (!((src[1] > 64 && src[1] < 91) || (src[1] > 96 && src[1] < 123)))
return 0;
if (!((src[2] > 64 && src[2] < 91) || (src[2] > 96 && src[2] < 123)))
return 0;
if (!((src[3] > 64 && src[3] < 91) || (src[3] > 96 && src[3] < 123)))
return 0;
word_num++;
return 1;
}
单词的比较:
逐一比较两个单词的每个字母,根据比较结果判断单词插入链的未知以及是否更改当前单词的内容:
float cmp_word(char* out_chain, char* in_chain) {//A<a
int length_out_chain = strlen(out_chain), length_in_chain = strlen(in_chain), i = 0;
float witch = 0;//确定保留谁
while (i < length_out_chain && i < length_in_chain) {
if (out_chain[i] == in_chain[i]) {
if (fabs(witch)>1 && (out_chain[i] > '9'))
return 2 * witch;
}
else if (out_chain[i] == in_chain[i] + 'a' - 'A'&&in_chain[i] > '9') {
if (!witch)
witch = 1;//保留in_chain
else if (fabs(witch) > 1)
return 2 * witch;
}
else if (out_chain[i] == in_chain[i] - 'a' + 'A'&&out_chain[i] > '9') {
if (!witch)
witch = -1;//保留out_chain
else if (fabs(witch) > 1)
return 2 * witch;
}
else if ('0' <= out_chain[i] && out_chain[i] <= '9'&&'0' <= in_chain[i] && in_chain[i] <= '9') {
if (out_chain[i] < in_chain[i] && fabs(witch) <= 1)
witch = -1.5;
else if (out_chain[i] > in_chain[i] && fabs(witch) <= 1)
witch = 1.5;
}
else {
if (witch) {
return 2 * witch;//判定一定不是同一个单词
}
else {
if (out_chain[i] < in_chain[i])
return -2;//判定一定不是同一个单词 out_chain在in_chain之前
else
return 2;//判定一定不是同一个单词 out_chain在in_chain之后
}
}
i++;
}
if (!out_chain[i] && !in_chain[i]) {
return (int)witch;
}
if (!out_chain[i]) {
while (in_chain[i]) {
if (in_chain[i] > '9')
return -2;//判定一定不是同一个单词 out_chain在in_chain之前
i++;
}
if (!witch) {
return -1;
}
else
return (int)witch;
}
else {
while (out_chain[i]) {
if (out_chain[i] > '9')
return 2;//判定一定不是同一个单词 out_chain在in_chain之后
i++;
}
if (witch) {
return 1;
}
else
return (int)witch;
}
}
单词的插入:
按照字典顺序插入
void input_word(word &word_head) {
if (!word_head.next_in_name) {
word_head.next_in_name = creat_word(NEW);
upgrade(word_head.next_in_name);
return;
}
word* work = &word_head;
int cmp;
while (work->next_in_name) {
cmp = cmp_word(NEW, work->next_in_name->name);
cmp = -1;
if (cmp >= 2) {
work = work->next_in_name;
}
else
break;
}
if (!work->next_in_name)
work->next_in_name = creat_word(NEW);
else if (cmp <= -2) {
word* tem = creat_word(NEW);
tem->next_in_name = work->next_in_name;
work->next_in_name = tem;
}
else {
work->next_in_name->num++;
if (cmp == -1) {
work->next_in_name->name=(char*)realloc(work->next_in_name->name, sizeof(char)*strlen(NEW));
copy(work->next_in_name->name, NEW);
}
upgrade(work->next_in_name);//work->next_in_name要进行升级
}
return;
}
这儿应该还有关于如何用top10的指针,但是由于想法太复杂,情况太对,写出来的程序至今没有通过,这让我...不好意思拿出来就略过吧.
PSP表格

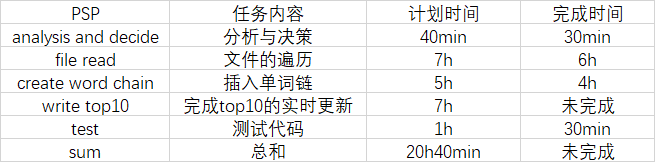
代码质量与性能分析:
有四个warning,均来自于int 与 float之间的转化,这是函数cmp_word用来区别不同情况和简化步骤中涉及多数情况对应少数的处理,这样为了简单就将一些可以归于一类处理的情况的输出参数调整至相同,所以说这里的是利用了强制转化的特点故意为之.
因为单词的查找前十未能成功实在遗憾.起初word结构体name分量是固定的长度为100的数组,然而实际运行时堆栈的内存不够,而且几天之后得知单词长度的最大值限定是1024,我就立即为了空间舍弃了时间上的效率将其改为char*类型的分量,每次创造和更改时都重新分配空间以节省空间.这一巨大的改变之后我立即又跑了一次程序,结果出乎所料,时间上的代价其实并不大,还算可以忍受(不然我没有办法嘛,不能忍还是得忍呀!空间不够让我无路可走).
反思以及收获:
首先最重要的一点是今早想到的,因为每次读入一个单词,其数目(num分量)就会增加,我为了实时更新top10的指针就会调用那个没有拿出来的函数.看了看,想了想,虽然最后找到top10会是O(n)的复杂度,但是统计出来的单词数可是接近2000w,也就是说我这个函数被调用了2000w次!!!这是何等的浪费时间!!!不能放弃原始的骚操作,没有勇气做出改变让我付出了巨大的代价.不过算是一次血的教训,值了!仔细算算时间的消耗,其实直接遍历还会出奇的比这个想法更节省时间。看来得重新审视这个被我鄙视太久的想法,有时候越简单的想法也会是约聪明的想法!!
还有一个教训就是信息的获取能力,虽然老师说过一些承诺(比如要给我们需要读取的文件的类型,但是最后没有给,我就按照博客上所给的文件类型写了文件的合法的判断),但就像用户的需求会随时改变一样,要实时与老师交流,获得正确的信息,才是编程的最最关键的元素!!

