百度图片
问题成因:喜欢在百度稿子里,搞资料,但VIP,大家都懂。则看源代码,想全部找到。可是看 一个ppt文档, 里面都是连接,发现都是图片,单独点击连接能打开图片。
恍然大悟。粘出来的 连接 是 <img .... ;
</div> <div> 混杂的,则写了个 小 C程序,处理了一下。
#include<stdio.h>
int main(){
int i,j;
char c1,c2,c3,c4;
freopen("jt.txt","r",stdin);
freopen("jto.txt","w",stdout);
while(1){
scanf("%c",&c1);
if(c1=='<')
{
scanf("%c%c%c",&c2,&c3,&c4);
if(c2=='t' && c3=='i' && c4=='g') // <tig 挺
break;
else if(c2=='i' && c3=='m' && c4=='g')
{//想要的
printf("<img ") ;
while(1){
scanf("%c",&c1);
if(c1 == '>')
{printf(">\n");break;
}
else
printf("%c",c1);
}
}
else{ ////// </div> <div>
while(1)
{
scanf("%c",&c1);
if(c1== '>')
break;
}
}
}
}
return 0;
}
整理成<img src=" "> 的情形。接下来就简单了,粘贴到Excel里,数据分列,就得出来 纯的 图片网页连接,没错接下来就是利用 Python urllib 及 cv2 来显示保存图片。
其实 找到网页源码里的 <img 时考虑直接 新建 html 沾到 <body >里显示,但出不来,只有3张,不知为何。
import numpy as np
import urllib.request
import xlrd
import cv2
wb = xlrd.open_workbook("tp.xlsx")
biao = wb.sheet_by_name("Sheet1")
for i in range(biao.nrows ):
lj = biao.row_values(i)[0]
resp = urllib.request.urlopen(lj)
image = np.asarray(bytearray(resp.read()),dtype="uint8")
image =cv2.imdecode(image,cv2.IMREAD_COLOR)
# cv2.imshow("Image",image)
mz = str(i) + ".jpg"
cv2.imwrite(mz,image)
cv2.waitKey(0)
一个循环,用个 xlrd 然后 imwrite ,保存了 这些图片,连接一共有一百多条,但图片只出来了九十几张,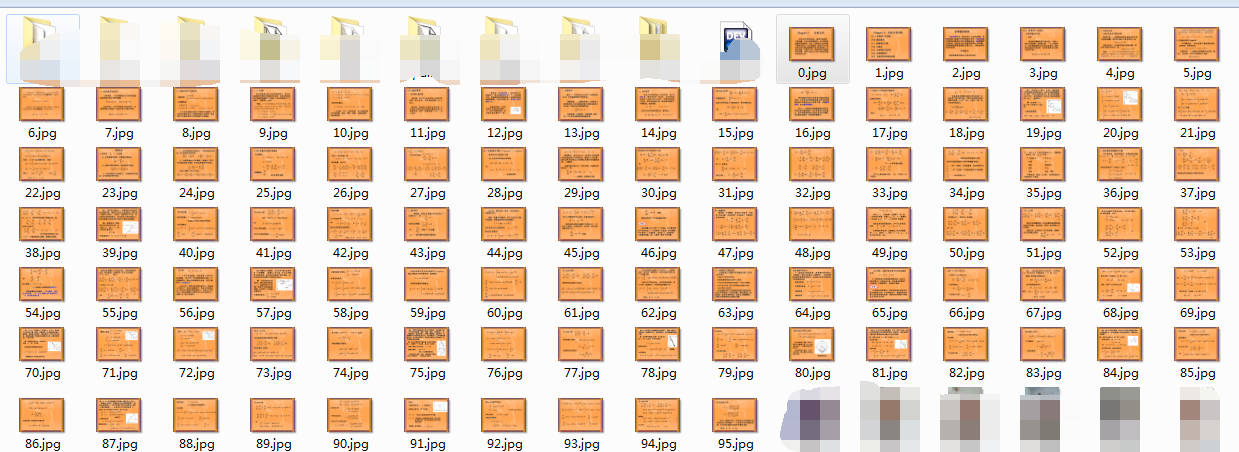
不管了 不求不求甚解。费时 一中午。自我感觉良好,谢谢!献丑
posted on 2021-06-30 14:10 Heart&ware 阅读(2132) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号