
LinkedHashSet源码阅读理解
概述
1、底层:HashSet + LinkedHashMap
2、创建节点时将节点插入链表,因此有序
3、线程不安全
源码理解
demo:
public class LinkedHashSetDemo {
public static void main(String[] args) {
test();
}
public static void test(){
LinkedHashSet<Object> linkedHashSet = new LinkedHashSet<>();
linkedHashSet.add("");
linkedHashSet.remove("");
}
}
1、先看下创建其对象的时候做了些什么

调用其父类的构造方法,跟进去…

来到HashSet的有参构造方法,其中initialCapacity = 16、loadFactor = 0.75f、dummy = true,内部使用前两个参数构建了一个LinkedHashMap对象作为全局变量,可以看到这个dummy参数没有使用到;

因此无参创建LinkedHashSet对象的时候实际上就是初始化了HashSet内一个LinkedHashMap的全局变量,且初始容量为16,负载因子为0.75;
2、LinkedHashSet的add()方法:
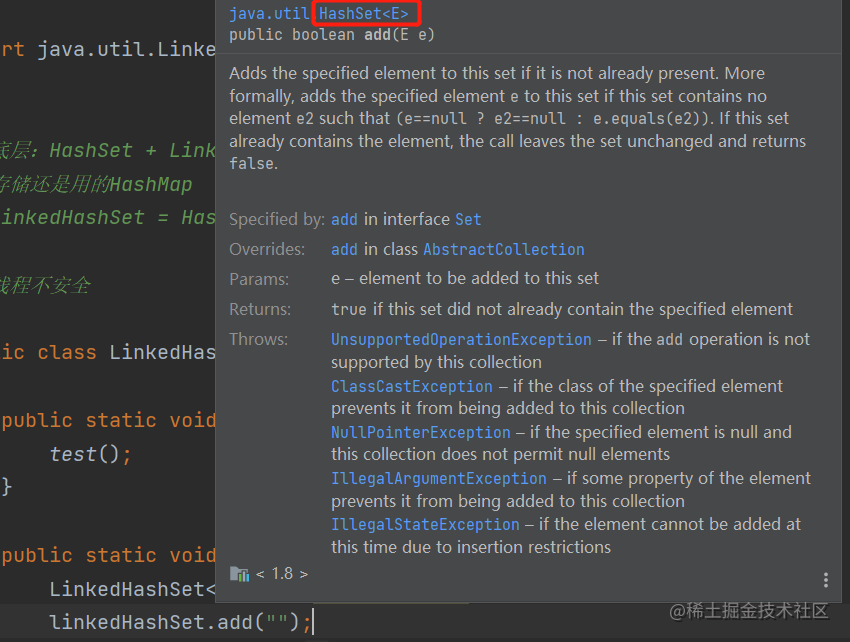
实际上调用的是HashSet的add方法,
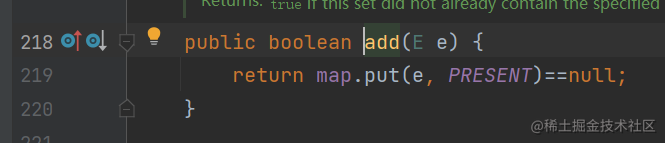
这个map类型前面说到了是LinkedHashMap,看下PRESENT是什么:

一个Object对象;
至此,LinkedHashSet的add方法其实就是调用将数据存储到一个LinkedHashMap集合中;
那么继续来看下LinkedHashMap中是怎么存储数据的,为什么让其有序;
3、LinkedHashMap的put方法:
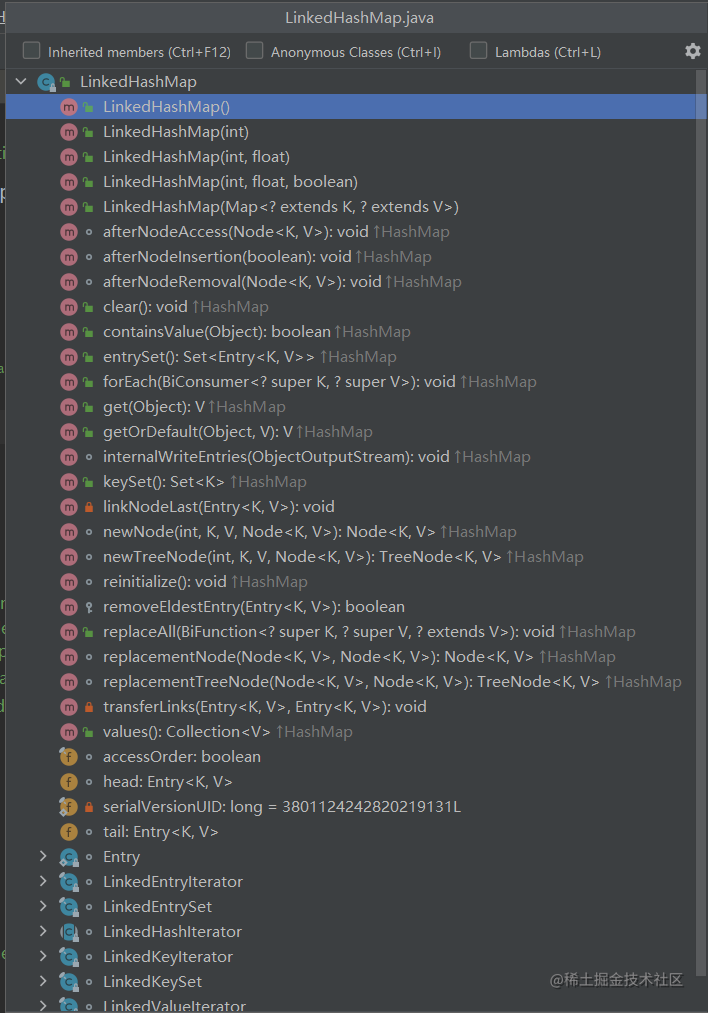
发现LinkedHashMap内其实是没有put方法的,那么也就是说这个put方法是其父类的,而LinkedHashMap的父类就是HashMap:
那再回顾一次HashMap的put方法:

final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 寻址
if ((p = tab[i = (n - 1) & hash]) == null)
// 构建节点插入数组
// LinkedHashMap重写了构建节点的方法,此处及以下调用的都是LinkedHashMap中的newNode
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
接着看LinkedHashMap中重写的newNode()方法
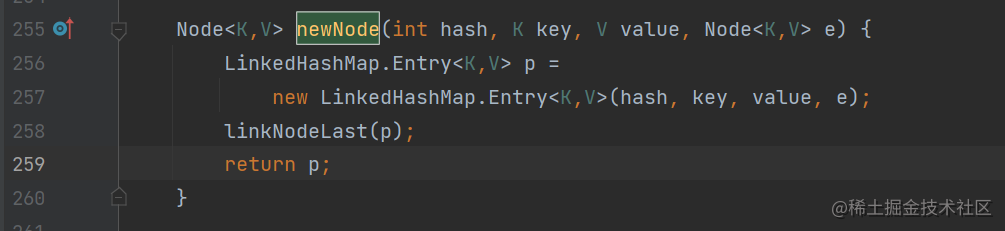
第258行就是将节点插入链表,跟进linkNodeLast()
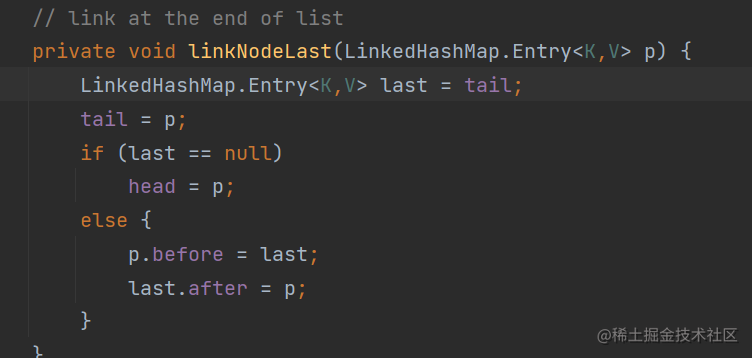
可见,内部是一个很简单的链表插入,这也就是LinkedHashMap内部维护的一个链表;
总结:LinkedHashSet底层其实就是调用的HashSet + LinkedHashMap,以保证数据的唯一和插入有序;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号