
1. 一般常用的有5种(textfile, sequencefile, rcfile, orc, parquet),默认的存储格式是textfile。
2. 5种存储格式的区别
| 存储格式 | 文件存储编码格式 | 建表指定 |
|---|---|---|
| textfile |
将表中的数据在hdfs上以正常文本的格式存储,下载后可以直接查看。 |
stored as textfile
|
| sequencefile |
将表中的数据在hdfs上以二进制格式编码,并将数据压缩,下载的数据是二进制格式,不可以直接查看,无法可视化。 |
stored as sequecefile |
| rcfile | 将表中的数据在hdfs上以二进制格式编码,并且支持压缩。下载后的数据无法可视化。 | stored as rcfile |
| orc | 文件存储方式为二进制文件。orc文件格式从hive0.11版本后提供,是RcFile格式的优化版,主要在压缩编码,查询性能方面做了优化。按行组分割整个表,行组内进行列式存储。 | stored as orc |
| parquet | 文件存储方式为二进制文件。parquet基于dremel的数据模型和算法实现,列式存储。 | stored as parquet |
3. 实践操作
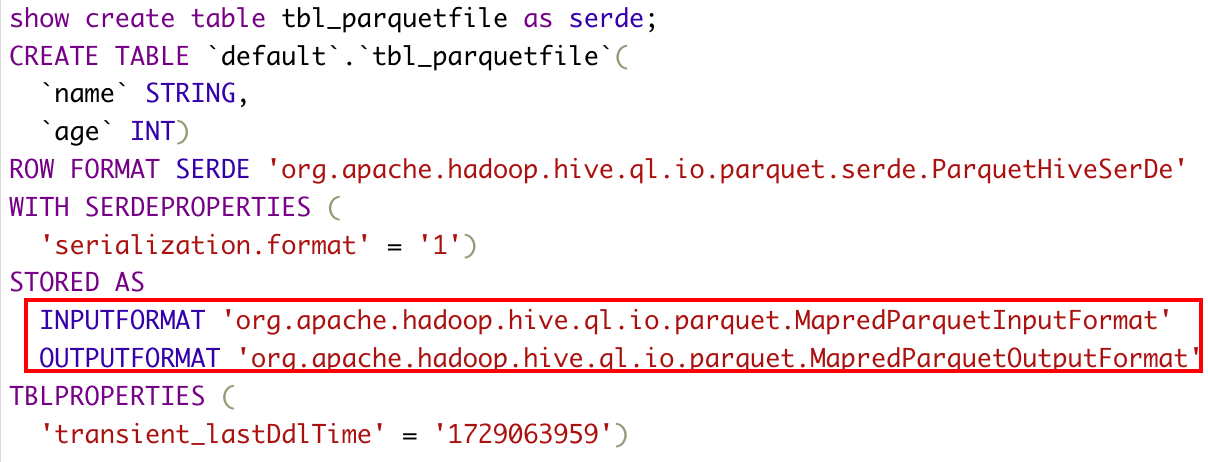
标记部分是利用hadoop本身的InputFormat API从不同的数据源读取数据,OutputFormat API将数据写成不同的格式,不同的数据源或者不同的存储格式需要不同的InputFormat和OutFormat来实现。
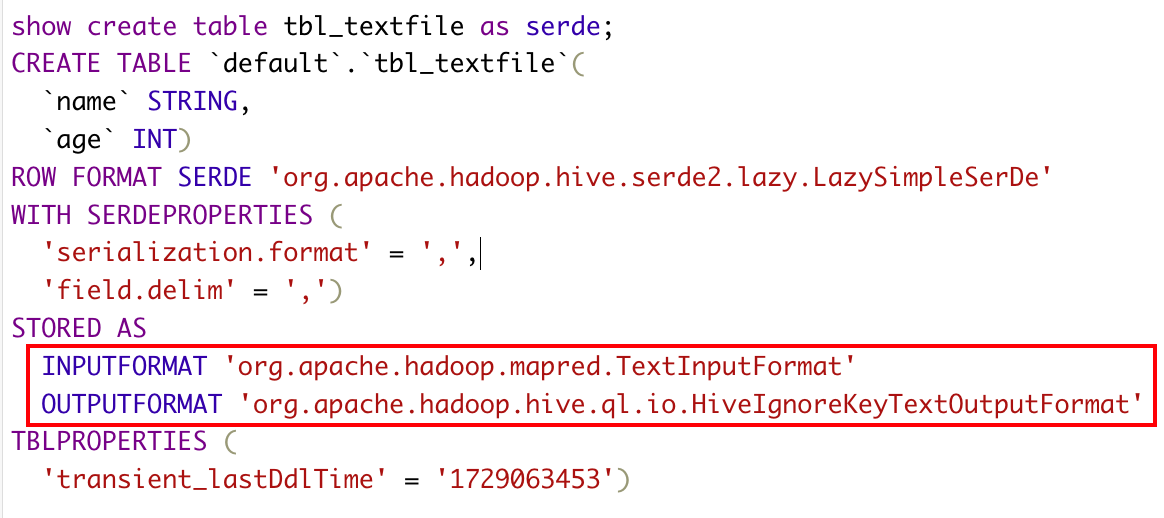
1)textfile
CREATE TABLE teacher1( name string, age int )row format delimited fields terminated by ',' stored as textfile
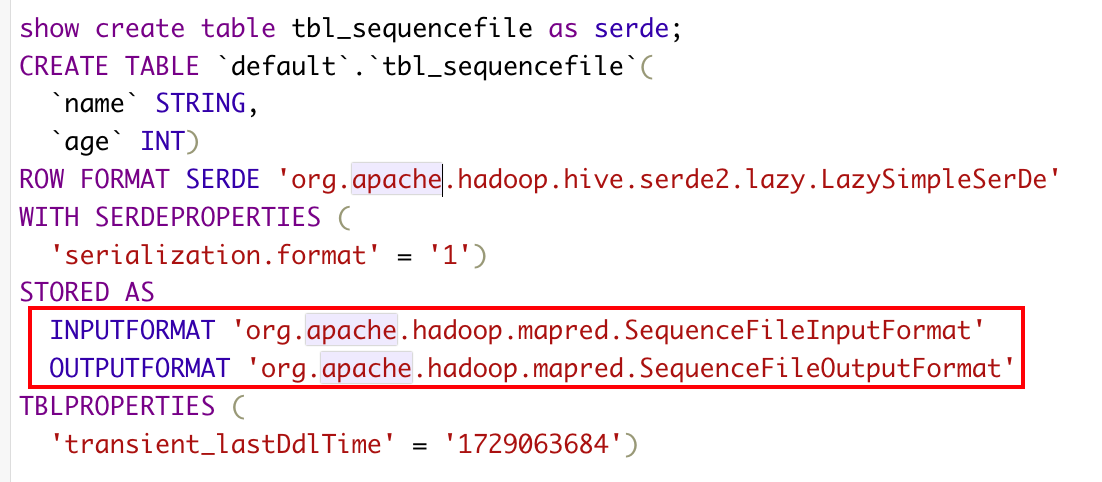
2) Sequencefile
drop table tbl_textfile; CREATE TABLE tbl_sequencefile( name string, age int )stored as sequencefile;
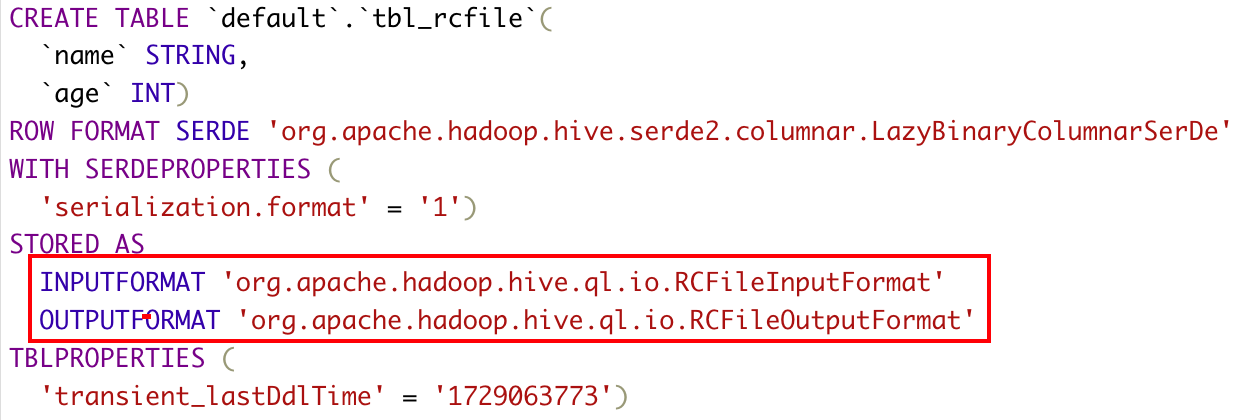
3)rcfile
CREATE TABLE tbl_rcfile( name string, age int )stored as rcfile;
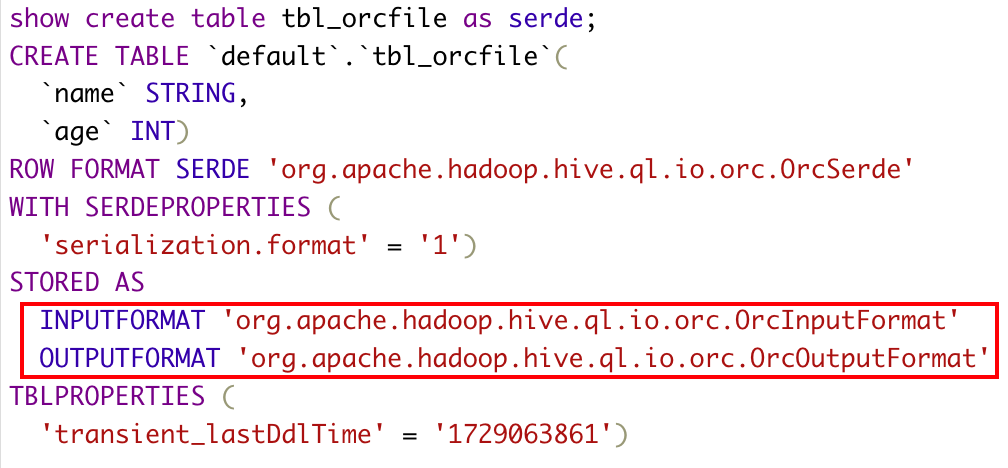
4)orc
CREATE TABLE tbl_orcfile( name string, age int )stored as orc;
5)parquet
CREATE TABLE tbl_parquetfile( name string, age int )stored as parquet;
4.总结
1)查看存储的具体的数据内容,并且数据量较小,可以使用默认文件格式textfile
2)不需要查看具体的数据内容,并且数据量较小,可以使用sequencefile
3)数据量较大,一般推荐orc, 如果需要查询部分列建议使用parquet
参考: https://download.csdn.net/blog/column/9122766/126776080

 浙公网安备 33010602011771号
浙公网安备 33010602011771号