
大数据 之 OLAP 联机分析处理 Online Analytical Processing
除此之外可参考:https://www.cnblogs.com/XiongMaoMengNan/p/7803562.html
一、产生背景
- 随着数据库技术的发展和应用,数据库存储量的增加,涉及的不再是仅查询或操纵一张关系表中的一条或几条记录,而是要对多张表中千万条记录的数据进行数据分析和信息综合,关系数据库已不能全部满足这一要求。
- 操作性应用和分析型应用,特别是在性能上很难两全,人们在关系数据库中放宽了对冗余的限制,引入了统计及综合数据,但这些统计综合数据的应用逻辑是分散而杂乱的、非系统化的,因此分析功能有限,不灵活,维护困难。
二、解决办法
在国外,不少软件商场采取了发展期前端产品来你补关系数据库管理系统支持的不足,他们通过专门的数据库综合引擎,辅之以更加直观的数据访问界面,力图统一分散的公共应用逻辑,在短时间内相应非数据处理专业人员的复杂查询要求。1993年,E.F.Codd(关系数据库之父)将这类技术定义为“联机分析处理”。
三、具体方法
联机处理的主要特点,是直接仿照用户的多角度思考模式,预先为用户组建多维度的数据模型,维,指的是用户的分析角度。例如对销售数据的分析,时间周期是一个维度、产品类别、分销渠道、地理分布等都是维度,一旦多维数据模型建立完成,用户可以快速的从各个角度获取数据,也能动态的在各个角度之间切换或者进行多角度综合分析,具有极大的灵活性。这也是联机分析处理在近年来被广泛关注的根本原因,他从设计理念和真正实现上,都与旧有的管理系统有着本质的区别。
随着数据仓库理论的发展,数据仓库系统已逐渐成为新型的决策管理信息系统的解决方案。数据仓库系统的核心是联机处理。但数据仓库包括的内容更为广泛。概括来说,数据仓库系统是指具有综合企业数据的能力,能够对大量企业数据进行快速和准确分析,辅助做出更好的商业决策系统。
联机分析处理主要包含三个部分:
数据层:实现对企业操作数据的抽取、转换、清晰和汇总,形成信息数据,并存储在企业级的中心信息数据库中。
应用层:通过联机分析处理、甚至是数据挖掘等应用处理,实现对信息数据的分析。
表现层:通过前台分析工具,将查询报表、统计分析、多维联机分析和数据挖掘的结论展现在用户面前。
从应用角度来说,数据仓库系统除了联机分析处理外,还可以采用传统的报表,或者采用数理统计和人工智能等数据挖掘手段,涵盖的范围更广;就应用范围而言,联机分析处理往往根据用户分析的主题进行应用分割,例如:销售分析、市场推广分析、客户利润率分析等等,每一个分析的主题形成一个OLAP应用,而所有的OLAP应用实际上只是数据仓库系统的一部分。
四、典型操作
OLAP展现在用户面前的是一幅幅多维视图。
维(Dimension):是人们观察数据的特定角度,是考虑问题时的一类属性,属性集合构成一个维(时间维、地理维等)。维的层次:如时间维的可以由日期、月份、季度、年等。维的成员:维的一个取值,是数据项在某维中位置的描述,如某年某月某日是在时间维上位置的描述。
度量(Mesasure):多维数组的取值。2000年1月,上海,笔记本电脑,0000)。OLAP的基本多维分析操作有钻取(Drill-Up和Dirll-down)、切片(Slice)和切块(Dice)、以及旋转(Pivot)等。
钻取:是改变维的层次,变换分析的粒度。它包括向下钻取(Drill-down)和向上钻取(Drill-up)/上卷(Roll-up)。Drill-up是在某一维上将低层次的细节数据概括到高层次的汇总数据,或者减少维数;而Drill-down则相反,它从汇总数据深入到细节数据进行观察或增加新维。
切片和切块:是在一部分维上选定值后,关心度量数据在剩余维上的分布。如果剩余的维只有两个,则是切片;如果有三个或以上,则是切块。
旋转:是变换维的方向,即在表格中重新安排维的放置(例如行列互换)。
五、体系结构
数据仓库与OLAP的关系是互补的,现代OLAP系统一般以数据仓库作为基础,即从数据仓库中抽取详细数据的一个子集并经过必要的聚集存储到OLAP存储器中供前端分析工具读取。典型的OLAP系统体系结构如下图所示:
OLAP系统按照其存储器的数据存储格式可以分为关系OLAP(RelationalOLAP,简称ROLAP)、多维OLAP(MultidimensionalOLAP,简称MOLAP)和混合型OLAP(HybridOLAP,简称HOLAP)三种类型。 1.ROLAP
ROLAP将分析用的多维数据存储在关系数据库中并根据应用的需要有选择的定义一批实视图作为表也存储在关系数据库中。不必要将每一个SQL查询都作为实视图保存,只定义那些应用频率比较高、计算工作量比较大的查询作为实视图。对每个针对OLAP服务器的查询,优先利用已经计算好的实视图来生成查询结果以提高查询效率。同时用作ROLAP存储器的RDBMS也针对OLAP作相应的优化,比如并行存储、并行查询、并行数据管理、基于成本的查询优化、位图索引、SQL的OLAP扩展(cube,rollup)等等。
2.MOLAP
MOLAP将OLAP分析所用到的多维数据物理上存储为多维数组的形式,形成“立方体”的结构。维的属性值被映射成多维数组的下标值或下标的范围,而总结数据作为多维数组的值存储在数组的单元中。由于MOLAP采用了新的存储结构,从物理层实现起,因此又称为物理OLAP(PhysicalOLAP);而ROLAP主要通过一些软件工具或中间软件实现,物理层仍采用关系数据库的存储结构,因此称为虚拟OLAP(VirtualOLAP)。
3.HOLAP
由于MOLAP和ROLAP有着各自的优点和缺点(如下表所示),且它们的结构迥然不同,这给分析人员设计OLAP结构提出了难题。为此一个新的OLAP结构——混合型OLAP(HOLAP)被提出,它能把MOLAP和ROLAP两种结构的优点结合起来。迄今为止,对HOLAP还没有一个正式的定义。但很明显,HOLAP结构不应该是MOLAP与ROLAP结构的简单组合,而是这两种结构技术优点的有机结合,能满足用户各种复杂的分析请求。
六、实现方式
同样是仿照用户的多角度思考模式,联机分析处理有三种不同的实现方法:关系型联机分析处理(ROLAP,Relational OLAP);多维联机分析处理(MOLAP ,Mulit-Dimensional OLAP);前端展示联机分析处理(Desktop OLAP).
其中,前端展示联机分析需要将所有数据下载到客户机上,然后在客户机上进行数据结构/报表格式重组,使用户能在本机实现动态分析。该方式比较灵活,然而它能够支持的数据量非常有限,严重的影响了使用的范围和效率,因此,随着时间的推移,这种方式已退居次要地位,在此不作讨论。
Rloap 关系型联机分析处理的具体实施方法:
顾名思义,关系型联机分析处理是以关系型数据库为基础的,唯一的特别之处在于联机分析处理中的数据结构组织的方式。让我们考察一个例子,假设我们要进行产品销售的财务分析,分析的角度包括时间、产品类别、市场分布、实际发生与预算四方面内容,分析的财务指标包括:销售额、销售支出、毛利(=销售额-销售支出)、费用、纯利(=毛利-费用)等内容,则我们可以建立如下的数据结构:
1.该数据结构的中心是主表,里面包含了所有分析维度的外键,以及所有的财务指标,可计算推导出的财务指标不计在内,我们称之为事实表(Fact Table)。
2.周围的表分别是对应于各个分析角度的维表(Dimension Table),每个维表除了外键以外,还包含了描述和分类信息。
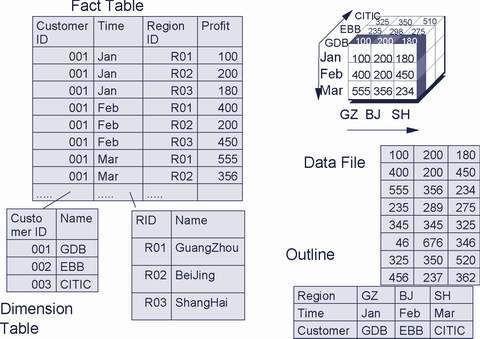
无论原来的业务数据的数据结构为何,只要有原业务数据能够整理成为以上的模式,则无论业务人员据此提出任何问题,都可以用SQL语句进行表连接或汇总(table join and group by )实现数据查询和解答(当然,有一些现成的ROLAP前端分析工具是可以自动根据以上模型生成SQL语句的)。这种模式被称为星型模式(Star-Schema),可应用于不同的联机分析处理应用中。以下是另一个采用星型模式的例子,分析的角度和指标截然不同。但数据结构模式一样,我们看到的不是表的数据,而是表的结构。在练级分析处理的数据模型设计中,这种表达更为常见:
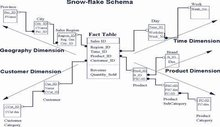
有时候,维表的定义会变得复杂,例如对产品维,既要按产品种类进行划分,对某些特殊商品,又要另外进行品牌划分,商品的品牌和品类划分方法并不一样。因此,单张维表不是理想的解决方案,可以采用以下方式,这种数据模型实际上是星型结构的拓展,我们称之为雪花模型(Snow-flake schema)。
七、MLoap 物理联机分析处理的特点
为什么?
数据结构和组织模式需要预先设计和建立;数据查询需要进行表连接,在查询性能测试中往往是影响速度的关键;数据汇总查询(例如查询某个品牌的所有产品销售额),需要进行Group by 操作,虽然实际得出的数据量很少,但查询时间变得更长;为了改善数据汇总查询的性能,可以建立汇总表,但汇总表的数量与用户分析的角度数目和每个角度的层次数目密切相关。例如,用户从8个角度进行分析,每个角度有3个汇总层次,则汇总表的数目高达3的8次方。
如何解决?
可以采取对常用汇总数据建立汇总表,对不常用的汇总数据进行Group by 操作,这样来取得性能和管理复杂度之间的均衡。 某些客户只通过某些分销渠道才购买,但是只要该客户存在,他在各个月和各个地区内均有消费(例如,华南IBM只通过熊猫国旅定购南航机票,但在华南四省在每个月均有机票订购)。则时间和地区维是密集维,客户和分销渠道是稀疏维,MOLAP将稀疏维建成索引文件(Index File),密集维所对应的数值仍然保留在数据文件中,索引文件不存储空纪录。这样保持了对空间的合理利用。我们也可以看到,如果所有维都是稀疏维,则MOLAP的索引文件就退化成ROLAP的事实表, 两者没有区别了。
在实际应用中,不可能所有分析的维度都是密集的,也绝少存在所有分析的维度都是稀疏的,因此稀疏维和密集维并用的模式几乎主导了所有的MOLAP应用。而稀疏维和密集维的定义全部集中在概要文件中,因此,只要预先定义好概要文件,所有的数据分布就自动确定了。在这种模式中,密集维的组合组成了的数据块(Data Block),每个数据块是I/O读写的基础单位(如上图),所有的数据块组成了数据文件。稀疏维的组合组成了索引文件,索引文件的每一个数据纪录的末尾都带有一个指针,指向要读写的数据块。因此,进行数据查询时,系统先搜索索引文件纪录,然后直接调用指针指向的数据块进行I/O读写(如果该数据块尚未驻留内存),将相应数据块调入内存后,根据密集维的数据放置顺序直接计算出要查询的数据距离数据块头的偏移量,直接提取数据下传到客户端。因此,MOLAP 方式基本上是索引搜索与直接寻址的查询方式相结合,比起ROLAP的表/索引搜索和表连接方式,速度要快得多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号