

Kafka Broker源码解析一:网络层设计
一、简介
- 版本:1.1.1
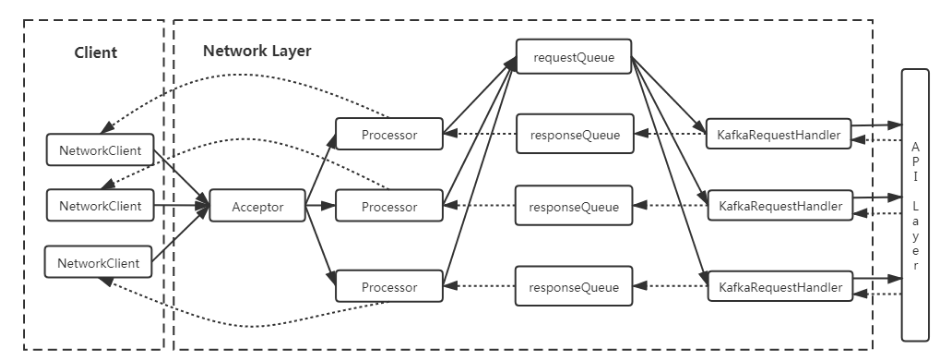
- Kafka网络层是Kafka所有请求的入口,网络模型为NIO实现的多Reactor多线程模型,核心功能是将接受连接、将TCP包转换成Request,传递给API层,处理完后,发送Response
- Github注释版源码:https://github.com/nlskyfree/kafka-1.1.1-sourcecode
二、整体架构
2.1 核心逻辑
- 1个Acceptor线程+N个Processor线程(network.threads)+M个Request Handle线程(io threads)
- 多线程多Reactor模型,Acceptor独占一个selector,每个Processor有自己的selector
- 每个Processor都有一个名为newConnections的ConcurrentLinkedQueue[SocketChannel](),Acceptor会round-robin轮询Processor,将新的连接放入对应Processor的队列里
- 每个Processor有自己的selector,监听网络IO读写事件的发生
- IO读事件发生时,所有Processor会将组包完成后的Request放入RequestChannel中默认大小500的全局ArrayBlockingQueue中
- Request Handle完成kafka内部逻辑后,将Response写到处理Request的Processor线程内的LinkedBlockingQueue中
- IO写事件发生时,将数据写回Client
2.2 核心类、方法介绍
SocketServer //kafka网络层的封装
|-- Acceptor //Acceptor线程的封装
|-- Processor //Processor线程的封装
Selector //对java selector的封装,封装了核心的poll,selectionkeys的遍历,事件的注册等操作
KafkaChannel //对java SocketChannel的封装,封装是实际的读写IO操作
TransportLayer //对KafkaChannel屏蔽了底层是使用Plaintext不加密通信还是ssl加密通信
RequestChannel //和API层通信的通道层,封装了和API层通信的Request、Response以及相应的通信队列
|-- Request //传递给API层的Requst
|-- Response //API层返回的Response
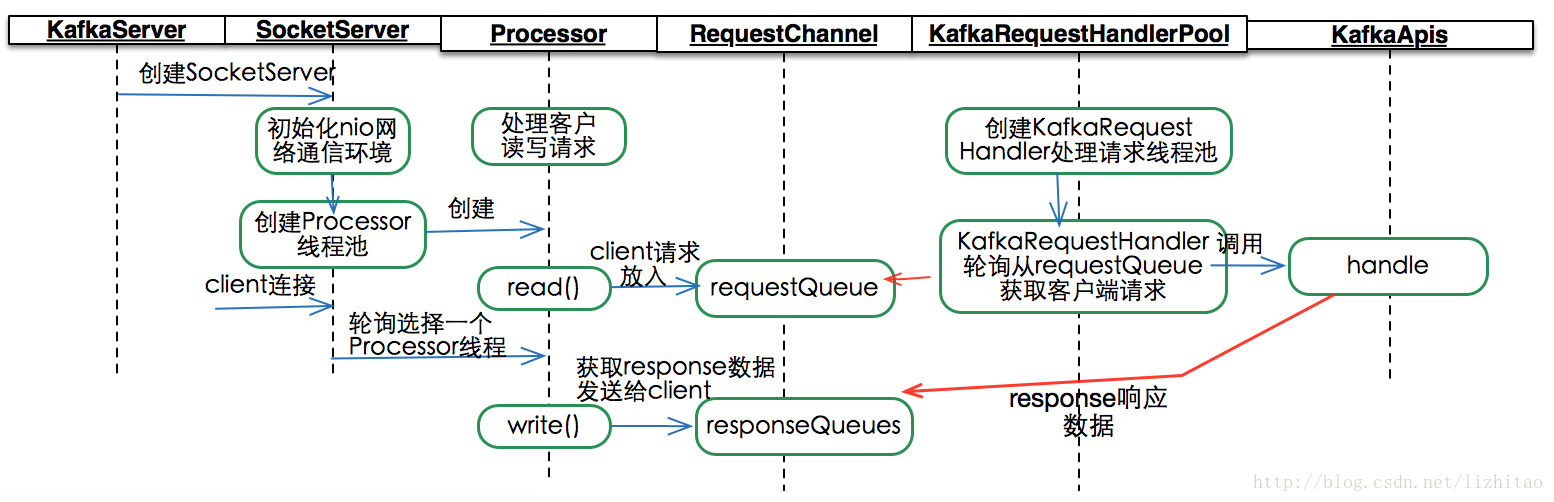
整体流程如图:
三、核心流程分析
3.1 启动流程
// 1. Kafka.scala
def main(args: Array[String]): Unit = {
val serverProps = getPropsFromArgs(args)
val kafkaServerStartable = KafkaServerStartable.fromProps(serverProps)
// 启动Server
kafkaServerStartable.startup()
// 通过countDownLatch阻塞主线程,直到kafka关闭
kafkaServerStartable.awaitShutdown()
}
// 2. KafkaServerStartable.scala
private val server = new KafkaServer(staticServerConfig, kafkaMetricsReporters = reporters)
def startup() {
// 启动Kafka Server
server.startup()
}
// 3. KafkaServer.scala
def startup() {
// 启动socketServer,即Acceptor线程,processor会得到KafkaServer启动完后延迟启动
socketServer = new SocketServer(config, metrics, time, credentialProvider)
socketServer.startup(startupProcessors = false)
// 启动各种其他组件
······
// 启动socketServer中的Processor,开始进行网络IO
socketServer.startProcessors()
}
// 4. SocketServer.scala
def startup(startupProcessors: Boolean = true) {
this.synchronized {
// 创建并启动Acceptor,创建Processor
createAcceptorAndProcessors(config.numNetworkThreads, config.listeners)
if (startupProcessors) {
// 是否立即启动Processor,默认为false
startProcessors()
}
}
}
private def createAcceptorAndProcessors(processorsPerListener: Int,
endpoints: Seq[EndPoint]): Unit = synchronized {
val sendBufferSize = config.socketSendBufferBytes
val recvBufferSize = config.socketReceiveBufferBytes
val brokerId = config.brokerId
// 处理每个Endpoint,一般就是一个
endpoints.foreach { endpoint =>
val listenerName = endpoint.listenerName
val securityProtocol = endpoint.securityProtocol
// 创建Acceptor线程
val acceptor = new Acceptor(endpoint, sendBufferSize, recvBufferSize, brokerId, connectionQuotas)
// 这里只是创建Processor并不启动
addProcessors(acceptor, endpoint, processorsPerListener)
// 非daemon模式启动线程
KafkaThread.nonDaemon(s"kafka-socket-acceptor-$listenerName-$securityProtocol-${endpoint.port}", acceptor).start()
// 阻塞直至线程启动成功
acceptor.awaitStartup()
acceptors.put(endpoint, acceptor)
}
}
def startProcessors(): Unit = synchronized {
// 遍历所有Processor并启动
acceptors.values.asScala.foreach { _.startProcessors() }
}
private[network] def startProcessors(): Unit = synchronized {
// 确保只启动一次
if (!processorsStarted.getAndSet(true)) {
startProcessors(processors)
}
}
// 非Daemon模式启动Processor
private def startProcessors(processors: Seq[Processor]): Unit = synchronized {
processors.foreach { processor =>
KafkaThread.nonDaemon(s"kafka-network-thread-$brokerId-${endPoint.listenerName}-${endPoint.securityProtocol}-${processor.id}",
processor).start()
}
}
KafkaServer启动时,初始化并启动SocketServer
- 创建并运行Acceptor线程,从全连接队列中获取连接,并round-robin交给Processor处理
- 所有组件启动完成后,会启动一定数目的Processor,实际管理SocketChannel进行IO读写
3.2 Acceptor.run流程
Acceptor线程对一个Endpoint只启动一个,核心代码位于Socketserver.scala中的Acceptor类中,此类实现了runnable方法,会由单独线程执行
def run() {
// 注册
serverChannel.register(nioSelector, SelectionKey.OP_ACCEPT)
var currentProcessor = 0
while (isRunning) {
val ready = nioSelector.select(500)
if (ready > 0) {
val keys = nioSelector.selectedKeys()
val iter = keys.iterator()
while (iter.hasNext && isRunning) {
val key = iter.next
// 处理完需要从集合中移除掉
iter.remove()
// round-robin选一个processor
val processor = synchronized {
currentProcessor = currentProcessor % processors.size
processors(currentProcessor)
}
// channel初始化,放入对应processor的newConnection队列
accept(key, processor)
// round robin to the next processor thread, mod(numProcessors) will be done later
currentProcessor = currentProcessor + 1
}
}
}
}
def accept(key: SelectionKey, processor: Processor) {
val serverSocketChannel = key.channel().asInstanceOf[ServerSocketChannel]
val socketChannel = serverSocketChannel.accept()
connectionQuotas.inc(socketChannel.socket().getInetAddress)
// channel初始化
socketChannel.configureBlocking(false)
socketChannel.socket().setTcpNoDelay(true)
socketChannel.socket().setKeepAlive(true)
if (sendBufferSize != Selectable.USE_DEFAULT_BUFFER_SIZE)
socketChannel.socket().setSendBufferSize(sendBufferSize)
// 将连接放入processor的新连接队列
processor.accept(socketChannel)
}
def accept(socketChannel: SocketChannel) {
// accept将新连接放入processor的ConcurrentLinkedQueue中
newConnections.add(socketChannel)
// 唤醒该processor的多路复用器
wakeup()
}
Acceptor做的事情很简单,概括起来就是监听连接,将新连接轮询交给processor:
- 使用多路复用器监听全连接队列里的连接
- 有连接到达后,round-robin轮询processors数组,选择一个processor
- 初始化socketChannel,开启keepalive、禁用nagle算法、设置send buffer
- 将socketchannel放入选中的processor的新连接队列里
3.3 Processor.run流程
Processor线程根据num.network.threads启动对应的线程数,从每个Processor独占的新连接队列中取出新的连接并初始化并注册IO事件。每个Processor有单独的selector,监听IO事件,读事件组包后写入全局requestQueue,写事件从每个Processor独占的responseQueue中获取,再写回Client。
override def run() {
while (isRunning) {
// setup any new connections that have been queued up
// acceptor线程会将新来的连接对应的SocketChannel放入队列,此时消费并向selector注册这些连接,注册读IO事件
configureNewConnections()
// register any new responses for writing
// 从responseQueue中读取准备发送给client的response,封装成send放入channel中,并注册IO写事件
processNewResponses()
/**
* 1. 发生OP_READ事件的channel,若包全部到达,则形成NetworkReceives写入到completedReceives(每个channel只会有一条在completedReceives中)
* 2. 发生OP_WRITE事件的channel,会将channel中暂存的send发出,若发送完成则会写入completedSends
*/
poll()
// 将网络层组包完成后的NetworkReceive转换成Request放入到requestQueue中(后面IO Thread读取)同时mute channel(注销OP_READ事件),保证一个channel同时只有一个请求在处理
processCompletedReceives()
// unmute channel(注册OP_READ事件),之前的request处理完成,此channel开始接受下一个request
processCompletedSends()
// 处理关闭的连接,维护些集合,更新统计信息
processDisconnected()
}
}
Processor run方法的核心逻辑做了很好的封装,从run方法来看线程会一直循环处理以下6个逻辑:
- 从newConenctions队列里取出新的连接,初始化socketChannel,注册OP_READ事件
- 遍历responseQueue所有RequestChannel.Response,封装写入KafkaChannel,做为该Channel下一个待发送的Send,然后在对应的SelectionKey上注册OP_WRITE事件
- poll方法执行核心的NIO逻辑,调用select方法,遍历有事件发生的selectionKeys
- 发生OP_READ事件的channel,若包全部到达,则形成NetworkReceives写入到completedReceives(每个channel只会有一条在completedReceives中)
- 发生OP_WRITE事件的channel,会将channel中暂存的send发出,若发送完成则会写入completedSends
- 遍历completedReceives中的结果,封装成Request,写入全局requestQueue并取消Channel的OP_READ事件监听,待后续IO Thread处理完Response发送成功后,才会重新注册OP_READ
- 遍历completedSends中的结果,向selector重新注册对该Channel的OP_READ事件
- 遍历各种原因down掉的connection,做一些收尾工作,清理一些状态
以下是每一步具体的源码:
3.3.1 configureNewConnections
用于处理Acceptor新交给此Processor的连接
// SocketChannel.scala
private def configureNewConnections() {
while (!newConnections.isEmpty) {
val channel = newConnections.poll()
// 新的连接注册IO读事件,connectionId就是ip+port形成的字符串唯一标志连接使用
selector.register(connectionId(channel.socket), channel)
}
}
// Selector.java
public void register(String id, SocketChannel socketChannel) throws IOException {
// 确保没有重复注册
ensureNotRegistered(id);
// 创建kafkachannel并attach到selectkey上
registerChannel(id, socketChannel, SelectionKey.OP_READ);
}
private SelectionKey registerChannel(String id, SocketChannel socketChannel, int interestedOps) throws IOException {
// 向selector注册
SelectionKey key = socketChannel.register(nioSelector, interestedOps);
// 创建kafka channel并attach到SelectionKey上
KafkaChannel channel = buildAndAttachKafkaChannel(socketChannel, id, key);
this.channels.put(id, channel);
return key;
}
主要完成一些初始化工作
- 遍历newConnections队列,从中取出新连接
- 向Selector注册IO读事件
- 创建KafkaChannel用于封装SocketChannel
- 将KafkaChannel attach到对应的SelectionKey上
3.3.2 processNewResponses
处理已经处理完的Request的Response
// SocketServer.scala
private def processNewResponses() {
var curr: RequestChannel.Response = null
// 读取responseQueue,处理所有返回
while ({curr = dequeueResponse(); curr != null}) {
// 理论上每个channel应该只会被遍历一次,因为一个连接上同时只会有一个Request正在处理
val channelId = curr.request.context.connectionId
curr.responseAction match {
case RequestChannel.NoOpAction =>
// There is no response to send to the client, we need to read more pipelined requests
// that are sitting in the server's socket buffer
updateRequestMetrics(curr)
trace("Socket server received empty response to send, registering for read: " + curr)
// 空请求说明此请求处理完了,此时unmute此KafkaChannel,开始接受请求
openOrClosingChannel(channelId).foreach(c => selector.unmute(c.id))
case RequestChannel.SendAction =>
val responseSend = curr.responseSend.getOrElse(
throw new IllegalStateException(s"responseSend must be defined for SendAction, response: $curr"))
// 注意这里只是将responseSend注册为KafkaChannel的待发送Send并向SelectionKey注册OP_WRITE事件
sendResponse(curr, responseSend)
case RequestChannel.CloseConnectionAction =>
updateRequestMetrics(curr)
trace("Closing socket connection actively according to the response code.")
close(channelId)
}
}
protected[network] def sendResponse(response: RequestChannel.Response, responseSend: Send) {
val connectionId = response.request.context.connectionId
// Invoke send for closingChannel as well so that the send is failed and the channel closed properly and
// removed from the Selector after discarding any pending staged receives.
// `openOrClosingChannel` can be None if the selector closed the connection because it was idle for too long
if (openOrClosingChannel(connectionId).isDefined) {
selector.send(responseSend)
inflightResponses += (connectionId -> response)
}
}
// Selector.java
public void send(Send send) {
String connectionId = send.destination();
KafkaChannel channel = openOrClosingChannelOrFail(connectionId);
// 这里只是设置channel的send,并没有实际发送
channel.setSend(send);
}
public void setSend(Send send) {
// 同时只能有一个send存在
if (this.send != null)
throw new IllegalStateException("Attempt to begin a send operation with prior send operation still in progress, connection id is " + id);
// 设置send
this.send = send;
// transportLayer其实就是对不加密通信、加密通信的封装,增加对OP_WRITE事件的监听
this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);
}
public void addInterestOps(int ops) {
key.interestOps(key.interestOps() | ops);
}
核心逻辑是从responseQueue中获取待发送的response,并作为KafkaChannel下一个待发送Send,再注册OP_WRITE事件
- 遍历responseQueue,获取已经处理完的Response
- 判断Response是否为空,为空,unmute channel,注册OP_READ,等待下一个Request,不为空调用sendResponse发送Response
- 将当前待发送Response封装成Send,绑定到KafkaChannel上,一次只能有一个待发送Send(一次也只处理一个Request)
- 注册OP_WRITE事件,事件发生时,才实际发送当前Send
3.3.3 poll
实际调用select,并对发生的IO事件进行处理的方法
// SocketServer.scala
private def poll() {
selector.poll(300)
}
// selector.java
public void poll(long timeout) throws IOException {
if (timeout < 0)
throw new IllegalArgumentException("timeout should be >= 0");
boolean madeReadProgressLastCall = madeReadProgressLastPoll;
clear();
boolean dataInBuffers = !keysWithBufferedRead.isEmpty();
if (hasStagedReceives() || !immediatelyConnectedKeys.isEmpty() || (madeReadProgressLastCall && dataInBuffers))
timeout = 0;
if (!memoryPool.isOutOfMemory() && outOfMemory) {
//we have recovered from memory pressure. unmute any channel not explicitly muted for other reasons
log.trace("Broker no longer low on memory - unmuting incoming sockets");
for (KafkaChannel channel : channels.values()) {
if (channel.isInMutableState() && !explicitlyMutedChannels.contains(channel)) {
channel.unmute();
}
}
outOfMemory = false;
}
/* check ready keys */
long startSelect = time.nanoseconds();
int numReadyKeys = select(timeout);
long endSelect = time.nanoseconds();
this.sensors.selectTime.record(endSelect - startSelect, time.milliseconds());
// 有IO事件发生或有immediatelyConnect发生或上次IO事件发生时channel数据没有读完
if (numReadyKeys > 0 || !immediatelyConnectedKeys.isEmpty() || dataInBuffers) {
Set<SelectionKey> readyKeys = this.nioSelector.selectedKeys();
// Poll from channels that have buffered data (but nothing more from the underlying socket)
if (dataInBuffers) {
keysWithBufferedRead.removeAll(readyKeys); //so no channel gets polled twice
Set<SelectionKey> toPoll = keysWithBufferedRead;
keysWithBufferedRead = new HashSet<>(); //poll() calls will repopulate if needed
pollSelectionKeys(toPoll, false, endSelect);
}
// 遍历selectionKey处理IO读写事件,读完的数据放入stagedReceive。同时将KafkaChannel中的Send写出
// Poll from channels where the underlying socket has more data
pollSelectionKeys(readyKeys, false, endSelect);
// Clear all selected keys so that they are included in the ready count for the next select
readyKeys.clear();
pollSelectionKeys(immediatelyConnectedKeys, true, endSelect);
immediatelyConnectedKeys.clear();
} else {
madeReadProgressLastPoll = true; //no work is also "progress"
}
long endIo = time.nanoseconds();
this.sensors.ioTime.record(endIo - endSelect, time.milliseconds());
// 处理空闲的连接,默认10min,超时的连接会被断开
// we use the time at the end of select to ensure that we don't close any connections that
// have just been processed in pollSelectionKeys
maybeCloseOldestConnection(endSelect);
// 从stagedReceives中每个channel取一条NetworkReceives放入到CompletedReceived
// Add to completedReceives after closing expired connections to avoid removing
// channels with completed receives until all staged receives are completed.
addToCompletedReceives();
}
private int select(long timeoutMs) throws IOException {
if (timeoutMs < 0L)
throw new IllegalArgumentException("timeout should be >= 0");
if (timeoutMs == 0L)
return this.nioSelector.selectNow();
else
return this.nioSelector.select(timeoutMs);
}
void pollSelectionKeys(Set<SelectionKey> selectionKeys,
boolean isImmediatelyConnected,
long currentTimeNanos) {
// determineHandlingOrder对key集合做了shuffle,避免发生饥饿
for (SelectionKey key : determineHandlingOrder(selectionKeys)) {
KafkaChannel channel = channel(key);
long channelStartTimeNanos = recordTimePerConnection ? time.nanoseconds() : 0;
// 更新channel的过期时间
if (idleExpiryManager != null)
idleExpiryManager.update(channel.id(), currentTimeNanos);
boolean sendFailed = false;
// 从channel读数据到stagedReceive,若stagedReceive有数据,说明已形成完整Request,不再继续读
attemptRead(key, channel);
// 只有ssl通信时才可能为true
if (channel.hasBytesBuffered()) {
keysWithBufferedRead.add(key);
}
// 往channel写数据
/* if channel is ready write to any sockets that have space in their buffer and for which we have data */
if (channel.ready() && key.isWritable()) {
Send send = null;
try {
// 将channel中的send发送出去,如果发送完成,则注销OP_WRITE事件
send = channel.write();
} catch (Exception e) {
sendFailed = true;
throw e;
}
if (send != null) {
// 添加到completedSends集合中
this.completedSends.add(send);
}
}
}
}
调用select,对OP_READ、OP_WRITE事件进行响应,处理IO读写
- 调用select方法,获取发生IO事件的SelectionKey
- 有IO事件发生或有immediatelyConnect发生或上次IO事件发生时channel数据没有读完,对对应的keys调用pollSelectionKeys
- 遍历SelectionsKeys
- 调用atemptRead进行实际的channel读取
- 若发生OP_WRITE事件,调用channel.write将channel绑定的当前Send写出,若数据全部发送完成,则将该Send放入CompletedReceive,并注销OP_WRITE事件
- 处理长时间空闲的连接,默认10m,关闭超时的连接
- 将stagedReceives中的networkReceive移动到completeReceives
attemptRead封装了实际的channel读操作
private void attemptRead(SelectionKey key, KafkaChannel channel) throws IOException {
//if channel is ready and has bytes to read from socket or buffer, and has no
//previous receive(s) already staged or otherwise in progress then read from it
if (channel.ready() && (key.isReadable() || channel.hasBytesBuffered()) && !hasStagedReceive(channel)
&& !explicitlyMutedChannels.contains(channel)) {
NetworkReceive networkReceive;
// channel.read返回不为null则代表读到一个完的Request
while ((networkReceive = channel.read()) != null) {
madeReadProgressLastPoll = true;
addToStagedReceives(channel, networkReceive);
}
// 这里mute了,一定是channel.read()内由于memorypool内存不够,才会mute
if (channel.isMute()) {
outOfMemory = true; //channel has muted itself due to memory pressure.
} else {
madeReadProgressLastPoll = true;
}
}
}
// KafkaChannel.java
public NetworkReceive read() throws IOException {
NetworkReceive result = null;
if (receive == null) {
receive = new NetworkReceive(maxReceiveSize, id, memoryPool);
}
// 从channel里读取数据,内部实际调用的readFromReadableChannel()
receive(receive);
// 如果读完了,形成一个完整的Request
if (receive.complete()) {
receive.payload().rewind();
result = receive;
receive = null;
} else if (receive.requiredMemoryAmountKnown() && !receive.memoryAllocated() && isInMutableState()) {
//pool must be out of memory, mute ourselves.
mute();
}
return result;
}
// NetworkReceive.java
// 这里的实现和zookeeper网络层很像,也是前4个字节传递payload大小,然后创建指定大小buffer读取数据
public long readFromReadableChannel(ReadableByteChannel channel) throws IOException {
int read = 0;
// size为4个字节大小的bytebuffer,这里没读满,说明头4个字节还没拿到
if (size.hasRemaining()) {
int bytesRead = channel.read(size);
if (bytesRead < 0)
throw new EOFException();
read += bytesRead;
if (!size.hasRemaining()) {
size.rewind();
// 实际的Request大小
int receiveSize = size.getInt();
if (receiveSize < 0)
throw new InvalidReceiveException("Invalid receive (size = " + receiveSize + ")");
if (maxSize != UNLIMITED && receiveSize > maxSize)
throw new InvalidReceiveException("Invalid receive (size = " + receiveSize + " larger than " + maxSize + ")");
requestedBufferSize = receiveSize; //may be 0 for some payloads (SASL)
if (receiveSize == 0) {
buffer = EMPTY_BUFFER;
}
}
}
// 说明头4个字节读完了
if (buffer == null && requestedBufferSize != -1) { //we know the size we want but havent been able to allocate it yet
// 分配缓冲区内存,memorypool用于控制网络层缓冲区大小,默认为无限大
buffer = memoryPool.tryAllocate(requestedBufferSize);
if (buffer == null)
log.trace("Broker low on memory - could not allocate buffer of size {} for source {}", requestedBufferSize, source);
}
if (buffer != null) {
// 实际读取payload
int bytesRead = channel.read(buffer);
if (bytesRead < 0)
throw new EOFException();
read += bytesRead;
}
return read;
}
若发生OP_READ事件,调用channel.read直到读到完整的networkReceive,并放入stagedReceive
- 先读取4个字节size,为整个payload大小
- 再读取size个字节,读完后形成的networkReceive为一个完整的Request,放入stagedReceive
channel.write封装了实际的channel写数据逻辑
// KafkaChannel.java
public Send write() throws IOException {
Send result = null;
if (send != null && send(send)) {
result = send;
send = null;
}
return result;
}
private boolean send(Send send) throws IOException {
// 这里根据不同send,实际底层API不同,如RecordsSend底层使用了零拷贝,而ByteBufferSend使用正常channel write
send.writeTo(transportLayer);
// 是否完成,通过读到的字节数是否达到request的前4个字节对应的大小
if (send.completed())
// 发送完成,则注销OP_WRITE事件
transportLayer.removeInterestOps(SelectionKey.OP_WRITE);
return send.completed();
}
// RecordsSend.java
public long writeTo(GatheringByteChannel channel) throws IOException {
long written = 0;
// 是否未发送完
if (remaining > 0) {
// 发送剩余的bytes
written = records.writeTo(channel, size() - remaining, remaining);
if (written < 0)
throw new EOFException("Wrote negative bytes to channel. This shouldn't happen.");
remaining -= written;
}
pending = TransportLayers.hasPendingWrites(channel);
if (remaining <= 0 && pending)
channel.write(EMPTY_BYTE_BUFFER);
return written;
}
// FileRecords.java
public long writeTo(GatheringByteChannel destChannel, long offset, int length) throws IOException {
long newSize = Math.min(channel.size(), end) - start;
int oldSize = sizeInBytes();
if (newSize < oldSize)
throw new KafkaException(String.format(
"Size of FileRecords %s has been truncated during write: old size %d, new size %d",
file.getAbsolutePath(), oldSize, newSize));
long position = start + offset;
int count = Math.min(length, oldSize);
final long bytesTransferred;
if (destChannel instanceof TransportLayer) {
TransportLayer tl = (TransportLayer) destChannel;
// 实际内部也是零拷贝实现,调用了channel.transferTo
bytesTransferred = tl.transferFrom(channel, position, count);
} else {
// 零拷贝, 将本地文件拷贝到网卡
bytesTransferred = channel.transferTo(position, count, destChannel);
}
return bytesTransferred;
}
Kafka的发送逻辑,依据Send的不同子类有不同实现,这里只列举了RecordSend的代码,使用零拷贝技术将磁盘文件拷贝给网卡
- 判断是否有待发送Send,若有向transportLayer写出此Send
- 若是以下两种场景,则Send为RecordsSend(代表磁盘文件数据),则调用对应的writeTo方法向channel写数据
- consumer消费partition中的消息
- replica 的follower从leader拉取消息进行同步
- RecordsSend使用channel.transferTo进行零拷贝,将数据拷贝到网卡
- 若是以下两种场景,则Send为RecordsSend(代表磁盘文件数据),则调用对应的writeTo方法向channel写数据
- 如果发送成功,注销OP_WRITE的监听(因为Java NIO是ET模式,否则会一直触发OP_WRITE)
3.3.4 processCompletedReceives
处理completedReceives中的NetworkReceive,封装成Request放入RequestChannel的全局requestQueue中,供API层调用
private def processCompletedReceives() {
selector.completedReceives.asScala.foreach { receive =>
// 根据connectionId获取Channel
openOrClosingChannel(receive.source) match {
case Some(channel) =>
val header = RequestHeader.parse(receive.payload)
val context = new RequestContext(header, receive.source, channel.socketAddress,
channel.principal, listenerName, securityProtocol)
val req = new RequestChannel.Request(processor = id, context = context,
startTimeNanos = time.nanoseconds, memoryPool, receive.payload, requestChannel.metrics)
requestChannel.sendRequest(req)
// 注销OP_READ事件监听,保证一个连接来的请求,处理完后才会处理下个请求,因此保证单个连接请求处理的顺序性
selector.mute(receive.source)
case None =>
// This should never happen since completed receives are processed immediately after `poll()`
throw new IllegalStateException(s"Channel ${receive.source} removed from selector before processing completed receive")
}
}
}
1. 遍历completedReceives中的networkReceive,从payload中提取数据封装成RequestChannel.Request放入RequestChannel的全局requestQueue中
2. mute对应的KafkaChannel,即在对应selectionKey上注销OP_READ事件(原因第三章详解)
3.3.5 processCompletedSends
处理已完成发送的Response,遍历CompletedSends,unmute对应的KafkaChannel,即重新在对应selectionKey上注册OP_READ事件,接收下一个Request
private def processCompletedSends() {
selector.completedSends.asScala.foreach { send =>
val resp = inflightResponses.remove(send.destination).getOrElse {
throw new IllegalStateException(s"Send for ${send.destination} completed, but not in `inflightResponses`")
}
updateRequestMetrics(resp)
// response发送完成,unmute channel,重新监听OP_READ事件
selector.unmute(send.destination)
}
}
// selector.scala
public void unmute(String id) {
KafkaChannel channel = openOrClosingChannelOrFail(id);
unmute(channel);
}
private void unmute(KafkaChannel channel) {
explicitlyMutedChannels.remove(channel);
channel.unmute();
}
// kafkaChannel.scala
void unmute() {
if (!disconnected)
transportLayer.addInterestOps(SelectionKey.OP_READ);
muted = false;
}
3.3.6 processDisconnected
若连接已关闭,从inflightResponses集合中移除,并减少对应的限流统计信息
private def processDisconnected() {
selector.disconnected.keySet.asScala.foreach { connectionId =>
val remoteHost = ConnectionId.fromString(connectionId).getOrElse {
throw new IllegalStateException(s"connectionId has unexpected format: $connectionId")
}.remoteHost
inflightResponses.remove(connectionId).foreach(updateRequestMetrics)
// the channel has been closed by the selector but the quotas still need to be updated
connectionQuotas.dec(InetAddress.getByName(remoteHost))
}
}
四、其它细节
单个连接的顺序性保证
Processor每接受到一个完整的Request就会再selector上取消监听OP_READ事件,直到Response发送完成后才会重新监听OP_READ事件,从而保证单个连接的Channel上,Server端请求是严格按照到达顺序处理的。
为什么有transportLayer?
主要是封装Plaintext通信与ssl通信,对于Plaintext不加密通信,本质transportLayer没做任何处理,而对ssl通信,transportLayer对Kafka通信协议屏蔽了握手、加解密等操作
为什么要有stagedReceives,而不是直接放入compeletedReceived?
- 主要是由于SSL加密通信时,无法得知准确的数据长度(前4位加密后不知道多长了),例如:一次OP_READ读到,2个Request,此时需要将这个2个Request都存入stagedReceives(因此每个channel一个队列),然后一个一个处理(保障顺序)。具体也可参考第2点git commit中的对话
- 这块设计的确实不好,后续Kafka移除了stagedReceived,代码更加简洁https://github.com/apache/kafka/pull/5920/commits
为什么RequestQueue是单个队列,不会有锁冲突问题吗?
因为kafka每次处理的数据是一批,实际一批数据才会竞争一次锁,获取锁开销平均下来并不大。腾讯云曾尝试优化这里为无锁队列,实际IO性能并没有显著提高。
MemoryPool作用?
为了限制网络层buffer带来的内存使用量,由queued.max.request.bytes配置,默认无限大,不做限制
零拷贝实现?
可以看到Kafka网络层的通信并不是任何时候都使用零拷贝进行通信,只有涉及到消息磁盘文件上的消息数据时,才会使用零拷贝提升效率,带来的问题是,从磁盘到网卡之间不能进行任何数据处理。其它场景如:数据写入,内存元数据返回都不会使用到零拷贝。
图片引自:https://blog.csdn.net/lizhitao/article/details/43987319

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步