
【论文总结】MapReduce论文
摘要:
- MR是啥:编程模型,用户只需编写Map,Reduce两个函数,系统完成分布式计算
- MR系统是啥:在大量普通计算机上实现并行化计算,系统只关心如何分割数据、大规模集群的调度、集群容错、集群通信
- MR在Google的并行处理能力:上千台机器上,处理TB级数据
介绍:
- 问题:海量数据、数据分发、并行计算、容错,开发、维护复杂,且不可复用
- 核心:技术问题---》制约业务开发
- 解决:封装分布式处理的所有细节,提供统一的计算模型(MapReduce)
- 为什么是MapReduce:来源Lisp,函数式编程的Map、Reduce原语,能解决Google绝大多数问题
实现:
执行过程
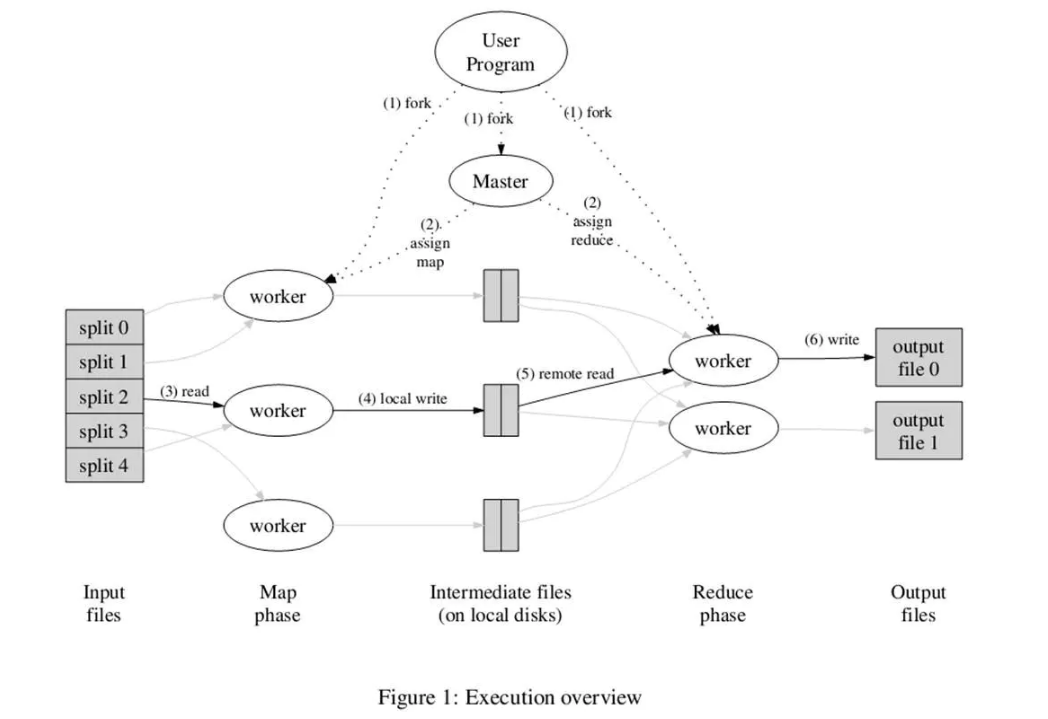
- 输入文件按照大小split成M份(16-64M),分发程序副本到各个worker上
- master控制任务流程,将M个Map任务与N个Reduce任务(用户指定输出桶数)分配给空闲的worker执行
- map任务读取输入split,将输入key/value传递给Map函数,产生中间key/value,并缓存在内存中、
- 缓存中的key/value通过分区函数分成R个桶,并周期性写到本地磁盘中。中间结果再磁盘中的位置会告知master,再由master告知reduce任务
- Reduce worker接收到master发来的存储位置后,RPC读取磁盘中的中间结果。不同map的中间结果虽然有序,但全局无序,所以当所有中间结果读取完后,会进行全局排序(内存排序,不够会外排)。
- Reduce worker读取排序后的结果。对每一个key值,与中间value集合会调用一次reduce函数。reduce的输出会被追加到所属桶的输出文件中。
- 当所有map任务、reduce任务完成后,master唤醒用户程序,调用返回。
- 若存在后续计算,可将当前输出的N个文件作为下一个MapReduce任务的输入。
容错
MapReduce通常在上千台机器组成的集群上运行,所以发生机器故障是常态
master故障
Master存储了每一个Map和Reduce任务的状态(空闲、工作中、完成),以及Worker机器数,以及其状态
中间文件的存储位置通过Master从Map传递到Reduce。对于每个已完成的Map任务,Master存储了Map任务产生的R个中间文件存储的大小和位置
当Map任务完成时,Master接收到位置和大小更新信息,这些信息被逐步递增的推送给那些正在工作的Reduce任务
- Master周期性将上述数据结构写入磁盘,即检查点(checkpoint)。可以从最后一个检查点开始启动另外一个Master进程。Master失效再恢复是比较麻烦的,因此当前实现是,如果Master失效,就终止MapReduce运算。
worker故障
- Master周期性ping每个worker。如果在一个约定时间没收到worker返回的信息,Master将这个worker标记为失效。所有由这个失效的worker完成的Map任务被重设为空闲。同样,worker失效时正在运行的Map或Reduce任务也将被重置了空闲状态,等待被重新调度
备用任务
影响一个MapReduce任务的总执行时间最通常的因素是“落伍者”:由于机器资源不均衡,可能某几台机器上的Map或Reduce任务花了很长时间才完成。比如磁盘老化,读写速度很慢,由比如此机器负载较高。
- 当一个MapReduce操作解决完成的时候,Master调度备用的任务进程来执行剩下的处于处理中状态的任务。最后无论最初的执行进程、还是备用的执行进程完成了任务,我们都标记为已完成。(部分实验效率提升了44%)
技巧
- M根据输入拆分成饿了M个片段,Reduce拆分成R个片段执行。理想情况下M+R应当远大于worker数目(有利于动态负载均衡),但事实上Master需要执行O(M+R)次调度,保存O(M*R)个状态,因此要考虑Master负载
- 移动计算,本地计算或同一个交换机类通信,尽量减少网络传输
- 通过写临时文件,rename临时文件避免读到中间状态的文件数据
- partition函数:通过hash(key) mod R 进行负载均衡。也可以使用hash(hostname(urlkey))来保证相同主机的key落到同一个分区
- Combiner函数:可选,是否先进行本地合并,本质等同于Reduce函数,减少网络传输
- 自定义输入输出类型:输入输出的类型,自定义数据来源,数据分割方式,输出同理
- 跳过损坏的记录:MapReduce设置了信号函数捕获内存段异常和总线错误,通过全局保存记录序号。如果特定记录不止失败一次,则master标记该记录需要跳过,并在下次重新执行Map、Reduce任务时跳过
- standalone本地调试:本地顺序执行MapReduce任务,方便调试
- 状态信息:监控各种执行状态。已经完成多少任务、有多少任务在处理、输入字节数、输出字节数、处理百分比等等
- 自定义计数器:统计不同事件发生的次数。比如想查看当前已经处理了多少个单次,这些计数器的值通过worker到master的ping包中传递
总结
- MapReduce封装了并行计算、容错、数据本地化优化、负载均衡等技术难点细节
- 大量不同类型的问题都可以通过MapReduce解决(抽象的计算模型)
- 数千台机器的大型集群上运行MapReduce
- 约束式编程使得并行和分布式计算非常容易,也易于构建容错的计算资源
- 网络带宽是稀缺资源,需大量针对性优化,从本地磁盘读取(移动计算)
- 多次执行相同任务来减少性能缓慢的机器带来的负面影响
疑惑的解答:
- 为什么是Map、Reduce函数,能数学上证明所有问题能分解成Map、Reduce任务吗?
- 这么做只是起源于函数式编程,又能解决Google内部的计算问题。
- 提供最简单的抽象,能极大的简化分布式系统的并行计算、容错等设计
- MapReduce为什么具有划时代的意义?(当时也就Oracle设计了最多 32台机器的并行数据库)
数千台廉价机器的大规模并行计算,Google证明了这条路的可行性,设计了完整的容错方案
- MapReduce为什么还需要我写代码,提交jar包,这么“难”使用?
- 当时只是Google为了解决一些很简单的计算任务,并且主要时为了隐藏了分布式实现的细节,因此这个使用方式以及“满足”了Google的场景
- 目前其实各种查询引擎已经屏蔽了这些细节,无需再关注实际如何写MapReduce
- MapReduce执行流程为什么是这样的?为什么必须按key排序?
因为当初Google的内部问题大部分需要排序,Doug Cutting就是看论文照着抄的
SQL转MapReduce案例
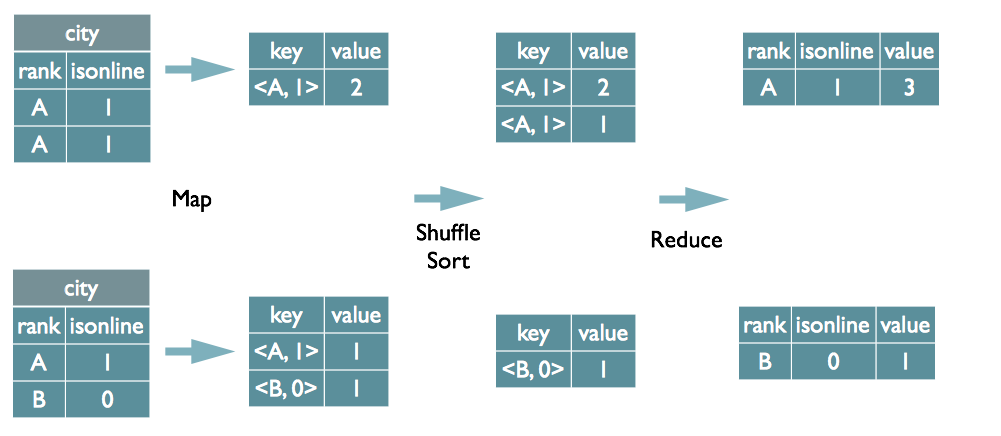
Group By案例
select rank, isonline, count(*) from city group by rank, isonline;
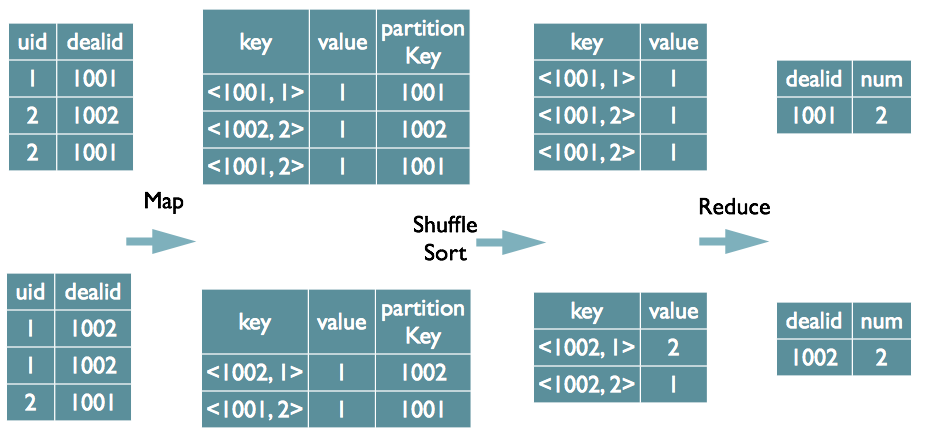
Distinct案例
select dealid, count(distinct uid) num from order group by dealid;
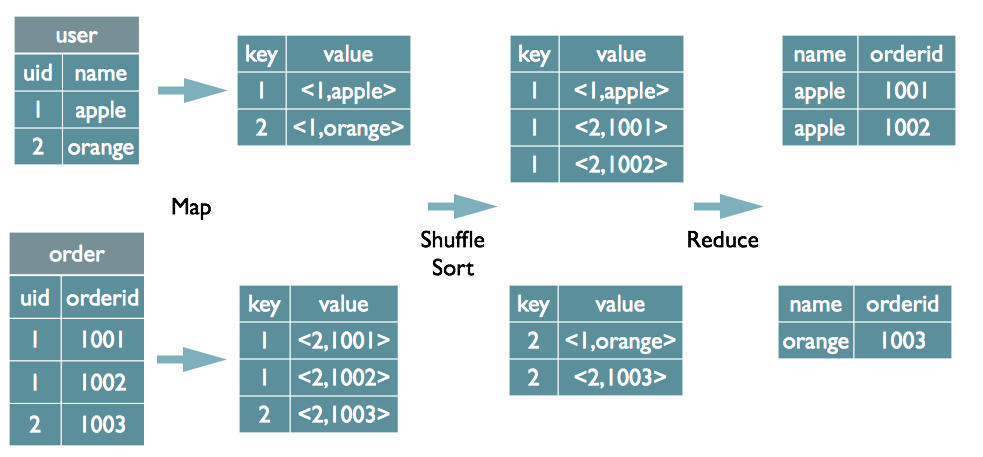
JOIN案例
select u.name, o.orderid from order o join user u on o.uid = u.uid;
参考资料:
https://tech.meituan.com/2014/02/12/hive-sql-to-mapreduce.html
