adaptive softmax
词表过大用到了adaptive softmax
但是不知其原理
引用来源https://mp.weixin.qq.com/s/OBkEsjNBJaYws8UQbZ9B0A
要想弄明白还是看原文Efficient softmax approximation for GPUs
论文中提到:
损失函数近似。分层Softmax (HSM)是Goodman (2001a)引入的Softmax函数的近似。这种方法通常用于两级树(Goodman, 2001a;Mikolov等人,2011c),但也被扩展到更深层次的层次(Morin & Bengio, 2005;Mnih & Hinton, 2009)。一般来说,层次结构建立在词的相似性上(Brown et al., 1992;Le等人,2011;Mikolov et al., 2013)或频率宾(Mikolov et al., 2011c)。Mikolov et al.(2013)通过构建基于频率的霍夫曼编码提出了最优层次结构。
然而,这种编码方案没有考虑到矩阵-矩阵乘法和分布式计算所带来的理论复杂性降低,特别是在现代gpu中。
既然提到了分层softmax 那找一篇帖子再熟悉一下:
https://blog.csdn.net/weixin_55073640/article/details/123470736
https://blog.csdn.net/weixin_55073640/article/details/122762817
突然有点懵啊 为撒霍夫曼编码降低了这个维度呢?
3. Adaptive Softmax
对softmax层的优化一直是自然语言处理领域研究的重点。这个方向的研究很多,常用的技术包括基于采样的方法[4],基于树的方法[5]等等。这里我们使用facebook提出的adaptive softmax[6]进行优化。之所以选择adaptive softmax,一方面是因为其是针对GPU进行的优化。我们在多机多GPU上进行预训练,使用adaptive softmax能帮助我们在效率上得到显著的提升。另一方面,adaptive softmax可以节约显存,这是我们引入大词典的关键。下面简要介绍adaptive softmax的原理。
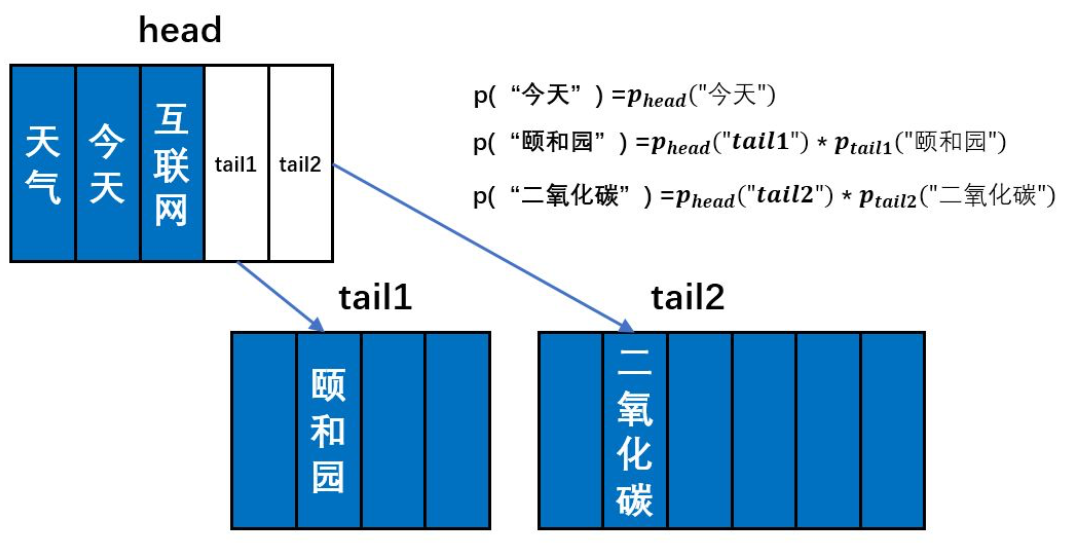
如上图所示,如果我们将词典分成三个部分,那么adaptivesoftmax则由三个前向神经网络构成,我们分别称之为head、tail1、tail2。第一个词典会链到第二和第三个词典。我们根据词频对词语进行排序,令head前向神经网络去预测高频词语;tail1去预测中间频率的词语;tail2去预测低频词语。(这个图画的很清晰啊)
因为高频词占据了语料中绝大部分的频数(Zipf’s Law),所以在大多数情况下,我们只需要用head这个规模较小的前向神经网络去做预测,这很大程度上减少了计算量。当遇到低频词的时候(比如上图中的“二氧化碳”),模型先使用head去预测,发现“tail2”的概率值最大,这表明需要继续使用tail2前向神经网络去预测。然后我们得到tail2前向神经网络对于“二氧化碳”的预测值之后,让其与head的“tail2”位置的概率值相乘,就能得到“二氧化碳”这个词的预测概率。在具体实现中,tail1和tail2一般是两层的前向神经网络,中间隐层维度设为一个较小的值,从而实减少模型的参数。下图是PyTorch实现的一个adaptive softmax的示例。词典大小为50万。

可以看到,中间频率的词语的向量维度是192;低频词语的向量维度是48。相对于原来的参数量,adaptive softmax参数减少了500000*768-37502*768-62500*192-400000*48-768*768-192*768-48*768 = 323224320个,相当于原来参数量的84.2%。在使用adaptive softmax之后,词典的规模可以从8万扩展到50万。50万词典已经可以覆盖绝大部分常见词,能有效的减少OOV的情况。
4. Adaptive Input
"""
代码解读https://blog.csdn.net/ACM_hades/article/details/104543812
"""
Softmax层一定程度上可以看作embedding层的镜像。因此可以把softmax上的优化操作搬到embedding层。在今年的ICLR上facebook提出了adaptive input方法[7]。下面简要介绍adaptive input的原理。
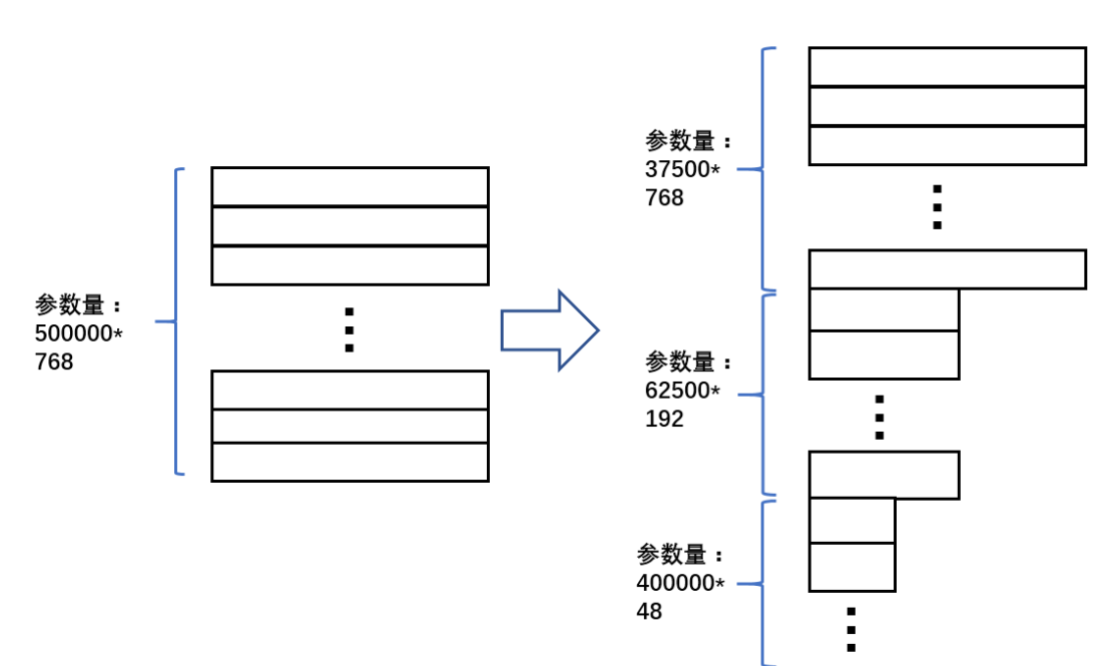
如上图所示,adaptive input对高频词使用较大的维度,对低频词使用较小的维度。更具体的,上图把50万词语按照词频排好序,并分成三个部分:第一部分包括37500个高频词语,词向量维度为768;第二部分包括62500个中间频率的词语,词向量维度为192;第三部分包括40万个低频词语,词向量维度为48。为了使维度可以统一到隐层维度,这里引入了三个不同的前向神经网络,把不同维度的词向量映射到相同的维度。经过计算,我们可以得到adaptive input 减少的参数量是500000*768-37500*768-62500*192-400000*48-768*768-192*768-48*768= 323225856,相当于原来的参数量的84.2%。当模型同时引入adaptive softmax和adaptive input的时候,词典可以进一步扩展到100万。
5. 动态词典
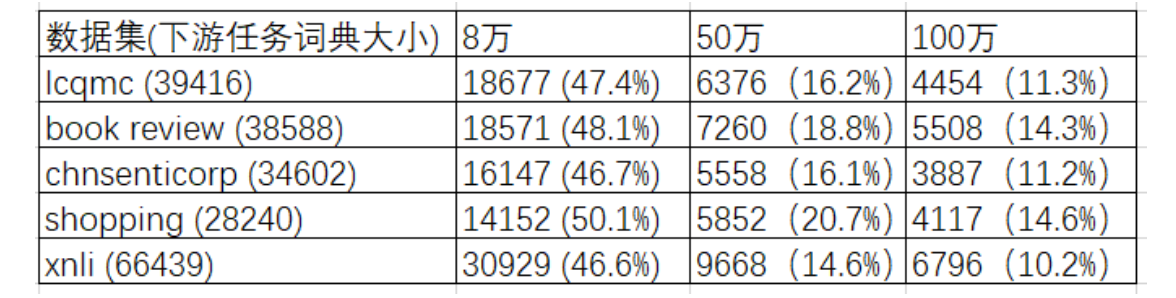
谷歌BERT模型使用固定的词典,即对不同的语料和下游任务,均只使用一个词典。这对基于字的模型是合理的。因为中文字的数量有限,使用谷歌提供的大小为21128的词典不会有OOV的问题。但是对于基于词的BERT模型,使用固定词典则会有严重的问题。下表展示了使用中文维基百科作为预训练语料,在多个下游任务上的OOV词语数量以及OOV词语数量占总词典大小的百分比。其中第一列展示了不同下游任务数据集的名称以及对应的词典大小,第二、三、四列展示了不同大小的维基百科词典与下游任务数据词典相比较时的OOV在下游任务数据集的占比。可以看到,大词典有效的缓解了OOV的问题。但是即使词典扩大到100万,仍然有很多未登录词
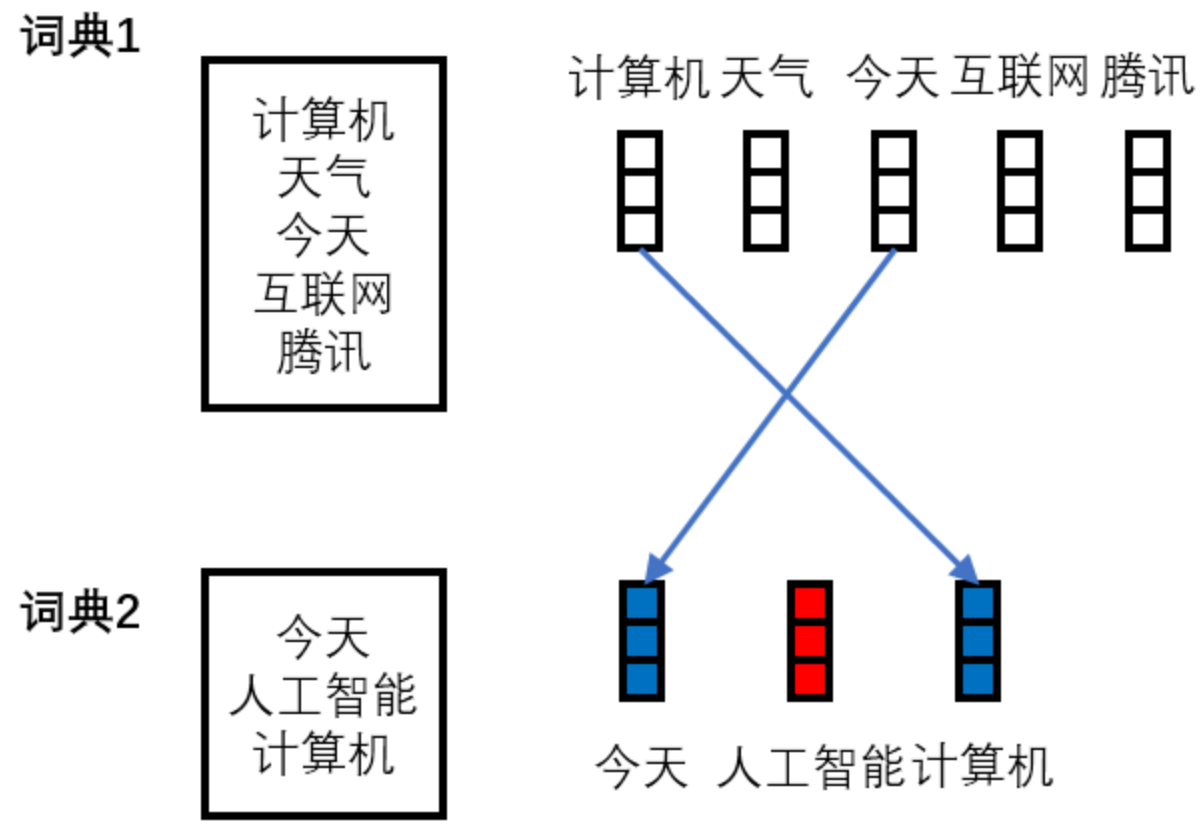
因此,对于基于词的BERT模型,无论是用新的语料进行叠加预训练,还是针对下游任务进行微调,我们都需要生成新的词典(动态词典),并根据新的词典去对预训练模型的embedding层和softmax层进行调整。调整的方式如下图所示(蓝色表示根据预训练模型的参数初始化,红色表示随机初始化)。如果使用固定词表,那么词语“人工智能”会被映射到UNK,这个词语无法在下游任务上进行训练。对于加入adaptive机制的模型,调整的过程会增加一些步骤。后面实验中基于词的BERT模型均默认使用动态词典。动态词典相对于固定词典在效果上有着显著的提升。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号