用Bert的attention对角线mask 来代替 [mask]导致loss为0问题
自己实习的时候遇到这个问题,需要对用到mlm的任务方式,一开始采用了对attention矩阵进行对角线mask的方式,但是训练出现泄漏了,loss很快到了0.
内容来源:https://zhuanlan.zhihu.com/p/453420634
https://www.zhihu.com/question/318355038
自己加以整理
让我们先看一下 attention的计算方式。
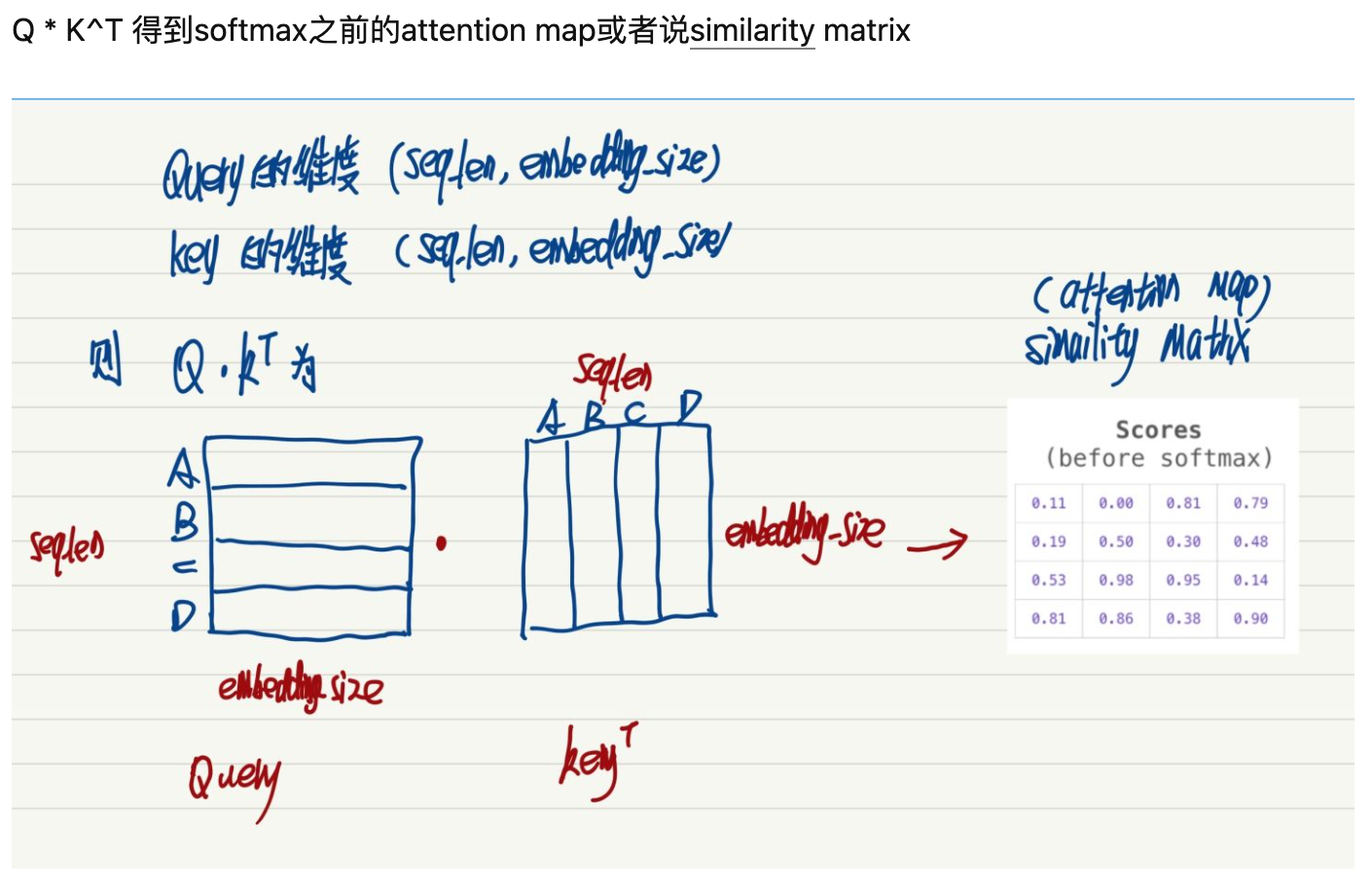
上述过程就是最核心的self-attention机制。可以看到,最后得到一个4*4的矩阵,所得分数也代表着某字与其他字的关系。
我们有个任务是类似于生成式任务,需要在预测B的时候只能看到A的信息;在预测C的时候只能看到A,B的信息;在生成D的时候只能看到A、B、C的信息。
这里我们让attention矩阵的上三角元素为0就可以得到。
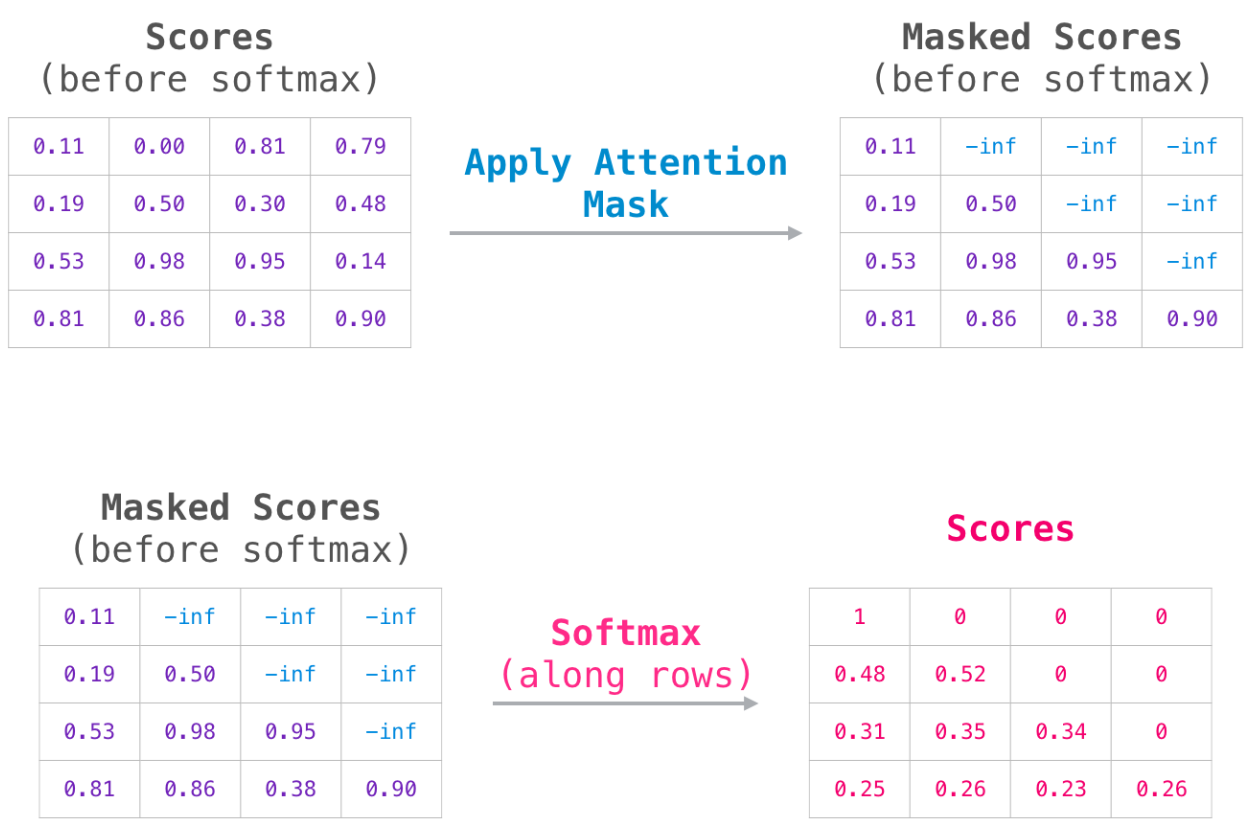
以如下的任务为例 。attention矩阵✖️ Value。这个过程介绍的很清楚。
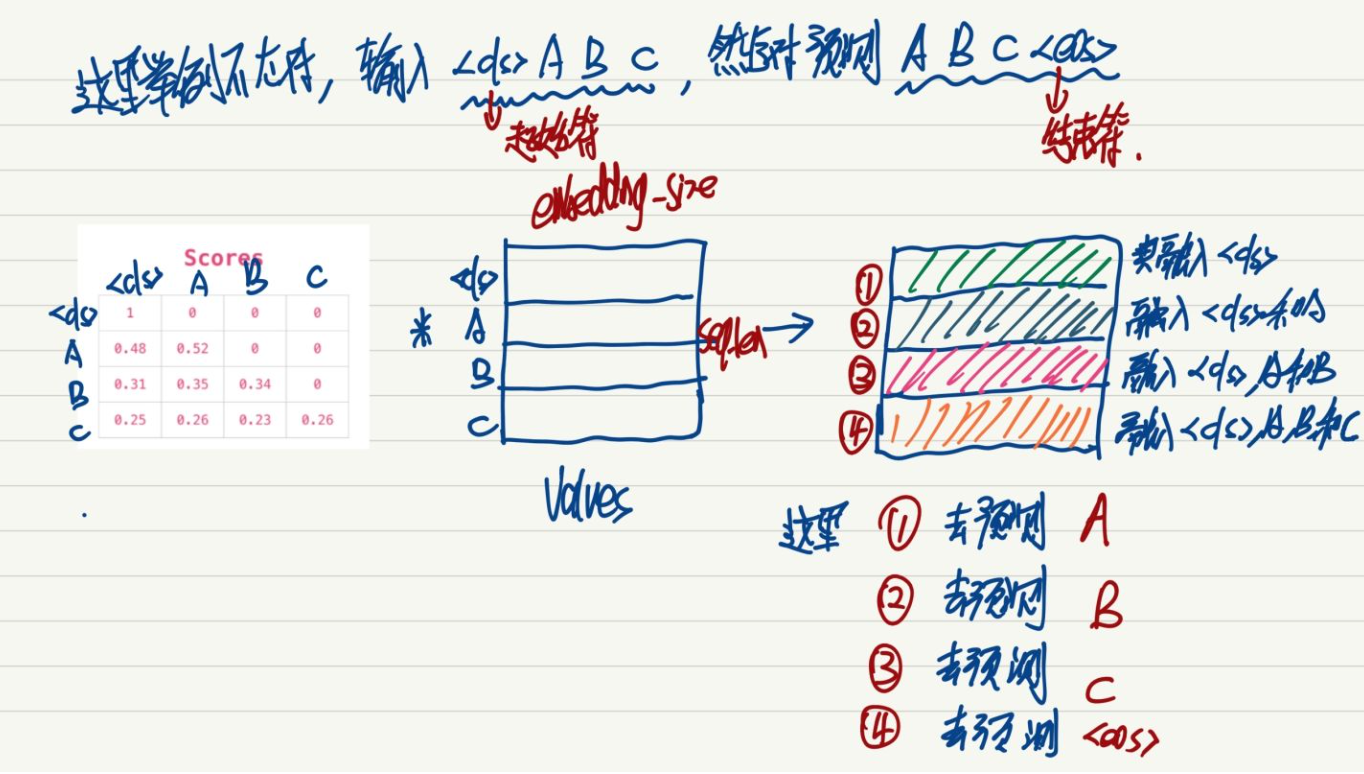
(自注 这个图也解释了业务中left-to-right有效的原因)
然后问题就来了,Bert中mask不就是mask掉一个字,让上下文来预测这个词吗?那我们把attention矩阵的对角线元素为0不就相当于看不到自己了吗?
很简单高效啊 ,一顿操作猛如虎,loss变0了 ,很明显发生了泄漏。
然后,我们反思理解了原因,其实Bert就是把这个词给<mask>掉预测这个词是什么,再往里面探本质是要学习一个attention map或者说similarity matrix,学习<mask>的单词和其他单词的相似性,我们让对角线元素为0的做法犯了两个错误:第一个 自己和自己的相似性肯定是最大的,这样做相当于摒弃了自己的信息,完全让别的单词的信息来预测自己;第二个 本质上的错误是完全的信息泄露,本质上就是为了得到一个符合现实情况的attention map或者similarity matrix,好家伙,这么做相当于把数据信息全部泄露完了,模型根本不用学习这个词和其他词的相似性了,你直接把真实的相似性喂入模型了。
以上,Bert的<mask>的方式可不是简单的让模型看不到自己的信息,本质上就是为了学习<mask>的词和其他单词的相似性。有时候太想当然了就会犯错。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号